6.5. Pre-Joined Aggregates
Like aggregate fact and aggregate dimension tables, a pre-joined aggregate can be processed in two ways. It can be dropped and rebuilt during each load process, or it can be incrementally loaded. The drop-and-rebuild approach is simple, requiring a single query to do most of the work. An incremental load does not need to manage any surrogate keys but must still process slow changes to dimension values.
6.5.1. Dropping and Rebuilding a Pre-Joined Aggregate
If a pre-joined aggregate is populated through a drop-and-rebuild approach, the load process is simple. First, the existing table is dropped and recreated, or simply truncated of all data. After this is done, a single SQL statement can do all of the work required to select source data, aggregate it, and insert it into the aggregate table.
The pre-joined aggregate in Figure 6.11 summarizes the facts in the Order table by Date and Brand. Salesperson and Customer have been completely summarized, and do not appear in the aggregate table. The attributes of the base schema present in the aggregated schema are shown in bold type.
Figure 6.11. A pre-joined aggregate.
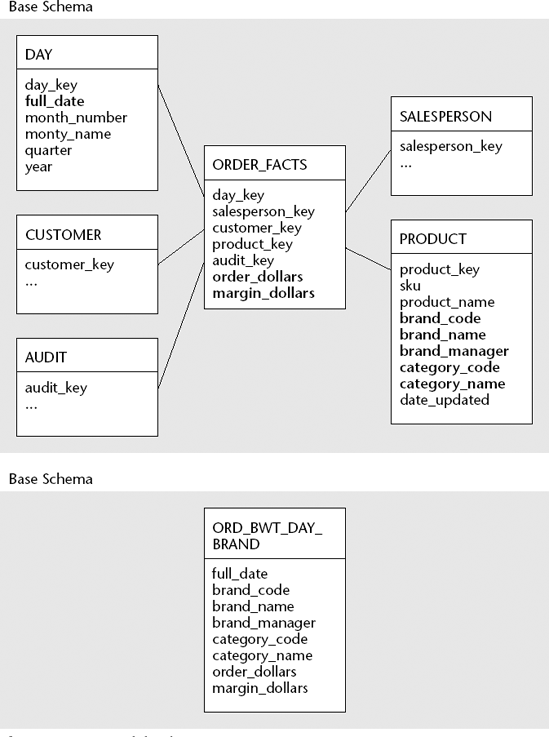
In a drop-and-rebuild scenario, the table ord_bwt_day_brand from Figure 6.11 can be loaded by truncating the table and issuing a single SQL statement:
INSERT INTO ord_bwt_day_brand
SELECT
full_date,
brand_code, brand_name, brand_manager, category_code, ...
Get Mastering Data Warehouse Aggregates: Solutions for Star Schema Performance now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

