Chapter 4. Cool Sysadmin Tools and Tips
Hacks 29–45: Introduction
Behind the calm, collected exterior of the seasoned system administrator is a mad scientist who lives and breathes only to be the first to discover the next esoteric hack that will provide information, or a way to act on it, that was previously unknown to all but a very small contingent of tireless caffeine-swigging hackers.
The reason for this unquenchable thirst goes beyond bragging rights to something more practical than you might imagine: efficiency. If there’s a way to do something better, faster, or in a way that doesn’t require any human intervention, the system administrator will be on constant lookout for a way to implement that solution.
In this chapter, we’re going to take a look at some tools and techniques that we hope are new to most readers, and that will greatly enhance your productivity. Whether it’s a desktop shortcut for connecting to your hosts, a way to run commands on multiple hosts at the same time, or a way to type fewer commands at the command line or fewer characters in Vim, we’ll show you the tools and techniques that will enable you to cross the border from system serf to Bitmaster General in no time.
Technical prowess is great, but “soft skills” such as communicating with people and multitasking count for more and more in today’s competitive job market. For that reason, we’ll also have a look at hacking the softer side of system administration, covering areas ranging from time management to talking to management!
Execute Commands Simultaneously on Multiple Servers
Run the same command at the same time on multiple systems, simplifying administrative tasks and reducing synchronization problems.
If you have multiple servers with similar or identical configurations (such as nodes in a cluster), it’s often difficult to make sure the contents and configuration of those servers are identical. It’s even more difficult when you need to make configuration modifications from the command line, knowing you’ll have to execute the exact same command on a large number of systems (better get coffee first). You could try writing a script to perform the task automatically, but sometimes scripting is overkill for the work to be done. Fortunately, there’s another way to execute commands on multiple hosts simultaneously.
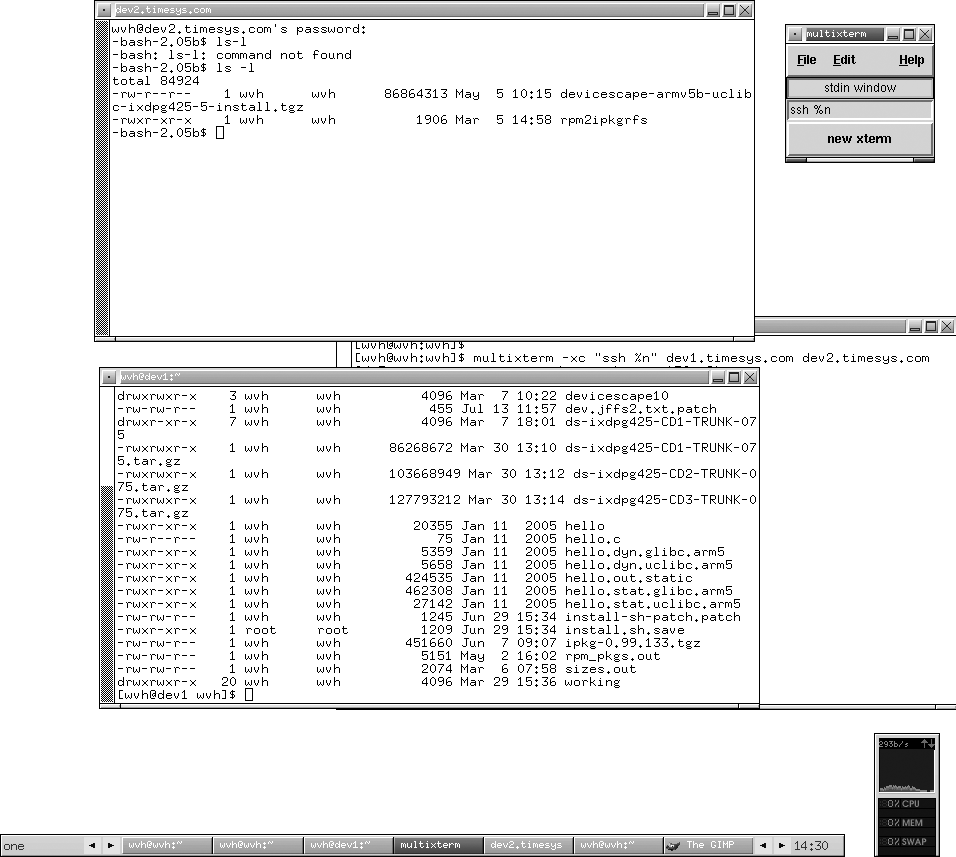
A great solution for this problem is an excellent tool called multixterm, which enables you to simultaneously open xterms to any number of systems, type your commands in a single central window and have the commands executed in each of the xterm windows you’ve started. Sound appealing? Type once, execute many—it sounds like a new pipelining instruction set.
multixterm is available from http://expect.nist.gov/example/multixterm.man.html, and it requires expect and tk. The most common way to run multixterm is with a command like the following:
$multixterm -xc "ssh %n"host1 host2
This command will open ssh connections to host1 and host2 (Figure 4-1). Anything typed in the area labeled “stdin window” (which is usually gray or green, depending on your color scheme) will be sent to both windows, as shown in the figure.
As you can see from the sample command, the –xc option stands for execute command, and it must be followed by the command that you want to execute on each host, enclosed in double quotation marks. If the specified command includes a wildcard such as %n, each hostname that follows the command will be substituted into the command in turn when it is executed. Thus, in our example, the commands ssh host1 and ssh host2 were both executed by multixterm, each within its own xterm window.
See Also
man multixterm“Enable Quick telnet/SSH Connections from the Desktop” [Hack #41]
“Disconnect Your Console Without Ending Your Session” [Hack #34]
—Lance Tost
Collaborate Safely with a Secured Wiki
Get out of the business of coding, supporting, debugging, and maintaining project collaboration sites by using a tool that allows users to create their own sites.
If you’re a busy webmaster trying to perform systems work, the last thing you need is yet another user coming to you with a request to build and host another web site or to install yet another content management solution. Instead, promote a Wiki solution that can be up and running in seconds, ready for the user to create and edit content with no further help needed from you.
Wikis evolved around the idea that content can be editable by anyone who happens upon the site and sees a mistake or has something to add. Webmasters and system administrators alike were wary of this concept, which sounded like an idea just waiting to be completely abused by spammers, digivandals, and the like. If you last looked at Wiki solutions when the buzzword was fresh off the front page of Slashdot and wrote them off as unmanageable or as security issues waiting to happen (like I did), I urge you to have another look.
MediaWiki is the powerhouse Wiki application that runs the http://wikipedia.com web site. Since Wikipedia runs the most visible Wiki site in the world and prides itself on being a resource for the people by the people, what better endorsement do you need for a Wiki application?
Wikis need not be unsecured free-for-alls. Nowadays, you can configure MediaWiki to authenticate to your internal LDAP server, completely disallow anonymous edits, and greatly restrict the damage that can be done to your Wiki site. In addition, MediaWiki makes it very easy both to track changes to the pages of their sites, and to revert to older copies of the pages.
So why use a Wiki if you’re just going to lock it down? Wikis make wonderful content management solutions, for one fundamental reason: they make absolutely no assumptions about the purpose of your site. Many of the LAMP-based, open source content management solutions are built around the concept of a news distribution site first—extensions to do everything else, from blogging to forums and weather to file repositories, are added later, often by members of the respective user communities. If you’re not planning to run a news site, you wind up having to find some hack to make your content management site act the way you want. If you use extensions to make your site work, you can’t just upgrade right away and assume everything will still function correctly.
I’ve used dozens of open source content management solutions and, depending on your needs, you’ll probably find many of them to be adequate. But if you support users in academia, R&D, or internal departments, each project group may have different needs. A simple framework that puts the power to structure and format the content in the hands of the content creators and users is a powerful tool, and the ability to restrict access and edits in a number of ways will give both you and your users peace of mind. If they want a “wide open” site, and you allow for that, that’s no problem. But if you have other security requirements, chances are that with MediaWiki you can implement them easily.
MediaWiki allows you to authenticate to a backend LDAP server or database connection, and there are patches available to rely on other authentication methods available in your environment. In addition, you can opt to restrict access such that only registered and logged-in users can edit pages, create a more open site where anyone can edit pages, or disable registration altogether to create a site for internal staff documentation.
Installing MediaWiki
Another nice benefit of MediaWiki is that it’s a breeze to install. It does require PHP, and its creators strongly suggest using MySQL as the backend database. Depending on the features you want to use (for example, image thumbnailing or LDAP authentication), you may need PHP to be compiled against specific libraries, but the requirements to run a simple site are pretty slim.
If you’re hosting your own site (i.e., you have root privileges), installation takes, quite literally, seconds. All you do is untar the distribution into the document root of your web server, and go to the site! MediaWiki knows if it’s your first visit, and prompts you to perform an installation. Once you supply the MySQL administrator password, MediaWiki will create a new user, a new database, and all the necessary tables, which is 90% of the installation process.
If you’re running MediaWiki on a hosted remote server, however, you’re not likely to have a root password or an administrative password for MySQL. In this case, you’ll want to create the MediaWiki database first, and then point the installation at this database to create its tables. Unfortunately, I can’t tell you how to do this, as every hosting service will provide different tools to assist you.
Once the installation has been performed successfully, you’ll be presented with a link to visit your new site.
Configuring MediaWiki
Installing it was easy, but how do you lock this thing down? There’s about a metric ton of documentation available on how to do this, but I’ll summarize some of the features that are of primary importance to administrators.
First and foremost is site access. Many sites haven’t deployed Wikis because they’re under the illusion that they can’t be secured. Not so!
With Version 1.4 of MediaWiki, it’s possible to use the configuration file and/or a few SQL statements to change the functions available to different types of users. Version 1.5, on the other hand, has quite a robust collection of potential roles that users can play, implemented via user groups. We’ll work with Version 1.5 here, because it’ll likely be in its final form by the time this goes to press.
I’m working with 1.5rc4, which can be managed largely in a browser. There are separate pages for adding, deleting, and blocking users. There is also a page for changing the groups to which users belong, which will affect the rights they have when they visit your site. In addition, there are plug-ins available to help you correlate users with all the known IP addresses used by them and perform other functions not available in the main distribution.
However, there isn’t yet an interface for changing the rights for a group, or adding/deleting groups. For those tasks, you’ll need to have shell access to the web server, or you’ll need to create a local copy of the LocalSettings.php file, edit it, and copy it back into place to make the changes take effect. The file is simple to edit, and the documentation for making the changes is more than adequate, but I’ll go over examples of one or two quick changes you might want to make.
If you just want to change the group a user is associated with, you can log in as an administrative user and go to the Special Pages link. At the bottom of the screen you’ll see Restricted special pages that are listed only when the admin is logged in. This section contains the link to the user rights management page, which is currently just an interface to change the group memberships of specific users.
If you want to create a group, you’ll need to edit LocalSettings.php and set up the rights available to the group. To see how the default groups are set up, check the documentation or open up the includes/DefaultSettings.php file in your install directory. Here are the lines you would add to LocalSettings.php to add a group called newgroup with permission to read and edit but not to delete:
$wgGroupPermissions['newgroup']['edit'] = true; $wgGroupPermissions['newgroup']['read'] = true; $wgGroupPermissions['newgroup']['delete']= false;
As you can see, there’s no explicit “create group” function. Assigning rights to a nonexistent group, as I’ve done here, will cause the group to be created, and it will be listed as an available group the next time you go to the user rights page.
