The underpinnings of changelogs, manifests, and filelogs are provided by a single structure called the revlog.
The revlog provides efficient storage of revisions using a delta mechanism. Instead of storing a complete copy of a file for each revision, it stores the changes needed to transform an older revision into the new revision. For many kinds of file data, these deltas are typically a fraction of a percent of the size of a full copy of a file.
Some obsolete revision control systems can only work with deltas of text files. They must either store binary files as complete snapshots or encoded into a text representation, both of which are wasteful approaches. Mercurial can efficiently handle deltas of files with arbitrary binary contents; it doesn’t need to treat text as special.
Mercurial only ever appends data to the end of a revlog file. It never modifies a section of a file after it has written it. This is both more robust and more efficient than schemes that need to modify or rewrite data.
In addition, Mercurial treats every write as part of a transaction that can span a number of files. A transaction is atomic: either the entire transaction succeeds and all its effects are visible to readers in one go, or the whole thing is undone. This guarantee of atomicity means that if you’re running two copies of Mercurial, where one is reading data and one is writing it, the reader will never see a partially written result that might cause confusion.
The fact that Mercurial only appends to files makes it easier to provide this transactional guarantee. The easier it is to do stuff like this, the more confident you should be that it’s done correctly.
Mercurial cleverly avoids a pitfall common to all earlier revision control systems: the problem of inefficient retrieval. Most revision control systems store the contents of a revision as an incremental series of modifications against a “snapshot.” (Some base the snapshot on the oldest revision, others on the newest.) To reconstruct a specific revision, you must first read the snapshot, and then every one of the revisions between the snapshot and your target revision. The more history that a file accumulates, the more revisions you must read, and hence the longer it takes to reconstruct a particular revision.
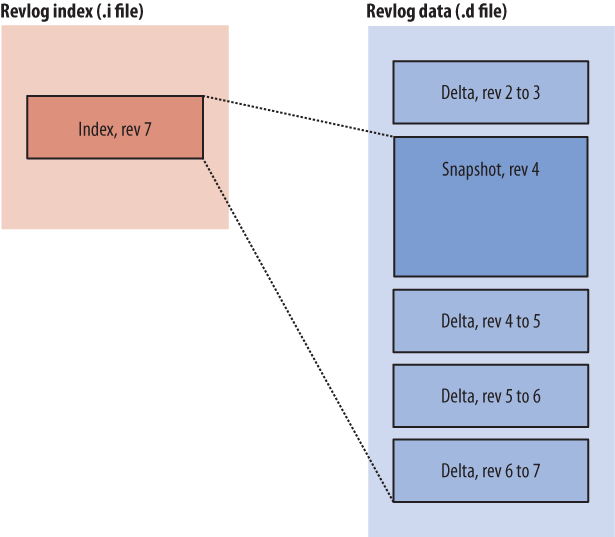
The innovation that Mercurial applies to this problem is simple but effective. Once the cumulative amount of delta information stored since the last snapshot exceeds a fixed threshold, it stores a new snapshot (compressed, of course) instead of another delta. This makes it possible to reconstruct any revision of a file quickly. This approach works so well that it has since been copied by several other revision control systems.
Figure 4-3 illustrates the idea. In an entry in a revlog’s index file, Mercurial stores the range of entries from the data file that it must read to reconstruct a particular revision.
Aside: the influence of video compression
If you’re familiar with video compression or have ever watched a TV feed through a digital cable or satellite service, you may know that most video compression schemes store each frame of video as a delta against its predecessor frame.
Mercurial borrows this idea to make it possible to reconstruct a revision from a snapshot and a small number of deltas.
Along with delta or snapshot information, a revlog entry contains a cryptographic hash of the data that it represents. This makes it difficult to forge the contents of a revision, and easy to detect accidental corruption.
Hashes provide more than a mere check against corruption; they are used as the identifiers for revisions. The changeset identification hashes that you see as an end user are from revisions of the changelog. Although filelogs and the manifest also use hashes, Mercurial only uses these behind the scenes.
Mercurial verifies that hashes are correct when it retrieves file revisions and when it pulls changes from another repository. If it encounters an integrity problem, it will complain and stop whatever it’s doing.
In addition to the effect it has on retrieval efficiency, Mercurial’s use of periodic snapshots makes it more robust against partial data corruption. If a revlog becomes partly corrupted due to a hardware error or system bug, it’s often possible to reconstruct some or most revisions from the uncorrupted sections of the revlog, both before and after the corrupted section. This would not be possible with a delta-only storage model.
Get Mercurial: The Definitive Guide now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

