May 2026
Intermediate
374 pages
6h 40m
Korean
이 작품은 AI를 사용하여 번역되었습니다. 여러분의 피드백과 의견을 환영합니다: translation-feedback@oreilly.com
지난 장을 마치면, 특히 규모가 지나치게 크지 않아 하나의 GPU에 수용 가능한 모델의 경우, LLM 서빙 최적화와 관련된 많은 과제를 해결하는 데 필요한 핵심 기법을 익히게 됩니다. 예를 들어 1,000억 개 이상의 매개변수를 가진 더 큰 규모의 LLM의 경우, 일반적으로 하나의 GPU로는 모델을 GPU 메모리에 로드하고 만족스러운 지연 시간으로 결과를 생성하기에 충분하지 않습니다. 이 장에서는 LLM 서빙 성능을 더욱 향상시키기 위한 고급 기법들을 살펴보겠습니다. 여기에는 다음이 포함됩니다:
토큰 간 지연 시간(ITL)을 단축하기 위한 LLM 생성 단계의 디코딩 가속화를위한 추측적 디코딩
단일 GPU에서 실행 시 용량이 부족하거나 성능이 충분하지 않은 대규모 LLMs을 위한 멀티 GPU 및 멀티 노드 서빙
프리필( prefill) 과 디코딩 단계를 분리하고 각각의 상충 관계를 독립적으로 미세 조정하기위한 프리필-디코딩(PD) 분산
초고속 첫 토큰 출력 시간(TTFT)과 높은 캐시 적중률을 달성하기 위한고급 KV 캐싱 기술
단일 기법 만으로도 지연 시간, 특히 ITL을 2~3배나 단축할 수 있다면 어떨까요? 추론이 많이 필요한 긴 생성 작업에 특히 유용한 새로운 접근 방식인 추측적 디코딩을 소개합니다.
예를 들어 검색이나 추천을 위해 백만 개의 데이터 포인트를 다루는 대규모 ML 시스템에서는, 첫 번째 필터링 단계에 정확도는 낮지만 작은 모델을 사용하는 것이 일반적입니다. 후보 데이터 포인트의 수를 약 1,000개로 대폭 줄인 후, 남은 후보들에 대해 더 크고 정확한 모델을 적용하여 최종 결과를 도출합니다.
추측적 디코딩(speculative decoding)은 이와 매우 유사한 방식을 토큰 수준에서 적용합니다. 이 기법은 '초안 모델( draft model)'이라 부르는 작은 모델을 활용하여, 대규모 '타겟 모델'을 위한 후보 토큰을 생성하는 데 도움을 줍니다. 이는 LLM 생성의 디코딩 단계를 가속화합니다. 다시 말해, 토큰 생성 과정에서 작은 드래프트 모델이 다음 토큰이 무엇일지 추측하도록 합니다. 이제 타겟 모델은 토큰을 하나씩 생성하는 대신, 생성된 토큰을 검증하는 역할을 합니다. 타겟 모델이 드래프트 모델의 예측이 적절하다고 판단하면 해당 토큰을 수용하고 다음 단계로 넘어갑니다.
그림 7-1에 표시된 바와 같이, 드래프트 모델이 토큰 추측을 수행하고 대상 모델이 병렬 검증 작업을 수행하는 추측 디코딩의 한 이터레이션 부터 시작하겠습니다.
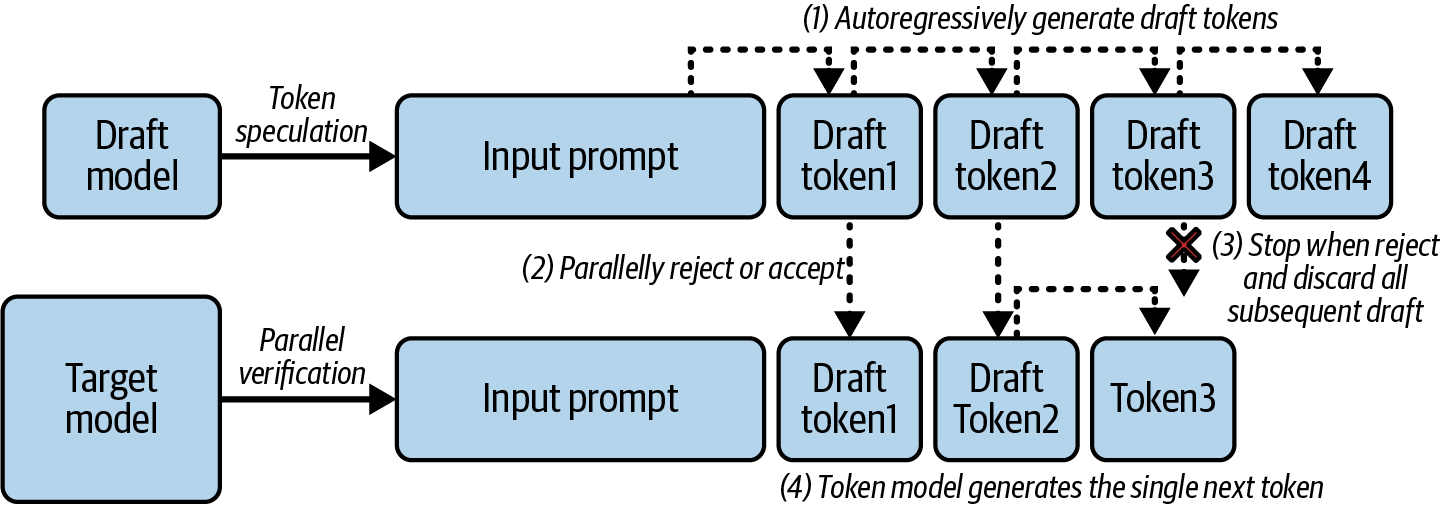
먼저, 드래프트 모델이 ...
Read now
Unlock full access