Keep in mind that there are global settings as well, for the all group (represented in the configuration as *). Here are a few default settings for that group from the DefaultSettings.php file:
$wgGroupPermissions['*' ]['createaccount'] = true; $wgGroupPermissions['*' ]['read'] = true; $wgGroupPermissions['*' ]['edit'] = true;
If you want to override these settings, just place similar lines in the LocalSettings.php file, setting the appropriate permissions to true or false as desired. The LocalSettings.php file overrides any corresponding settings that may be found in the DefaultSettings.php file.
This model gives you the flexibility to, for example, disable anonymous users from creating accounts at all or allow them only to read, and to require users to log in to edit anything. There are also additional rights you can give users to make them quasi-administrators, allowing them to create accounts for other users, delete files, and roll back bad edits.
Getting Started: Data Structure
Once user access is out of the way, probably the most important decisions you’ll make in running your Wiki have to do with how the content on your site will be structured and how your content best maps to the organizational elements available to you in MediaWiki. There are many useful tools you can use, and all of them are fairly generic—again making no assumptions about the purpose of the site.
There are many ways to use the various organizational elements. If you have just one project group, they can have their own Wiki devoted to their project. However, you could potentially have several projects share a single Wiki by providing separate namespaces on the site. A namespace is the highest-level data element provided in MediaWiki. Within the namespaces are categories, that the project maintainers themselves can use to break up their sites into various pieces that make sense for their needs.
Lest you think the pages of the site need to be completely static documents, have a look at the Templates feature of MediaWiki, which allows you to embed documents within various pages. This gives you the flexibility to, for example, make your main page nothing but a collection of various other documents placed into the main page. Maintainers of the various templated pages can then update their own content, and changes will be reflected on the main page without affecting templates created by other users.
Edit Your GRUB Configuration with grubby
Save tons of typing (and typos), by using a ready-made tool for editing grub. conf.
A machine that doesn’t boot doesn’t work. And there are many environments in which the grub.conf file supplied with the distribution just doesn’t cut it. Whether you’re using kickstart to install a server farm, or just hacking around with new kernel builds on your web server, you can leave your scripting skills on the back burner by making use of grubby, a simple command-line tool that will edit your kernel definitions for you.
Here’s an example of a very simple kernel definition from a grub.conf file on a Red Hat Enterprise Linux server:
title Red Hat Enterprise Linux AS (2.4.21-32.0.1.EL) root (hd0,0) kernel /vmlinuz-2.4.21-32.0.1.EL ro root=LABEL=/ initrd /nitrd-2.4.21-32.0.1.EL.img
This is a fairly standard stanza referred to in the GRUB documentation as an “OS definition” (owing to GRUB’s ability to boot seemingly any operating system in existence). Occasionally, it becomes necessary to alter the grub.conf file to pass arguments to the kernel at boot time. For example, if you kickstart a server farm and later add serial console connections to the servers, the kernels will not automatically detect the console, and GRUB will not automagically add the arguments necessary to redirect output to the serial terminal device. How to do this is covered in “Use a Serial Console for Centralized Access to Your Systems” [Hack #76] .
This would normally mean hand-editing the grub.conf file to add the arguments—unless you happen to know about grubby. Here’s the command, run as root, that you would use to add the requisite arguments to all kernels to allow for console redirection:
# grubby–-update-kernel=ALL --args=console=ttyS0,9600The ALL keyword works with several flags and, in this case, it will add the arguments to every kernel line in the configuration file. There’s also a DEFAULT keyword that will alter only the kernel line of the default kernel, as per the grub.conf
default parameter.
grubby can also alter options to the grub bootloader itself. Using the following commands, you can add a new kernel to the grub.conf file and make it the kernel that grub will boot by default:
#grubby –-add-kernel=/boot/vmlinuz-2.4.21-new –-make-default#grubby –-set-default=/boot/vmlinuz-2.4.21-32.0.1.ELsmp
I used the –-make-default flag to set the vmlinuz-2.4.21-new kernel to be the default. If you tell grubby to change the default kernel to one that the config file doesn’t know about, it’ll try to do it, fail, remove the “default” parameter from your config file entirely, and not complain about it one bit. Since I failed to put my new kernel in place, in the second command, I’ve reset the default kernel back to one that was defined earlier by using the –set-default parameter.
So how has this saved you any typing? Changing a default kernel is as simple as changing a single digit in the grub.conf file, right? Well, yes, assuming that you’re doing this on a single machine. However, if you need to run a scripted update to your grub.conf file on all the machines you manage or you’re altering grub.conf during an automated installation to make a customized kernel the default, I’d much rather use grubby than sed, awk, vi, ed, and/or Perl to do the work. In these cases, it does save you some typing, not to mention saving you from reinventing the wheel!
Give Your Tab Key a Workout
Use bash programmable completion to autocomplete much more than just filenames.
Tab completion in the bash shell isn’t new, and I don’t know how I’d live without it. Being able to type, for example, ls fo<tab><tab> and get a list of five or six files that start with “fo” can be very handy. Got a long script name you always mistype? Just type the first few letters and hit Tab twice, and bash will try to complete the name for you. This is a wonderful time-saver that I, for one, sorely miss when I log into other Unix machines where the default shell is csh and tab completion is not set up by default (causing control characters to appear on the command line instead of nice, clean, filenames).
In bash v2.04, “programmable” completion was introduced into the shell. This lets you add strange and wonderful bits of goodness to your bash initialization routines (usually found in ~/.bashrc and ~/.bash_profile).
Tip
Your bash initialization routines are dependent on how your shell environment is set up—bash can use a global /etc/bashrc, a ~/.bash_profile, a ~/.bashrc, a ~/.profile, and I believe a ~/.login file to get its initialization info.
Here’s quick example:
complete -f -X '!*.@(sxw|stw|sxg|sgl|doc|dot|rtf|txt|htm|html|odt|\ ott|odm)' oowriter
This looks pretty cryptic, but really it’s quite simple. complete is a bash built-in keyword that causes the shell to try to complete the text before the cursor on the command line. The -f flag means we’ll be looking to complete a filename. The -X flag specifies that what follows is a pattern to use in performing the match. Since the shell is actually parsing the entire line, it’s important to always quote your pattern to make sure no shell expansion takes place, causing odd things to happen when you hit your Tab key.
The pattern itself can be broken down and looked at this way:
!*.@(extension)The leading exclamation point, in this context, says that when performing filename completion, we’ll be removing things that do not match this pattern. The string *.@(extension) means “anything, followed by a dot, followed by exactly one occurrence of any of the listed extensions” (here, sxw, stw, sxg, and so on). The @ character is a bash extended globbing character that means, “match exactly one occurrence of the pattern.” The | characters in our list of extensions are logical “or” separators. If any match, they’ll be included in the file listing generated by hitting the Tab key twice.
The last word on the line (in this case, oowriter) specifies the command to which all the stuff on that line applies. In other words, this complete line won’t be touched unless the command being run is oowriter.
You can write thousands of these lines if you want, but it would likely take you forever to think of all the things you’d want to complete, get all the regex patterns right, and then debug the whole thing to make sure only the right filenames are returned. Alternatively, you could just download a preconfigured file put together by a fine fellow named Ian MacDonald, creator of the "bash programmable completion” package, available at http://www.caliban.org/bash/index.shtml#completion. The package consists mostly of simple documentation and a file containing a very large collection of bash completion “cheats.” A version I recently downloaded contained over 200 shortcuts!
Many of the shortcuts are very simple file completion patterns that are bound to specific applications, which is more useful than you could ever know. Being able to type tar xvzff<tab><tab> and have only those files with a tar.gz extension returned is wonderful, but shortcuts that complete hostnames after the ssh command (from your known_hosts file) or targets in a Makefile after you type make are truly time-savers for admins who are constantly doing remote administration and building software from source.
The great thing is that the only real dependency is the bash shell itself: the rest of what happens is completely up to you! If you have root access on the local machine, you can create a file under /etc/profile.d called bash_complete. sh, and paste in a bit of code to set up bash completion in a sane way. The code comes straight from the bash distribution’s README file:
bash=${BASH_VERSION%.*}; bmajor=${bash%.*}; bminor=${bash#*.}
if [ "$PS1" ] && [ $bmajor -eq 2 ] && [ $bminor '>' 04 ] \
&& [ -f /etc/bash_completion ]; then # interactive shell
# Source completion code
. /etc/bash_completion
fi
unset bash bmajor bminorThis code does a simple check to make sure the version of bash you’re running supports programmable completion, then checks to see if you’re launching an interactive shell before sourcing the bash programmable completion file.
Putting this code under /etc/profile.d or in your global /etc/bashrc file allows all users on the machine to reap the benefits of bash programmable completion.
If, on the other hand, you want to use this just for yourself or upload it to your shell account at a web host, you can paste the same code from above into your own ~/.bashrc file.
Keep Processes Running After a Shell Exits
Process-control commands such as nohup and disown make it easy for you to start long-running processes and keep them running even after you log out.
Suppose you’re running a troubleshooting or monitoring tool on your server or compiling a very large program, and the process is going to need to run for hours, days, or longer. What if you need that process to keep running even after you’ve logged out or if your shell session ends before you meant it to? You can make this happen with the nohup and disown commands.
When you run a shell session, all the processes you run at the command line are child processes of that shell. If you log out or your session crashes or otherwise ends unexpectedly, SIGHUP (signal to hang up) kill signals will be sent to its child processes to end them too.
You can get around this by telling the process(es) that you want kept alive to ignore SIGHUP signals. There are two ways to do this: by using the nohup (“no hangup”) command to run the command in an environment where it will ignore certain termination signals or by using the bash shell’s disown command to make a specified background job independent of the current shell.
Using nohup to Execute Commands
The nohup command provides a quick and easy mechanism for keeping a process running regardless of whether its parent process is still active. To take advantage of this capability, run your favorite command, preceded by the nohup command:
$nohupcommand
This executes the specified command and keeps it running even if the parent session ends. If you don’t redirect output from this process, both its output and error messages (stdout and stderr) will be sent to a file called nohup.out in the current directory. If this file can’t be created there, it will be created in the home directory of the user that ran the command.
You can monitor what’s being written to nohup.out using the tail command:
$ tail –f ~/nohup.outYou can also explicitly direct the output of your command to a specified file. For example, the following command line runs the specified command in the background, sends its output to a file called my_test_output.txt in your home directory and continues running it even if the parent session ends:
$nohupcommand > ~/my_test_output.txt &
If you don’t want to save the output of the specified command, you can discard it (and not create the nohup.out file) by redirecting output to /dev/null, the Linux bit-bucket:
$nohupcommand>/dev/null &
This runs the command or program in the background, ignores its output by sending it to /dev/null, and continues running it even if the parent session ends.
Tip
If you’ve used nohup to keep a process running after its parent exits, there is no way to reconnect to that process if you subsequently want to shoot it down. However, nohup only protects the process from the SIGHUP signal. You can still terminate it manually using the big kill hammer, kill–9
PID.
