May 2021
Intermediate to advanced
456 pages
10h 44m
English
Writing an implementation of the Fibonacci sequence is another step in the hero’s journey to becoming a coder. The Rosalind Fibonacci description notes that the genesis for the sequence was a mathematical simulation of breeding rabbits that relies on some important (and unrealistic) assumptions:
The first month starts with a pair of newborn rabbits.
Rabbits can reproduce after one month.
Every month, every rabbit of reproductive age mates with another rabbit of reproductive age.
Exactly one month after two rabbits mate, they produce a litter of the same size.
Rabbits are immortal and never stop mating.
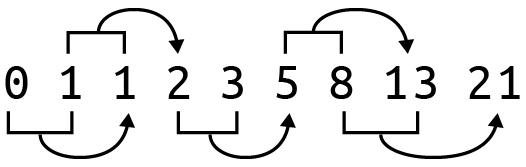
The sequence always begins with the numbers 0 and 1. The subsequent numbers can be generated ad infinitum by adding the two immediately previous values in the list, as shown in Figure 4-1.
If you search the internet for solutions, you’ll find dozens of different ways to generate the sequence. I want to focus on three fairly different approaches. The first solution uses an imperative approach where the algorithm strictly defines every step. The next solution uses a generator function, and the last will focus on a recursive solution. ...
Read now
Unlock full access