Using disown with Background Jobs
If you’re using the bash shell, you can tell an existing process to ignore SIGHUPs by using the shell’s disown built-in command:
$disown -hjobnumber
This tells a job already running in the background to keep running when its parent process shuts down. You can find its job number using the shell’s jobs command. If you use the disown built-in’s -h option, the running job won’t be removed from the jobs table when you disown it, but it will keep running if the current shell ends. You can still reconnect to this process using the standard bash
%job-number mechanism. If you use the disown built-in with no options, the running job will be removed from the jobs table: it will still continue running after you log out, but you won’t be able to reconnect to it.
You can also use the disown command to keep all current background jobs running:
$ disown -arThis tells all running jobs to keep running even if the current shell closes.
See Also
man bashman1 nohup
—Jon Fox
Disconnect Your Console Without Ending Your Session
Start a long-running job at work and connect to it from home or on the road.
Here’s the setup: you’re a Linux systems consultant with a busy schedule. It’s 9 A.M. now, and you’re already an hour into a very large database installation at one site, but you have to be at another site in about an hour. The build will never finish in time for you to thoroughly test it, create the developer databases, and set up security restrictions before you leave. What do you do?
One solution, of course, is to talk to your client and tell him you’ll be back later to finish up. Another solution, however, may be to start the job in a screen session and log in later from wherever you happen to be to finish up. Lest you think that this will involve building yet another piece of software for your machines, take heart in knowing that screen is usually installed or readily available and prepackaged for whatever distribution you’re running. You can also get more information on screen, including download information, at the GNU screen home page: http://www.gnu.org/software/screen/.
Getting started with screen couldn’t be simpler. Just open your favorite terminal emulator and run the command, like this:
$ screenYou will be greeted with a new shell, running inside a screen session. You can still talk to screen from within the shell, much like you can talk to any console terminal application from within a shell. The key combination you use to send input to screen instead of to the shell running inside the screen session is Ctrl-A. Ctrl-A in screen is similar to the Escape key in vi—it gets the application’s attention so you can tell it what to do. For example, to access a quick command reference in screen, press Ctrl-A followed by ?.
The output should be a list of the many commands you can feed to screen. If you don’t get any output, you can make sure you’re actually in a screen session by invoking screen with the –list flag. You should see something similar to the following:
$ screen –list
There is a screen on:
28820.pts-2.willy (Attached)
1 Socket in /tmp/screen-jonesy.You can see from the output that there is a screen session running, to which we are currently attached. The process ID for this session is 28820, and we’ve been assigned to pseudo-terminal number 2. Now let’s start a job that we can continue later from another location. A simple way to test the functionality is to just open a file in an editor such as Vim. Once you have the file open, press Ctrl-A followed by d, and you will be detached from the
screen session and given back your plain old shell.
At this point, you can leave for your next appointment. Maybe at the next stop you have to do an OS installation, which leaves you with some free time while the packages are installing. Fire up your laptop, SSH to the machine where your screen session is running, and type screen
–r to reattach to the session already in progress. If you have more than one screen session running, type screen –r
pid, where pid is the process ID of the screen session to which you want to attach (discernible from the screen–list output we went over above).
Of course, trying to associate the process ID of a screen session with what’s going on in that session can be a bit daunting, especially if you have lots of sessions running. Instead of doing that, you can name your session something meaningful when you launch it. So, when you launch screen for the purpose of kicking off a long-running software build, just type screen –S make, and the next time you attach to it, you can type screen –r make instead of trying to remember which process ID you need to attach to.
screen Scripting
If you manage more than a few machines, you’ve probably come up with some way of automating the process of connecting to some subset of your service machines at login time, or with a desktop icon, or by some other means that is more automated than manually opening up terminal windows and typing the commands to connect to each host. If you use SSH keys ( Hack #66 in the original Linux Server Hacks), you can create a simple shell script to automate this process for you. Here’s an example shell script:
#!/bin/bash screen -d -m -S svr1 -tjonesy@svr1ssh server1.linuxlaboratory.org screen -d -m -S svr2 -tjonesy@svr2ssh server2.linuxlaboratory.org screen -d -m -S svr3 -tjonesy@svr3ssh server3.linuxlaboratory.org
Save this script to your ~/bin directory, and make sure you make it executable!
What makes this script work well is calling screen with the –d –m flags, which tell screen to start the session, but not to attach to it. Note as well that I’ve used –S to specify a session name, so when I want to attach to, say, svr1, I can just type screen –r svr1. In addition, I’ve used the –t flag to specify a title for my shell, which will show in the titlebar of my terminal emulator to help me keep track of where I am.
Warning
Running the above script will open up SSH sessions to, in this case, server1, server2, and server3. It might be tempting to put this into your shell’s initialization script. Do not do this! In environments where home directories (and therefore, shell init scripts) are shared across hosts, this can create an endless stream of looping SSH sessions.
See Also
Linux Server Hacks, by Rob Flickenger (O’Reilly)
“Use script to Save Yourself Time and Train Others” [Hack #35]
Use script to Save Yourself Time and Train Others
The standard script command ensures repeatability and lends itself nicely to training junior admins.
If you took computer science courses in college, you may have run into the script command before. Professors often want you to hand in the entire contents of an interactive shell session with assignments, so what students often do is simply run script as the first command of their session. That copies all IO taking place in the terminal to a file (named, by default, typescript). When they’re done, they just type exit, and they can then turn in the typescript file to the professor.
script has some uses beyond the classroom as well, though. In some stricter production environments, everything that gets done to non-testing, full-production systems has to be “repeatable”—in other words, scripted, thoroughly tested, and documented to the point that someone in change management, with no training in Unix, can do it. One tool that can be used to create the documentation is script. You’ll still have to script your procedure into oblivion, using the corporate coding standard, but then you can actually record a session where you invoke the tool and hand it over to the change management personnel, so they can see exactly what they need to do, in order.
One extremely cool feature of the script command is that it can output timing information to a separate file. The entire terminal session can then be replayed later using the scriptreplay command, and it will be replayed using the same timing as the original session! This is great for newer users who have a hard time remembering how to perform tasks that you don’t have time to script for them.
Here’s a quick session using the two commands:
$script -t 2> timingScript started, file is typescript $lsDesktop hax hog.sh My Computer ostg src $pwd/home/jonesy $file haxhax: empty $exitexit Script done, file is typescript $scriptreplay timing$lsDesktop hax hog.sh My Computer ostg src $pwd/home/jonesy $file haxhax: empty $exitexit
Using the -t flag tells the script command to output all timing information to standard error, so we redirect that to a file (here, timing) so that we can use it later. We then call scriptreplay, feeding it the timing file. We don’t have to tell it where the actual session output is in this case, because it looks for a file named typescript by default, which also happens to be the default session output file for the script command.
Note that every keystroke is recorded, so if you mess up and hit backspace to delete a few characters, that’ll show up in the replay of the session! Also note that replaying a session is only guaranteed to work properly on the terminal where the original session output file was created.
If you want a more “real-time” approach to showing someone how to get things done, there’s another way script can help. Create a named pipe and redirect all output to the pipe. Someone else, logged in remotely, can then cat the pipe and see what’s going on while it’s happening.
Here’s how it works. First, create a named pipe with mkfifo:
$mkfifoout
Then run script with the -f flag, which will flush all output to your pipe on every write. Without that flag, things won’t work. The last argument to script is the file to which the output should be sent:
$script -fout
You’re now in a session that looks and acts completely normal, but someone else can log in from elsewhere and run the following command to watch the action:
$catout
Everything will be shown to that user as it happens. This is a little easier than remembering how to set up multi-user screen sessions!
See Also
“Disconnect Your Console Without Ending Your Session” [Hack #34]
Install Linux Simply by Booting
Let server daemons that are already running in your environment and a simple PXE configuration make installs as easy as powering on the target hosts.
Many distributions have some form of automated installation. SUSE has AutoYaST, Debian has Fully Automated Install (FAI), Red Hat has kickstart, and the list goes on. These tools typically work by parsing a configuration file or template, using keywords to tell the installation program how the machine will be configured. Most also allow for customized scripts to be run to account for anything the automated installation template hasn’t accounted for.
The end result is a huge time savings. Though an initial time investment is required to set up and debug a template and any other necessary tools, once this is done, you can use a single template file to install all machines of the same class, or quickly edit a working template file to allow for the automated installation of a “special case” target host. For example, a template for a web server can quickly be edited to take out references to Apache and replace them with, say, Sendmail.
The only downside to automated installations is that, without any supporting infrastructure in place to further automate things, you have to boot to a CD or some other media and issue a command or two to get the installation process rolling. It would really be wonderful if installing Linux were as simple as walking through the machine room (or lab, or anyplace else where there are a lot of target hosts that need installing), powering on all the new machines, and walking away. Let’s have a look at how this (and more!) can be accomplished.
In my examples, I’ll be using the Red Hat/Fedora kickstart mechanism for my automated installations, but other tools can accomplish similar if not identical results.
Preparatory Steps
The list of components you’ll need to configure may sound slightly intimidating, but it’s much easier than it looks, and once you get it to work once, automating the setup process and replicating the ease of installation is a breeze. Before you do anything, though, make sure that the hosts you want to install have network cards that support a Preboot eXecution Environment (PXE). This is a standard booting mechanism supported by firmware burned into the network card in your server. Most server-grade network cards, and even recent desktop network cards, support PXE. The way to check is generally to enter the BIOS settings and see if there’s an option to enable PXE, or to carefully watch the boot messages to see if there are settings there for PXE booting. On a lot of systems, simply hitting a function key during bootup will cause the machine to boot using PXE.
Configuring DHCP.
When you know for sure that your machines support PXE, you can move on to configuring your DHCP/BOOTP server. This service will respond to the PXE broadcast coming from the target node by delivering an IP address, along with the name of a boot file and the address of a host from which the boot file can be retrieved. Here’s a typical entry for a target host:
host pxetest {
hardware ethernet 0:b:db:95:84:d8;
fixed-address 192.168.198.112;
next-server 192.168.101.10;
filename "/tftpboot/linux-install/pxelinux.0";
option ntp-servers 192.168.198.10, 192.168.198.23;
}All the lines above are perfectly predictable in many environments. Only the lines in bold type are specific to what we’re trying to accomplish. Once this information is delivered to the client, it knows what filename to ask for and which server to ask for that file.
At this point, you should be able to boot the client, tell it to PXE boot, and see it get an IP address and report to you what that address is. In the event that you have a PXE implementation that tells you nothing, you can check the DHCP server logs for confirmation. A successful DHCP request and response will look something like this in the logs:
Aug 9 06:05:55 livid dhcpd: [ID 702911 daemon.info] DHCPDISCOVER from 00: 40:96:35:22:ff (jonesy-thinkpad) via 172.16.1.1 Aug 9 06:05:55 livid dhcpd: [ID 702911 daemon.info] DHCPOFFER on 192.168. 198.101 to 00:40:96:35:22:ff (jonesy-thinkpad) via 192.168.198.100
Configuring a TFTP server.
Once the machine is able to get an IP address, the next thing it will try to do is get its grubby RJ45 connectors on a boot file. This will be housed on a TFTP server. On many distributions, a TFTP server is either included or readily available. Depending on your distribution, it may or may not run out of inetd or xinetd. If it is run from xinetd, you should be able to enable the service by editing /etc/xinetd.d/in.tftpd and changing the disable option’s value to no. Once that’s done, restarting xinetd will enable the service. If your system runs a TFTP server via inetd, make sure that an entry for the TFTP daemon is present and not commented out in your /etc/inted.conf file. If your system runs a TFTP server as a permanent daemon, you’ll just have to make sure that the TFTP daemon is automatically started when you boot your system.
Next, we need to create a directory structure for our boot files, kernels, and configuration files. Here’s a simple, no-frills directory hierarchy that contains the bare essentials, which I’ll go over in a moment:
/tftpboot/ linux-install/ pxelinux.0 vmlinuz initrd.img pxelinux.cfg/ default
First, run this command to quickly set up the directory hierarchy described above:
$ mkdir -p /tftpboot/linux-install/pxelinux.cfgThe -p option to mkdir creates the necessary parent directories in a path, if they don’t already exist. With the directories in place, it’s time to get the files! The first one is the one our client is going to request: pxelinux.0. This file is a simple bootloader meant to enable the system to do nothing more than grab a configuration file, from which it learns which kernel and initial ramdisk image to grab in order to continue on its way. The file itself can be obtained from the syslinux package, which is readily available for almost any distribution on the planet. Grab it (or grab the source distribution), install or untar the package, and copy the pxelinux.0 file over to /tftpboot/linux-install/pxelinux.0.
Once that file is delivered to the client, the next thing the client does is look for a configuration file. It should be noted here that the syslinux-supplied pxelinux.0 always looks for its config file under pxelinux.cfg by default. Since our DHCP server only specifies a boot file, and you could have a different configuration file for every host you PXE boot, it looks for the config file using the following formula:
It looks for a file named using its own MAC address, in all-uppercase hex, prefixed by the hex representation of its ARP type, with all fields separated by dashes. So, using our example target host with the MAC address 00:40:96:35:22:ff, the file would be named 01-00-40-96-35-22-FF. The 01 in the first field is the hex representation of the Ethernet ARP type (ARP type 1).
Next, it looks for a file named using the all-uppercase hex representation of the client IP address. The syslinux project provides a binary called gethostip for figuring out what this is, which is much nicer than doing it in your head. Feeding my IP address to this command returns
COA8C665.If neither of these files exists, the client iterates through searching for files named by lopping one character off the end of the hex representation of its IP address (COA8C66, COA8C6, COA8C, COA8…you get the idea).
If there’s still nothing, the client finally looks for a file named default. If that’s not there, it fails to proceed.
In our simple test setup, we’ve just put a file named default in place, but in larger setups, you can set up a configuration file for each class of host you need to install. So, for example, if you have 40 web servers to install and 10 database servers to install, you don’t need to create 50 configuration files—just create one called web-servers and one called db-servers, and make symlinks that are unique to the target hosts, either by using gethostip or by appending the ARP type to the MAC address, as described above.
Whichever way you go, the configuration file needs to tell the client what kernel to boot from, along with any options to pass to the kernel as it boots. If this sounds familiar to you, it should, because it looks a lot like a LILO or GRUB configuration. Here’s our default config file:
default linux label linux kernel vmlinuz append ksdevice=eth0 load_ramdisk=1 prompt_ramdisk=0 network ks=nfs:myserver:/kickstart/Profiles/pxetest
I’ve added a bunch of options to our kernel. The ksdevice and ks= options are specific to Red Hat’s kickstart installation mechanism; they tell the client which device to use for a network install (in the event that there is more than one present) and how and where to get the kickstart template, respectively. From reading the ks= option, we can see that the installation will be done using NFS from the host myserver. The kickstart template is /kickstart/Profiles/pxetest.
The client gets nowhere, however, until it gets a kernel and ramdisk image. We’ve told it to use vmlinuz for the kernel and the default initial ramdisk image, which is always initrd.img. Both of these files are located in the same directory as pxelinux.0. The files are obtained from the distribution media that we’re attempting to install. In this case, since it’s Red Hat, we go to the isolinux directory on the boot CD and copy the kernel and ramdisk images from there over to /tftpboot/linux-install.
Getting It Working
Your host is PXE-enabled; your DHCP server is configured to deliver the necessary information to the target host; and the TFTP server is set up to provide the host with a boot file, a configuration file, a kernel, and a ramdisk image. All that’s left to do now is boot! Here’s the play-by-play of what takes place, for clarity’s sake:
You boot and press a function key to tell the machine to boot using PXE.
The client broadcasts for, and hopefully gets, an IP address, along with the name and location of a boot file.
The client contacts the TFTP server, asks for the boot file, and hopefully gets one.
The boot file launches and then contacts the TFTP server again for a configuration file, using the formula we discussed previously. In our case it will get the one named default, which tells it how to boot.
The client grabs the kernel and ramdisk image specified in default and begins the kickstart using the NFS server specified on the kernel
appendline.
Quick Troubleshooting
Here are some of the problems you may run into and how to tackle them:
If you get TFTP ACCESS VIOLATION errors, these can be caused by almost anything. However, the obvious things to check are that the TFTP server can actually access the file (using a TFTP client) and that the DHCP configuration for the target host lists only a
filenameparameter specifyingpxelinux.0, and doesn’t list the BOOTPbootfile-nameparameter.If you fail to get a boot file and you get a “TFTP open timeout” or some other similar timeout, check to make sure the TFTP server is allowing connections from the client host.
If you fail to get an IP address at all, grep for the client’s MAC address in the DHCP logs for clues. If you don’t find it, your client’s broadcast packets aren’t making it to the DHCP server, in which case you should look for a firewall/ACL rule as a possible cause of the issue.
If you can’t seem to get the kickstart configuration file, make sure you have permissions to mount the NFS source, make sure you’re asking for the right file, and check for typos!
If everything fails and you can test with another identical box or another vmlinuz, do it, because you might be running into a flaky driver or a flaky card. For example, the first vmlinuz I used in testing had a flaky b44 network driver, and I couldn’t get the kickstart file. The only change I made was to replace vmlinuz, and all was well.
Turn Your Laptop into a Makeshift Console
Use minicom and a cable (or two, if your laptop doesn’t have a serial port) to connect to the console port of any server.
There are many situations in which the ability to connect to the serial console port of a server can be a real lifesaver. In my day-to-day work, I sometimes do this for convenience, so I can type commands on a server’s console while at the same time viewing some documentation that is inevitably available only in PDF format (something I can’t do from a dumb terminal). It’s also helpful if you’re performing tasks on a machine that is not yet hooked up to any other kind of console or if you’re on a client site and want to get started right away without having to learn the intricacies of the client’s particular console server solution.
Introducing minicom
How is this possible? There’s an age-old solution that’s provided as a binary package by just about every Linux distribution, and it’s called minicom. If you need to build from source, you can download it at http://alioth.debian.org/projects/minicom/. minicom can do a multitude of great things, but what I use it for is to provide a console interface to a server over a serial connection, using a null modem cable (otherwise known as a crossover serial cable).
Actually, that’s a big, fat lie. My laptop, as it turns out, doesn’t have a serial port! I didn’t even look to confirm that it had one when I ordered it, but I’ve found that many newer laptops don’t come with one. If you’re in the same boat, fear not! Available at online shops everywhere, for your serial connection pleasure, are USB-to-serial adapters. Just plug this thing into a USB port, then connect one end of the null modem cable to the adapter and the other end to the server’s serial port, and you’re in business.
With hardware concerns taken care of, you can move on to configuring minicom. A default configuration directory is usually provided on Debian systems in /etc/minicom. On Red Hat systems, the configuration files are usually kept under /etc and do not have their own directory. Customizing the configuration is generally done by running this command as root:
# minicom –sThis opens a text-based interface where you can make the necessary option changes. The configuration gets saved to a file called minirc.dfl by default, but you can use the “Save setup as” menu option to give the configuration a different name. You might want to do that in order to provide several configuration files to meet different needs—the profile used at startup time can be passed to minicom as a lone argument.
For example, if I run minicom -s, and I already have a default profile stored in minicom.dfl, I can, for instance, change the baud rate from the default 9,600 to 115,200 and then save this as a profile named fast. The file created by this procedure will be named minicom.fast, but when I start up I just call the profile name, not the filename, like this:
$ minicom fastOf course, this assumes that a regular user has access to that profile. There is a user access file, named minicom.users, that determines which users can get to which profiles. On both Debian and Red Hat systems, all users have access to all profiles by default.
A slightly simpler way to get a working configuration is to steal it. Here is a barebones configuration for minicom. Though it’s very simple, it’s really the only one I’ve ever needed:
# Machine-generated file - use "minicom -s" to change parameters. pu port /dev/ttyUSB0 pu baudrate 9600 pu bits 8 pu parity N pu stopbits 1 pu minit pu mreset pu mconnect pu mhangup
I included here the options stored to the file by default, even though they’re not used. The unused settings are specific to situations in which minicom needs to perform dialups using a modem. Note in this config file that the serial device I’m using (the local device through which minicom will communicate) is /dev/ttyUSB0. This device is created and assigned by a Linux kernel module called usbserial. If you’re using a USB-to-serial adapter and there’s no indication that it’s being detected and assigned to a device by the kernel, check to make sure that you have this module. Almost every distribution these days provides the ubserial module and dynamically loads it when needed, but if you build your own kernels, make sure you don’t skip over this module! In your Linux kernel configuration file, the option CONFIG_USB_SERIAL should be set to y or m. It should not be commented out.
The next setting is the baudrate, which has to be the same on both the client and the server. In this case, I’ve picked 9,600, not because I want to have a turtle-slow terminal, but because that’s the speed configured on the servers to which I usually connect. It’s plenty fast enough for most things that don’t involve tailing massive logfiles that are updated multiple times per second.
The next three settings dictate how the client will be sending its data to the server. In this case, a single character will be eight bits long, followed by no parity bit and one stop bit. This setting (referred to as “8N1”) is by far the most common setting for asynchronous serial communication. These settings are so standard that I’ve never had to change them in my minicom.conf file—in fact, the only setting I do change is the baud rate.
Testing It
Once you have your configuration in place, connect your null modem or USB-to-serial adapter to your laptop and connect the other end to the serial console port on the server. If you’re doing this for the first time, the serial console port on the server is a 15-pin male connection that looks a lot like the male version of a standard VGA port. It’s also likely to be the only place you can plug in a null modem cable! If there are two of them, generally the one on the top (in a vertical configuration) or on the left (in a horizontal configuration) will be ttyS0 on the server, and the other will be ttyS1.
After you’ve physically connected the laptop to the server, the next thing to do is fire up a terminal application and launch minicom:
$ minicomThis command will launch minicom with its default configuration. Note that on many systems, launching the application alone doesn’t do much: you have to hit Enter once or twice to get a login prompt returned to you.
Troubleshooting
I’ve rarely had trouble using minicom in this way, especially when the server end is using agetty to provide its of the communication, because agetty is pretty forgiving and can adjust for things like seven-bit characters and other unusual settings. In the event that you have no output or your output looks garbled, check to make sure that the baud rate on the client matches the baud rate on the server. Also make sure that you are, in fact, connected to the correct serial port! On the server, try typing the following to get a quick rundown of the server settings:
$ grep agetty /etc/inittab
co:2345:respawn:/sbin/agetty ttyS0 9600 vt100-nav
$This output shows that agetty is in fact running on ttyS0 at 9600 baud. The vt100-nav option on the end is put there by the Fedora installation program, which sets up your inittab entry by default if something is connected to the console port during installation. The vt100-nav option sets the TERM environment variable. If you leave this setting off, most Linux machines will just set this to vt100 by default, which is generally fine. If you want, you can tell minicom to use an alternate terminal type on the client end with the -t flag.
If you’re having trouble launching minicom, make sure you don’t have restrictions in place in the configuration file regarding who is allowed to use the default profile.
Usable Documentation for the Inherently Lazy
Web-based documentation is great, but it’s not very accessible from the command line. However, manpages can be with you always.
I know very few administrators who are big fans of creating and maintaining documentation. It’s just not fun. Not only that, but there’s nothing heroic about doing it. Fellow administrators aren’t going to pat you on the back and congratulate you on your wicked cool documentation. What’s more, it’s tough to see how end users get any benefit when you document stuff that’s used only by administrators, and if you’re an administrator writing documentation, it’s likely that everyone in your group already knows the stuff you’re documenting!
Well, this is one way to look at it. However, the fact is that turnover exists, and so does growth. It’s possible that new admins will come on board due to growth or turnover in your group, and they’ll have to be taught about all of the customized tools, scripts, processes, procedures, and hacks that are specific to your site. This learning process is also a part of any new admin’s enculturation into the group, and it should be made as easy as possible for everyone’s benefit, including your own.
In my travels, I’ve found that the last thing system administrators want to do is write documentation. The only thing that might fall below writing documentation on their lists of things they’re dying to do is writing web-based documentation. I’ve tried to introduce in-browser WYSIWYG HTML editors, but they won’t have it. Unix administrators are quite happy using Unix tools to do their work. “Give me Vim or give me death!”
Another thing administrators typically don’t want to do is learn how to use tools like LaTeX, SGML, or groff to create formal documentation. They’re happiest with plain text that is easily typed and easily understood by anyone who comes across the raw file. Well, I’ve found a tool that enables administrators to create manpages from simple text files, and it’s cool. It’s called txt2man.
Of course, it comes with a manpage, which is more than enough documentation to use the tool effectively. It’s a simple shell script that you pass your text file to, along with any options you want to pass for a more polished end result, and it spits out a perfectly usable manpage. Here’s how it works.
I have a script called cleangroup that I wrote to help clean up after people who have departed from our department (see “Clean Up NIS After Users Depart” [Hack #77] ). It goes through our NIS map and gets rid of any references made to users who no longer exist in the NIS password map. It’s a useful script, but because I created it myself there’s really no reason that our two new full-time administrators would know it exists or what it does. So I created a new manpage directory, and I started working on my manpages for all the tools written locally that new admins would need to know about. Here is the actual text I typed to create the manpage:
NAME
cleangroup - remove users from any groups if the account doesn't exist
SYNOPSIS
/usr/local/adm/bin/cleangroup groupfile
DESCRIPTION
cleangroup is a perl script used to check each uid found in the group file
against the YP password map. If the user doesn't exist there, the user is
removed from the group.
The only argument to the file is groupfile, which is required.
ENVIRONMENT
LOGNAME You need to be root on the YP master to run this
script successfully.
BUGS
Yes. Most certainly.
AUTHOR
Brian Jones jonesy@linuxlaboratory.orgThe headings in all caps will be familiar to anyone who has read his fair share of manpages. I saved this file as cleangroup.txt. Next, I ran the following command to create a manpage called cleangroup.man:
$ txt2man -t cleangroup -s 8 cleangroup.txt > cleangroup.manWhen you open this manpage using the man command, the upper-left and right corners will display the title and section specified on the command line with the -t and -s flags, respectively. Here’s the finished output:
cleangroup(8) cleangroup(8)
NAME
cleangroup-remove users from any groups if the account doesn't exist
SYNOPSIS
/var/local/adm/bin/beta/cleangroup groupfile
DESCRIPTION
cleangroup is a perl script used to check each uid found in the group
file against the YP password map. If the user doesn't exist there,
the user is removed from the group.
The only argument to the file is groupfile, which is required.
ENVIRONMENT
LOGNAME
You need to be root on nexus to run this script successfully.
BUGS
Yes. Most certainly.
AUTHOR
Brian Jones jonesy@cs.princeton.eduFor anyone not enlightened as to why I chose section 8 of the manpages, you should know that the manpage sections are not completely arbitrary. Different man sections are for different classes of commands. Here’s a quick overview of the section breakdown:
|
1 |
User-level commands such as |
|
2 |
System calls such as |
|
3 |
Library calls such as |
|
4 |
Special files such as fd and fifo |
|
5 |
Configuration files such as ldap.conf and nsswitch.conf |
|
6 |
Games and demonstrations |
|
7 |
Miscellaneous |
|
8 |
Commands normally run by the root user, such as |
Some systems have a section 9 for kernel documentation. If you’re planning on making your own manpage section, try to pick an existing one that isn’t being used, or just work your manpages into one of the existing sections. Currently, man only traverses man
X directories (where X is a single digit), so man42 is not a valid manpage section.
Though the resulting manpage isn’t much different from the text file, it has the advantage that you can actually use a standard utility to read it, and everyone will know what you mean when you say “check out man 8 cleangroup.” That’s a whole lot easier than saying “go to our intranet, click on Documentation, go to Systems, then Linux/Unix, then User Accounts, and click to open the PDF.”
If you think that txt2man can handle only the simplest of manpages, it has a handy built-in help that you can send to itself; the resulting manpage is a pretty good sample of what txt2man can do with just simple text. Run this command (straight from the txt2man manpage) to check it out:
$ txt2man -h 2>&1 | txt2man -TThis sends the help output for the command back to txt2man, and the -T flag will preview the output for you using more or whatever you’ve set your PAGER environment variable to. This flag is also a quick way to preview manpages you’re working on to make sure all of your formatting is correct instead of having to create a manpage, open it up, realize it’s hosed in some way, close it, and open it up again in your editor. Give it a try!
Exploit the Power of Vim
Use Vim’s recording and keyboard macro features to make monotonous tasks lightning fast.
Every administrator, at some point in his career, runs into a scenario in which it’s unclear whether a task can be performed more quickly using the Vim command . (a period) and one or two other keystrokes for every change, or using a script. Often, admins wind up using the . command because they figure it’ll take less time than trying to figure out the perfect regex to use in a Perl, sed, or awk script.
However, if you know how to use Vim’s "recording” feature, you can use on-the-fly macros to do your dirty work with a minimum of keystrokes. What’s more, if you have tasks that you have to perform all the time in Vim, you can create a keyboard macros for those tasks that will be available any time you open your editor. Let’s have a look!
Recording a Vim Macro
The best way to explain this is with an example. I have a file that is the result of the dumping of all the data in my LDAP directory. It consists of the LDIF entries of all the users in my environment.
One entry looks like this:
dn: cn=jonesy,ou=People,dc=linuxlaboratory,dc=org
objectClass: top
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: evolutionPerson
uid: jonesy
sn: Jones
cn: Brian K. Jones
userPassword: {crypt}eRnFAci.Ie2Ny
loginShell: /bin/bash
uidNumber: 3025
gidNumber: 410
homeDirectory: /u/jonesy
gecos: Brian K. Jones,STAFF
mail: jonesy@linuxlaboratory.org
roomNumber: 213
fileas: Jones, Brian K.
telephoneNumber: NONE
labeledURI: http://www.linuxlaboratory.org
businessRole: NONE
description: NONE
homePostalAddress: NONE
birthDate: 20030101
givenName: Brian
displayName: Brian K. Jones
homePhone: 000-000-0000
st: NJ
l: Princeton
c: UStitle: NONE
o: Linuxlaboratory.orgou: Systems GroupThere are roughly 1,000 entries in the file. What I need to do, for every user, is tag the end of every labeledURI line with a value of ~username. This will reflect a change in our environment in which every user has some web space accessible in her home directory, which is found on the Web using the URL http://www.linuxlibrary.org/~username. Some entries have more lines than others, so there’s not a whole heckuva lot of consistency or predictability to make my job easy. You could probably write some really ugly shell script or Perl script to do this, but you don’t actually even have to leave the cozy confines of Vim to get it done. First, let’s record a macro. Step 1 is to type (in command mode) q
n, where n is a register label. Valid register labels are the values 0–9 and a–z. Once you do that, you’re recording, and Vim will store in register n every single keystroke you enter, so type carefully! Typing q again will stop the recording.
Here are the keystrokes I used, including my keystrokes to start and stop recording:
qz
/uid:<Enter>
ww
yw
/labeledURI<Enter>
A
/~
<Esc>
p
qThe first line starts the recording and indicates that my keystrokes will be stored in register z. Next, I search for the string uid: (/uid:), move two words to the right (ww), and yank (Vim-ese for copy) that word (yw). Now I have the username, which I need to paste on the end of the URL that’s already in the file. To accomplish this, I do a search for the labeledURI attribute (/labeledRUI), indicate that I am going to append to the end of the current line (A), type a /~ (because those characters need to be there and aren’t part of the user’s ID), and then hit Esc to enter command mode and immediately hit p to paste the copied username. Finally, I hit q to stop recording.
Now I have a nice string of keystrokes stored in register z, which I can view by typing the following command:
:register z
"z /uid: ^Mwwyw/labeledURI: ^MA/~^[pIf you can see past the control characters (^M is Enter and ^[ is Escape), you’ll see that everything I typed is there. Now I can call up this string of keystrokes any time I want by typing (again, in command mode) @z. It so happens that there are 935 entries in the file I’m working on (I used wc –l on the file to get a count), one of which has been edited already, so if I just place my cursor on the line underneath the last edit I performed and type 934@z, that will make the changes I need to every entry in the file. Sadly, I have not found a way to have the macro run to the end of the file without specifying a number.
Creating Vim Shortcut Keys
I happen to really like the concept of WYSIWYG HTML editors. I like the idea of not having to be concerned with tag syntax. To that extent, these editors represent a decent abstraction layer, enabling me to concentrate more on content than form. They also do away with the need to remember the tags for things such as greater than and less than characters and nonbreaking spaces, which is wonderful.
Unfortunately, none of these shiny tools allows me to use Vim keystrokes to move around within a file. I’m not even asking for search and replace or any of the fancy register stuff that Vim offers—just the simple ability to move around with the h, j, k, and l keys, and maybe a few other conveniences. It took me a long time to figure out that I don’t need to compromise anymore! I can have the full power of Vim and use it to create an environment where the formatting, while not completely invisible, is really a no-brain-required activity.
Here’s a perfect example of one way I use Vim keyboard shortcuts every day. I have to write some of my documentation at work in HTML. Any time my document contains a command that has to be run, I enclose that command in <code></code> tags. This happens a lot, as the documentation I write at work is for an audience of sysadmins like me. The other two most common tags I use are the <p></p> paragraph tags and the <h2></h2> tags, which mark off the sections in the documentation. Here’s a line I’ve entered in my ~/.vimrc file so that entering code tags is as simple as hitting F12 on my keyboard.
imap <F12> <code> </code> <Esc>2F>a
The keyword imap designates this mapping as being active only in insert mode. I did this on purpose, because I’m always already in insert mode when I realize I need the tags. Next is the key I’m mapping to, which is, in this case, F12. After that are the actual tags as they will be inserted. Had I stopped there, hitting F12 in insert mode would put in my tags and leave my cursor to the right of them. Because I’m too lazy to move my cursor manually to place it between the tags, I put more keystrokes on the end of my mapping. First, I enter command mode using the Esc key. The 2F> bit says to search from where the cursor is backward to the second occurrence of >, and then the a places the cursor, back in insert mode, after the > character. I never even realize I ever left insert mode—it’s completely seamless!
Move Your PHP Web Scripting Skills to the Command Line
PHP is so easy, it’s made web coders out of three-year-olds. Now, move that skill to the CLI!
These days, it’s rare to find a person who works with computers of any kind for a living who has not gotten hooked on PHP. The barrier to entry for coding PHP for the Web is a bit lower than coding Perl CGI scripts, if only because you don’t have to compile PHP scripts in order to run them. I got hooked on PHP early on, but I no longer code much for the Web. What I have discovered, however, is that PHP is a very handy tool for creating command-line scripts, and even one-liners on the command line.
Go to the PHP.net function reference (http://www.php.net/manual/en/funcref.php) and check out what PHP has to offer, and you’ll soon find that lots of PHP features of PHP are perfect for command-line programming. PHP has built-in functions for interfacing with syslog, creating daemons, and utilizing streams and sockets. It even has a suite of POSIX functions such as getpwuid and getpid.
For this hack, I’ll be using PHP5 as supplied in the Fedora Core 4 distribution. PHP is readily available in binary format for SUSE, Debian, Red Hat, Fedora, Mandrake, and other popular distributions. Some distros have not yet made the move to PHP5, but they’ll likely get there sooner rather than later.
Obviously, the actual code I use in this hack will be of limited use to you. The idea is really to make you think outside the box, using skills you already have, coding in PHP and applying it to something unconventional like system administration.
The Code
Let’s have a look at some code. This first script is really simple; it’s a simplified version of a script I use to avoid having to use the standard
ldapsearch tool with a whole bunch of flags. For example, if I want to search a particular server in another department for users with the last name Jones and get back the distinguished name (dn) attribute for each of these users, here’s what I have to type:
$ldapsearch -x -hldap.linuxlaboratory.org-b"dc=linuxlaboratory,dc=org" '(sn=Jones)' dn
Yucky. It’s even worse if you have to do this type of search often. I suppose you could write a shell script, but I found that PHP was perfectly capable of handling the task without relying on the ldapsearch tool being on the system at all. In addition, PHP’s universality is a big plus—everyone in my group has seen PHP before, but some of them code in tcsh, which is different enough from ksh or bash to be confusing. Don’t forget that the code you write today will become someone else’s problem if a catastrophic bug pops up while you’re on a ship somewhere sipping margaritas, far from a cell phone tower. Anyway, here’s my script, which I call dapsearch:
#!/usr/bin/php
<?php
$conn=ldap_connect("ldap.linuxlaboratory.org")
or die("Connect failed\n");
$bind = ldap_bind($conn)
or die("Bind failed\n");
$answer = ldap_search($conn, "dc=linuxlaboratory,dc=org", "($argv[1])") ;
$output = ldap_get_entries($conn, $answer);
for ($i=0; $i < count($output); $i++) {
if(!isset($output[$i])) break;
echo $output[$i]["dn"]."\n";
}
echo $output["count"]." entries returned\n";
?>There are a couple of things to note in the code above. On the first line is your everyday “shebang” line, which contains the path to the binary that will run the code, just like in any other shell or Perl script. If you’re coding on your desktop machine for later deployment on a machine you don’t control, you might replace that line with one that looks like this:
#!/usr/bin/env php
This does away with any assumption that the PHP binary is in a particular directory by doing a standard PATH search for it, which can be more reliable.
In addition, you’ll notice that the <?php and ?> tags are there in the shell script, just like they are in web scripts. This can be useful in cases where you have static text that you’d like output to the screen, because you can put that text outside the tags instead of using echo statements. Just close the tag, write your text, then open a new set of tags, and the parser will output your text, then start parsing PHP code when the tags open again.
Also, you can see I’ve simplified things a bit by hard-coding the attribute to be returned (the dn attribute), as well as the server to which I’m connecting. This script can easily be altered to allow for that information to be passed in on the command line as well. Everything you pass on the command line will be in the argv array.
Running the Code
Save the above script to a file called dapsearch, make it executable, and then run it, passing along the attribute for which you want to search. In my earlier ldapsearch command, I wanted the distinguished name attributes of all users with the last name “Jones.” Here’s the (greatly shortened) command I run nowadays to get that information:
$dapsearch sn=Jones
This calls the script and passes along the search filter, which you’ll see referenced in the code as $argv[1]. This might look odd to Perl coders who are used to referencing a lone argument as either @_, $_,or $argv[0]. In PHP, $argv[0] returns the command being run, rather than the first argument handed to it on the command line.
Speaking of the argv array, you can run into errors while using this feature if your installation of PHP doesn’t enable the argv and argc arrays by default. If this is the case, the change is a simple one: just open up your php.ini file (the configuration file for the PHP parser itself) and set register_argc_argv to on.
Enable Quick telnet/SSH Connections from the Desktop
Desktop launchers and a simple shell script make a great combo for quick telnet and SSH connections to remote systems.
Many of us work with a large number of servers and often have to log in and out of them. Using KDE or GNOME’s Application Launcher applet and a simple shell script, you can create desktop shortcuts that enabled you to quickly connect to any host using a variety of protocols.
To do this, create a script called connect, make it executable, and put it in a directory that is located in your PATH. This script should look like the following:
#!/bin/bash
progname='basename $0'
type="single"
if [ "$progname" = "connect" ] ; then
proto=$1
fqdn=$2
shift
shift
elif [ "$progname" = "ctelnet" ]; then
proto="telnet"
fqdn=$1
shift
elif [ "$progname" = "cssh" ]; then
proto="ssh"
fqdn=$1
shift
elif [ "$progname" = "mtelnet" ]; then
proto="telnet"
fqdn=$1
hosts=$*
type="multi"
elif [ "$progname" = "mssh" ]; then
proto="ssh"
fqdn=$1
hosts=$*
type="multi"
fi
args=$*
#
# Uncomment the xterm command and comment out the following if/else/fi
clause
# if you just want to use xterms everywhere
#
# xterm +mb -sb -si -T "${proto}::${fqdn}" -n ${host} -bg black -fg yellow -
e ${proto} ${fqdn} ${args}
#
# Change Konsole to gnome-console and specify correct options if KDE is not
installed
#
if [ "$type" != "multi" ]; then
konsole -T "${proto}::${fqdn}" --nomenubar --notoolbar ${extraargs}
-e ${proto} ${fqdn} ${args}
else
multixterm -xc "$proto %n" $hosts
fiAfter creating this script and making it executable, create symbolic links to this script called cssh, ctelnet, mssh, and mtelnet in that same directory. As you can see from the script, the protocol and commands that it uses are based on the way in which the script was called.
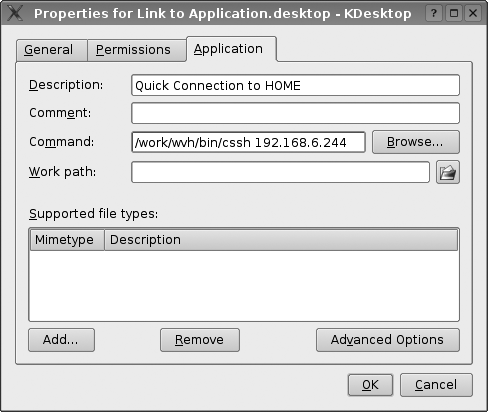
To use this script when you are using KDE, right-click on the desktop and select Create New → File → Link to Application. This displays a dialog like the one shown in Figure 4-2. Enter the name of the script that you want to execute and the host that you want to connect to, and save the link.
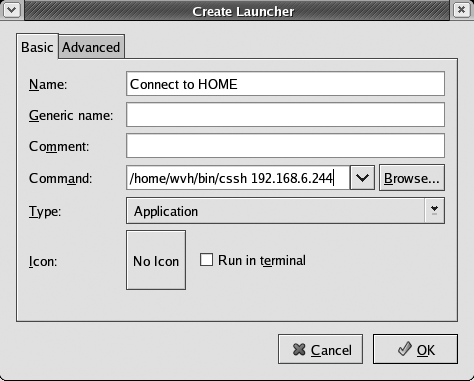
To use this script when you are using GNOME, right-click on the desktop and select Create Launcher. This displays a dialog like the one shown in Figure 4-3. Enter the name of the script that you want to execute and the host that you want to connect to, and save the link.
Using either of these methods, you quickly create desktop shortcuts that allow you to initiate a connection to a remote system by clicking on the link on your desktop—no fuss, no muss!
Speed Up Compiles
While compiling, make full use of all of your computers with a distributed compiling daemon
Many other distribution users make fun of the Gentoo fanboys, because Gentoo users have to spend a lot of time compiling all of their code. And even though these compiles can take hours or days to complete, Gentooists still tout their distribution as being one of the fastest available. Because of their constant need to compile, Gentoo users have picked up a few tricks on making the process go faster, including using distcc to create a cluster of computers for compiling. distcc is a distributed compiling daemon that allows you to combine the processing power of other Linux computers on your network to compile code. It is very simple to set up and use, and it should produce identical results to a completely local compile. Having three machines with similar speeds should make compiling 2.6 times faster. The distcc home page at http://distcc.samba.org has testimonials concerning real user’s experiences using the program. Using this hack, you can get distcc to work with any Linux distribution, which will make compiling KDE and GNOME from scratch quick and easy.
Tip
distcc does not require the machines in your compile farm to have shared filesystems, synchronized clocks, or even the same libraries and headers. However, it is a good idea to make sure you are on the same major version number of the compiler itself.
Before getting started with distcc, first you must know how to perform a parallel make when building code. To perform a parallel make, use the –j option in your make command:
dbrick@rivendell:$ make –j3; make –j3 modulesThis will spawn three child processes that will make maximum use of your processor power by ensuring that there is always something in the queue to be compiled. A general rule of thumb for how many parallel makes to perform is to double the number of processors and then add one. So a single processor system will have –j3 and a dual processor system –j5. When you start using distcc, you should base the –j value on the total number of processors in your compiling farm. If you have eight processors available, then use –j17.
Using distcc
You can obtain the latest version of distcc from http://distcc.samba.org/download.html. Just download the archive, uncompress it, and run the standard build commands:
dbrick@rivendell:$tar -jxvf distcc-2.18.3.tar.bz2dbrick@rivendell:$cd distcc-2.18.3dbrick@rivendell:$./configure && make && sudo make install
You must install the program on each machine you want included in your compile farm. On each of the compiling machines, you need to start the distccd daemon:
root@bree:#distccd –daemon –N15root@moria:#distccd –daemon –N15
These daemons will listen on TCP port 3632 for instructions and code from the local machine (the one which you are actually compiling software for). The –N value sets a niceness level so the distributed compiles won’t interfere too much with local operations. Read the distccd manpage for further options.
On the client side, you need to tell distcc which computers to use for distributed compiles. You can do this by creating an environment variable:
dbrick@rivendell:$export DISTCC_HOSTS='localhostbree moria'
Specify localhost to make sure your local machine is included in the compiles. If your local machine is exceptionally slow, or if you have a lot of processors to distribute the load to, you should consider not including it at all. You can use machine IP addresses in place of names. If you don’t want to set an environment variable, then create a distcc hosts file in your home directory to contain the values:
dbrick@rivendell:$mkdir ~/.distccdbrick@rivendell:$echo "localhostbree moria"> ~/.distcc/hosts
To run a distributed compile, simply pass a CC=distcc option to the make command:
dbrick@rivendell:$ make –j7 CC=distccIt’s that simple to distribute your compiles. Read the manpages for distcc and distccd to learn more about the program, including how to limit the number of parallel makes a particular computer in your farm will perform.
Distribute Compiles to Windows Machines
Though some clever people have come up with very interesting ways to distribute compiles to a Windows machine using Cygwin, there is an easier way to perform the same task using a live CD distribution known as distccKnoppix, which you can download from http://opendoorsoftware.com/cgi/http.pl?p=distccKNOPPIX. Be sure to download the version that has the same major version number of gcc as your local machine.
To use distccKnoppix, simply boot the computer using the CD, note it’s IP address, and then enter that in your distcc hosts file or environment variable as instructed earlier. Happy compiling!
—David Brickner
Avoid Common Junior Mistakes
Get over the junior admin hump and land in guru territory.
No matter how “senior” you become, and no matter how omnipotent you feel in your current role, you will eventually make mistakes. Some of them may be quite large. Some will wipe entire weekends right off the calendar. However, the key to success in administering servers is to mitigate risk, have an exit plan, and try to make sure that the damage caused by potential mistakes is limited. Here are some common mistakes to avoid on your road to senior-level guru status.
Don’t Take the root Name in Vain
Try really hard to forget about root. Here’s a quick comparison of the usage of root by a seasoned vet versus by a junior administrator.
Solid, experienced administrators will occasionally forget that they need to be root to perform some function. Of course they know they need to be root as soon as they see their terminal filling with errors, but running su -root occasionally slips their mind. No big deal. They switch to root, they run the command, and they exit the root shell. If they need to run only a single command, such as a make install, they probably just run it like this:
$ su -c 'make install'This will prompt you for the root password and, if the password is correct, will run the command and dump you back to your lowly user shell.
A junior-level admin, on the other hand, is likely to have five terminals open on the same box, all logged in as root. Junior admins don’t consider keeping a terminal that isn’t logged in as root open on a production machine, because “you need root to do anything anyway.” This is horribly bad form, and it can lead to some really horrid results. Don’t become root if you don’t have to be root!
Building software is a good example. After you download a source package, unzip it in a place you have access to as a user. Then, as a normal user, run your ./configure and make commands. If you’re installing the package to your ~/bin directory, you can run make install as yourself. You only need root access if the program will be installed into directories to which only root has write access, such as /usr/local.
My mind was blown one day when I was introduced to an entirely new meaning of “taking the root name in vain.” It doesn’t just apply to running commands as root unnecessarily. It also applies to becoming root specifically to grant unprivileged access to things that should only be accessible by root!
I was logged into a client’s machine (as a normal user, of course), poking around because the user had reported seeing some odd log messages. One of my favorite commands for tracking down issues like this is ls -lahrt/etc, which does a long listing of everything in the directory, reverse sorted by modification time. In this case, the last thing listed (and hence, the last thing modified) was /etc/shadow. Not too odd if someone had added a user to the local machine recently, but it so happened that this company used NIS+, and the permissions had been changed on the file!
I called the number they’d told me to call if I found anything, and a junior administrator admitted that he had done that himself because he was writing a script that needed to access that file. Ugh.
Don’t Get Too Comfortable
Junior admins tend to get really into customizing their environments. They like to show off all the cool things they’ve recently learned, so they have custom window manager setups, custom logging setups, custom email configurations, custom tunneling scripts to do work from their home machines, and, of course, custom shells and shell initializations.
That last one can cause a bit of headache. If you have a million aliases set up on your local machine and some other set of machines that mount your home directory (thereby making your shell initialization accessible), things will probably work out for that set of machines. More likely, however, is that you’re working in a mixed environment with Linux and some other Unix variant. Furthermore, the powers that be may have standard aliases and system-wide shell profiles that were there long before you were.
At the very least, if you modify the shell you have to test that everything you’re doing works as expected on all the platforms you administer. Better is just to keep a relatively bare-bones administrative shell. Sure, set the proper environment variables, create three or four aliases, and certainly customize the command prompt if you like, but don’t fly off into the wild blue yonder sourcing all kinds of bash completion commands, printing the system load to your terminal window, and using shell functions to create your shell prompt. Why not?
Well, because you can’t assume that the same version of your shell is running everywhere, or that the shell was built with the same options across multiple versions of multiple platforms! Furthermore, you might not always be logging in from your desktop. Ever see what happens if you mistakenly set up your initialization file to print stuff to your terminal’s titlebar without checking where you’re coming from? The first time you log in from a dumb terminal, you’ll realize it wasn’t the best of ideas. Your prompt can wind up being longer than the screen!
Just as versions and build options for your shell can vary across machines, so too can “standard” commands—drastically! Running chown -R has wildly different effects on Solaris than it does on Linux machines, for example. Solaris will follow symbolic links and keep on truckin', happily skipping about your directory hierarchy and recursively changing ownership of files in places you forgot existed. This doesn’t happen under Linux. To get Linux to behave the same way, you need to use the -H flag explicitly. There are lots of commands that exhibit different behavior on different operating systems, so be on your toes!
Also, test your shell scripts across platforms to make sure that the commands you call from within the scripts act as expected in any environments they may wind up in.
Don’t Perform Production Commands “Off the Cuff”
Many environments have strict rules about how software gets installed, how new machines are built and pushed into production, and so on. However, there are also thousands of sites that don’t enforce any such rules, which quite frankly can be a bit scary.
Not having the funds to come up with a proper testing and development environment is one thing. Having a blatant disregard for the availability of production services is quite another. When performing software installations, configuration changes, mass data migrations, and the like, do yourself a huge favor (actually, a couple of favors):
- Script the procedure!
Script it and include checks to make sure that everything in the script runs without making any assumptions. Check to make sure each step has succeeded before moving on.
- Script a backout procedure.
If you’ve moved all the data, changed the configuration, added a user for an application to run as, and installed the application, and something blows up, you really will not want to spend another 40 minutes cleaning things up so that you can get things back to normal. In addition, if things blow up in production, you could panic, causing you to misjudge, mistype, and possibly make things worse. Script it!
The process of scripting these procedures also forces you to think about the consequences of what you’re doing, which can have surprising results. I once got a quarter of the way through a script before realizing that there was an unmet dependency that nobody had considered. This realization saved us a lot of time and some cleanup as well.
Ask Questions
The best tip any administrator can give is to be conscious of your own ignorance. Don’t assume you know every conceivable side effect of everything you’re doing. Ask. If the senior admin looks at you like you’re an idiot, let him. Better to be thought an idiot for asking than proven an idiot by not asking!
Get Linux Past the Gatekeeper
What not to do when trying to get Linux into your server room.
Let’s face it: you can’t make use of Linux Server Hacks (Volume One or Two) unless you have a Linux server to hack! I have learned from mistakes made by both myself and others that common community ideals are meaningless in a corporate boardroom, and that they can be placed in a more tiefriendly context when presented to decision-makers. If you use Linux at home and are itching to get it into your machine room, here are some common mistakes to avoid in navigating the political side of Linux adoption in your environment.
Don’t Talk Money
If you approach the powers that be and lead with a line about how Linux is free (as in beer), you’re likely doing yourself a disservice, for multiple reasons. First, if you point an IT manager at the Debian web site (home of what’s arguably the only “totally free in all ways” Linux distribution) and tell him to click around because this will be his new server operating system, he’s going to ask you where the support link is. When you show him an online forum, he’s going to think you are completely out in left field.
Linux IRC channels, mailing lists, and forums have given me better support for all technology, commercial or not, than the vendors themselves. However, without spending money on vendor support, your IT manager will likely feel that your company has no leverage with the vendor and no contractual support commitment from anyone. There is no accountability, no feel-good engineer in vendor swag to help with migrations, and no “throat to choke” if something goes wrong.
To be fair, you can’t blame him much for thinking this—he’s just trying to keep his job. What do you think would happen if some catastrophic incident occurred and he was called into a meeting with all the top brass and, when commanded to report status, he said “I’ve posted the problem to the linuxgoofball.org forums, so I’ll keep checking back there. In the meantime, I’ve also sent email to a mailing list that one of the geeks in back said was pretty good for support…”? He’d be fired immediately!
IT departments are willing to spend money for software that can get the job done. They are also willing to spend money for branded, certified vendor support. This is not wasted money. To the extent that a platform is only one part of a larger technology deployment, the money spent on the software and on support is their investment in the success of that deployment. If it costs less for the right reasons (fewer man hours required to maintain, greater efficiency), that’s great. But “free” is not necessary, expected, or even necessarily good.
It is also not Linux’s greatest strength, so leading with “no money down” is also doing an injustice to the people who create and maintain it. The cost of Linux did many things that helped it get where it is today, not the least of which was to lower the barrier of entry for new users to learn how to use a Unix-like environment. It also lowered the barrier of entry for developers, who were able to grow the technological foundation of Linux and port already trusted applications such as Sendmail and Apache to the platform, making it a viable platform that companies were willing to adopt in some small way. Leading with the monetary argument implies that that’s the best thing about Linux, throwing all of its other strengths out the window.
Don’t Talk About Linux in a Vacuum
It’s useless (at best) to talk about running Linux in your shop without talking about it in the context of a solution that, when compared to the current solution, would be more useful or efficient.
To get Linux accepted as a viable platform, you have to start somewhere. It could be a new technology deployment, or it could be a replacement for an existing service. To understand the best way to get Linux in the door, it’s important to understand all of the aspects of your environment. Just because you know that management is highly displeased with the current office-wide instant messaging solution doesn’t mean that Jabber is definitely the solution for them. Whining to your boss that you should just move to Jabber and everything would be great isn’t going to get you anywhere, because you’ve offered no facts about Jabber that make your boss consider it an idea with any merit whatsoever. It also paints you in a bad light, because making blanket statements like that implies that you think you know all there is to know about an office-wide IM solution.
Are you ready for the tough questions? Have you even thought about what they might be? Do you know the details of the current solution? Do you know what might be involved in migrating to another solution? Any other solution? Do you know enough about Jabber to take the reins or are you going to be sitting at a console with a Jabber book open to Section 1.3 when your boss walks in to see how your big, high-profile, all-users-affected project is going?
“Linux is better” isn’t a credible statement. “A Linux file-sharing solution can work better at the department level because it can serve all of the platforms we support” is better. But what you want to aim for is something like “I’ve seen deployments of this service on the Linux platform serve 1,500 users on 3 client platforms with relatively low administrative overhead, whereas we now serve 300 clients on only 1 platform, and we have to reboot twice a week. Mean-while, we have to maintain a completely separate server to provide the same services to other client platforms.” The first part of this statement is something you might hear in a newbie Linux forum. The last part inspires confidence and hits on something that IT managers care about—server consolidation.
When talking to decision makers about Linux as a new technology or replacement service, it’s important to understand where they perceive value in their current solution. If they deployed the current IM solution because it was inexpensive to get a site license and it worked with existing client software without crazy routing and firewall changes, be ready. Can existing client software at your site talk to a Jabber server? Is there infrastructure in place to push out software to all of your clients?
It’s really simple to say that Linux rocks. It’s considerably more difficult to stand it next to an existing solution and justify the migration cost to a manager whose concerns are cost recovery, ROI, FTEs, and man-hours.
Don’t Pitch Linux for Something It’s Not Well Suited For
Linux is well suited to performing an enormous variety of tasks that are currently performed using lower-quality, higher-cost, proprietary software packages (too many to name—see the rest of this book for hints). There’s no reason to pitch it for tasks it can’t handle, as this will only leave a bad taste in the mouths of those whose first taste of Linux is a complete and utter failure.
What Linux is suitable for is 100% site-dependent. If you have a large staff of mobile, non-technical salespeople with laptops who use VPN connections from wireless hotspot sites around the globe, and you have a few old ladies manning the phones in the office all day, the desktop might not be the place for Linux to shine.
On the other hand, if you have an operator on a switchboard built in the 1920s, and the lifeblood of the business is phone communication, a Linux-based Asterisk PBX solution might be useful and much appreciated!
The point is, choose your battles. Even in Unix environments, there will be resistance to Linux, because some brands of Unix have been doing jobs for decades that some cowboy now wants Linux to perform. In some cases, there is absolutely no reason to switch.
Sybase databases have run really well on Sun servers for decades. Sybase released a usable version of their flagship product for Linux only about a year ago. This is not an area you want to approach for a migration (new deployments may or may not be another story). On the other hand, some features of the Linux syslog daemon might make it a little nicer than Solaris as a central log host. Some software projects readily tell you that they build, develop, and test on Linux. Linux is the reference Unix implementation in some shops, so use that leverage to help justify a move in that direction. Do your homework and pick your battles!
Don’t Be Impatient
Personally, I’d rather have a deployment be nearly flawless than have it done yesterday. Both would be wonderful, but if history is any indication, that’s asking too much.
Don’t bite off more than you can chew. Let Linux grow on your clients, your boss, and your users. Get a mail server up and running. Get SpamAssassin, procmail, and a webmail portal set up on an Apache server. Then maintain it, optimize it, and secure it. If you do all this, Linux will build its own track record in your environment. Create a mailing list server. Build an LDAP-based white pages directory that users can point their email applications at to get user information. If you play your cards right, a year from now people will begin to realize that relatively few resources have been devoted to running these services, and that, generally, they “just work.” When they’re ready to move on to larger things, whom do you think they’ll turn to? The guy who wanted to replace an old lady’s typewriter with a dual-headed Linux desktop?
Think again. They’ll be calling you.
Prioritize Your Work
Perhaps no one in the company needs to learn good time management more than system administrators, but they are sometimes the last people to attempt to organize their work lives.
Like most system administrators, you probably find it next to impossible to keep up with the demands of your job while putting in just 40 hours a week. You find yourself working evenings and weekends just to keep up. Sometimes this is fun, as you get to work with new technologies—and let’s face it, most sysadmins like computers and often work on them even in their free time. However, working 60-hour weeks, month after month, is not a good situation to be in. You’ll never develop the social life you crave, and you won’t be doing your company a service if you’re grouchy all the time because of lack of sleep or time away. But the work keeps coming, and you just don’t see how you’ll ever be able to cram it all into a standard work week…which is why you need this hack about task prioritization. I know, it’s not really a hack about Linux servers, but it is a hack about being a sysadmin, which means it should speak directly to everyone reading this book.
Prioritizing Tasks
Managing your tasks won’t only ensure you get everything done in a timely manner. It will also help you make better predictions as to when work can be done and, more importantly, it will make your customers happier because you’ll do a better job of meeting their expectations about when their requests will be met. The next few sections discuss the methods you can use to order your tasks.
Doing tasks in list order.
One method for ordering your tasks is to not spend time doing it. Make the decision simple and just start at the top of the task list and work your way down, doing each item in order. In the time you might have spent fretting about where to start, chances are you’ll have completed a couple of smaller items. In addition, because the first items on the list are usually tasks you couldn’t complete the previous day, you’ll often be working on the oldest items first.
Doing your to-do items in the order they appear is a great way to avoid procrastination. To quote the Nike advertisements, “Just do it.”
If your list is short enough that you can get through all the items in one day, this scheme makes even more sense—if it doesn’t matter if a task gets done early in the day or late in the day, who cares in what order it’s completed? Of course, that’s not often the case…
Prioritizing based on customer expectations.
Here’s a little secret I picked up from Ralph Loura when he was my boss at Bell Labs. If you have a list of tasks, doing them in any order takes (approximately) the same amount of time. However, if you do them in an order that is based on customer expectations, your customers will perceive you as working faster. Same amount of work for you, better perception from your customers. Pretty cool, huh?
So what are your customer expectations? Sure, all customers would love all requests to be completed immediately, but in reality they do have some conception that things take time. User expectations may be unrealistic, and they’re certainly often based on misunderstandings of the technology, but they still exist.
We can place user expectations into a few broad categories:
- Some requests should be handled quickly.
Examples include requests to reset a password, allocate an IP address, and delete a protected file. One thing these requests have in common is that they often involve minor tasks that hold up larger tasks. Imagine the frustration a user experiences when she can’t do anything until a password is reset, but you take hours to get it done.
- “Hurry up and wait” tasks should be gotten out of the way early.
Tasks that are precursors to other tasks are expected to happen quickly. For example, ordering a small hardware item usually involves a lot of work to push the order through purchasing, then a long wait for the item to arrive. After that, the item can be installed. If the wait is going to be two weeks, there is an expectation that the ordering will happen quickly so that the two-week wait won’t stretch into three weeks.
- Some requests take a long time.
Examples include installing a new PC, creating a service from scratch, or anything that requires a purchasing process. Even if the vendor offers overnight shipping, people accept that overnight is not “right now.”
- All other work stops to fix an outage.
The final category is outages. Not only is there an expectation that during an outage all other work will stop to resolve the issue, but there is an expectation that the entire team will work on the project. Customers generally do not know that there is a division of labor within a sysadmin team.
Now that we understand our customers’ expectations better, how can we put this knowledge to good use? Let’s suppose we had the tasks shown in Figure 4-4 on our to-do list.
If we did the tasks in the order listed, completing everything on the day it was requested in six and a half hours of solid work (plus an hour for lunch), we could be pretty satisfied with our performance. Good for us.
However, we have not done a good job of meeting our customers’ perceptions of how long things should have taken. The person that made request “T7” had to wait all day for something that he perceived should have taken two minutes. If I was that customer, I would be pretty upset. For the lack of an IP address, the installation of a new piece of lab equipment was delayed all day.
(Actually, what’s more likely to happen is that the frustrated, impatient customer wouldn’t wait all day. He’d ping IP addresses until he found one that wasn’t in use at that moment and “temporarily borrow” that address. If this were your unlucky day, the address selected would conflict with something and cause an outage, which could ruin your entire day. But I digress….)
Let’s reorder the tasks based on customer perceptions of how long things should take. Tasks that are perceived to take little time or to be urgent will be batched up and done early in the day. Other tasks will happen later. Figure 4-5 shows the reordered tasks.
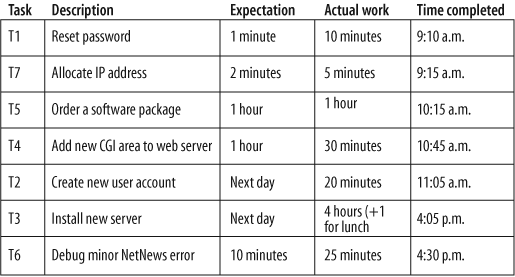
We begin the day by doing the two tasks (T1 and T7) that customers expect to happen quickly and that will hold up other, larger, projects. We succeed in meeting the perceived amount of time that these tasks should take, and everyone’s happy.
Prioritizing Projects
The previous section described ways to prioritize individual tasks. Now I’ll present some useful techniques for prioritizing projects.
Prioritization for impact.
Let’s say that you and your fellow sysadmins brain-stormed 20 great projects to do next year. However, you only have the budget and manpower to accomplish a few of them. Which projects should you pick?
It’s tempting to pick the easy projects and do them first. You know how to do them, and there isn’t much controversy surrounding them, so at least you’ll know that they’ll be completed.
It’s also very tempting to pick out the fun projects, or the politically safe projects, or the projects that are the obvious next steps based on past projects.
Ignore those temptations, and find the projects that will have the biggest positive impact on your organization’s goals. It’s actually better to do one big project that will have a large positive impact than many easy projects that are superficial—I’ve seen it many times. Also, an entire team working on one goal works better than everyone having a different project, because we work better when we work together.
Here’s another way to look at it. All projects can fit into one of the four categories listed in Figure 4-6.

Doing category A projects first seems like the obvious course. An easy project that will have a big impact is rare, and when such projects magically appear in front of us, doing them always looks like the right choice. (Warning: Be careful, because their A status may be a mirage!)
It’s also obvious to avoid category D projects. A project that is difficult and won’t change much shouldn’t be attempted.
However, most projects are either in category B or C, and it’s human nature to be drawn to the easy C projects. We can fill our year with easy projects, list many accomplishments, and come away looking very good. However, highly successful companies train management to reward workers who take on category B projects—the difficult but necessary ones.
If you think about it in terms of Return on Investment (ROI), it makes sense. You’re going to spend a certain amount of money this year. Do you spend it on many small projects, each of which will not have a big impact? No, you look at what will have the biggest positive impact and put all your investment into that effort.
It’s important to make sure that these “big-impact” projects are aligned with your company’s goals—important for the company and important for you too. You will be more highly valued that way.
Prioritizing requests from your boss.
If your boss asks you to do something, and it’s a quick task (not a major project), do it right away. For example, if your boss asks you to find out approximately how many PCs are running the old version of Windows, get back to her with a decent estimate in a few minutes.
It helps to understand the big picture. Usually, such requests are made because your boss is putting together a much larger plan or budget (perhaps a cost estimate for bringing all PCs up to the latest release of Windows), and you can hold up her entire day by not getting back to her quickly with an answer.
Why does this matter? Well, your boss decides what happens at your next salary review. Do I need to say more? Maybe I do. Your boss will have a fixed amount of money to dole out for all raises. If she gives more to Moe, Larry is going to get less. When your boss is looking at the list of people on the team, do you want her to look at your name and think “he sure did get me an estimate of the number of out-of-date Windows PCs quickly. Gosh, he always gets me the things I need quickly.” Or do you want your boss to be thinking “you know, the entire budget was held up for a day because I was waiting for that statistic.” Or worse yet “all the times I looked foolish in front of my boss because I was late, it was because I was waiting for [insert your name here] to get me a piece of information. So-and-so isn’t getting a good raise this year.” Keeping the boss happy is always a good idea!
Summary
Managing your priorities ensures that you meet your customers’ expectations and get the work with the biggest impact done in a timely manner. However, prioritization is just one part of a time-management solution. Though you can go to general time-management books for more ideas, I humbly suggest a reading of my book, Time Management for System Administrators (O’Reilly).
—Tom Limoncelli
Get Linux Server Hacks, Volume Two now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

