One of the problems that led to the first dot-com crash was the huge expense of development, especially server software. A new and viable set of open source tools emerged from the ashes of the first dot-com and became the foundation for the next generation of the Internet. In the summer of 2001, a new acronym emerged; LAMP—Linux, Apache, MySQL and PHP—became the platform of choice for an entire generation of developers. And like that, PHP and MySQL were married (they were right next to each other, after all). The two seemed destined to go together forever.
There was only one problem. PHP—which started as a templating language—matured and gradually embraced objects. PHP was being used in more complex applications and the language consistently changed to meet these ever-increasing demands. The practice of writing raw SQL queries in template files quickly became unacceptable (some say it was never acceptable). As the problems became more and more complex, tools were written to solve the constantly growing trouble of PHP using objects (or arrays) and MySQL (and the other relational databases) using tables, rows, and columns.
This isn’t a problem specific to PHP. For decades, people have built tools and libraries to automate the process of translating objects to relational data structures. The most popular set is called Object Relational Mappers (ORMs). ORMs were built to solve the problem of SQL. Their sales pitch is: use an ORM because it masks all the nasty details of the datastore, so all you ever need to touch is your friendly PHP objects. Although tools emerged that did a reasonable job of making good on that promise, they never really worked perfectly. First, you always needed to remember that there was a relational database behind these objects that spoke in terms of tables, rows, and columns. Second, these ORMs came at a high cost. They added a lot of complexity and overhead to applications and persisted only a subset of SQLs features. As they developed, it quickly became the case that learning an ORM was far more time-consuming than learning SQL in the first place. It is sufficient to say that although the ORMs largely fixed the problems of SQL, they brought with them the problems of ORMs.
The objective of an ORM may be simple, but the solution never is.
Propel and Doctrine are the two most popular ORMs for PHP. Propel follows an active record model; Doctrine follows hibernate. Both projects are quite large, comprising tens of thousands of lines of code. Doctrine also provides its own SQL-like query language called DQL, so you need to know both SQL and DQL to use Doctrine.
The core objective of the ORM is developer convenience. The core objective of an ORM is developer convenience as they are built to translate the database's tables, rows, and columns into your languages objects. The most common approach is called Active Record. It is especially easy to use but carries with it some of the worst performance compromises to do so. This is universally true, but especially in PHP. Typically they perform reasonably well with low activity, but as load or data size increases, their performance compromises become a large hindrance. A common criticism is that Ruby on Rails doesn’t scale, and it’s best as a prototype environment. This is an accurate criticism, but it is important to recognize that the place that it doesn't scale isn't the controller or view, it's the Active Record layer. Not only do ORMs add a layer of overhead at runtime, but they also consume a lot of memory.
It wasn’t just that the ORMs made it so that SQL was hidden; they stripped it down to its most basic features. ORMs made it really quite simple to do the operational stuff like reading and writing objects, commonly called CRUD (Create Read Update Delete) operations, but failed in large part to support any of SQL’s advanced features. If you don’t believe me, try to do a left outer join with an ORM or an aggregate function like an average across a set of data. Many have even failed to provide support for database transactions, passing along the responsibility to the application.
In an effort to address some of the performance shortcomings of ORMs and relational databases in general, MemCache was built. MemCache was so effective at speeding up data retrieval that it was quickly adopted across the industry. It soon became a necessary element for any application looking to scale or even just perform acceptably. In fact, it may have had the highest percentage of adoption of a single technology, nearly every website or application on the internet uses it.
While MemCache works well to quickly access data, it does little to simplify our applications. With the addition of MemCache, ORMs or applications have to not only manage translating objects to tables, rows, and columns, but also the additional logic to store these objects behind a key (or set of keys) and track when to retrieve data from MemCache versus the RDBMS and when to expire the data in MemCache to ensure that the RDBMS and MemCache data are in sync—not a trivial task and one that often concludes in a “good enough” state, leaving undesirable results.
With all the problems with ORMs, you may wonder why programmers use them at all. People were willing to make the compromises to adopt ORMs for one big reason; PHP applications are by and large CRUD applications. Rarely do they use all of the rich features the relational database provides, so giving them up seemed a small price to pay for the benefit of simplified access to the data. Additionally, there weren’t really any other good options. For very simple projects, one could write SQL in one’s code, but this was hard to debug and even harder to ensure that it was done securely. PHP is famous for enabling SQL injection attacks, as inexperienced developers pass variables right into the SQL without sanitization.
Ever wonder what would happen if someone optimized a data store for the type of operations application developers actually use?
In 2007, two brilliant developers, Eliot Horowitz and Dwight Merriman (the founders of 10gen), set out to do just that. Both had previously worked at DoubleClick—Dwight as CTO and founder and Eliot as an engineer—designing the system that served and tracked hundreds of thousands of ads per second and were intimately familiar with the challenges of building a high-volume, high-transaction, scaleable system with existing database technologies. They knew the challenges well and what current relational database offerings lacked. They set out to build a database optimized for operations and scale. They called their database MongoDB.
The driving philosophy behind MongoDB was to retain as much functionality as possible while permitting horizontal scale and, at the same time, to ensure that the developer experience is as elegant as possible.
As they set out to build MongoDB, they looked at the features provided by relational databases and asked what we could live without and still make it easy for the developer to work with. Relationships make horizontal scale impossible and multiple table transactions hard to do on distributed clusters. They then looked at improving the developer experience. Key value stores are great, but often more functionality is needed. Sometimes we need to access things by something other than the key. Since most languages today operate on objects, what if MongoDB used a data structure that resembled an object?
The founders decided to build MongoDB as a document database. At the highest level of organization, it is quite similar to a relational database, but as you get closer to the data itself, you will notice a significant change in the way the data is stored. Instead of databases, tables, columns, and rows you have databases, collections, and documents (see Figure 1-1).
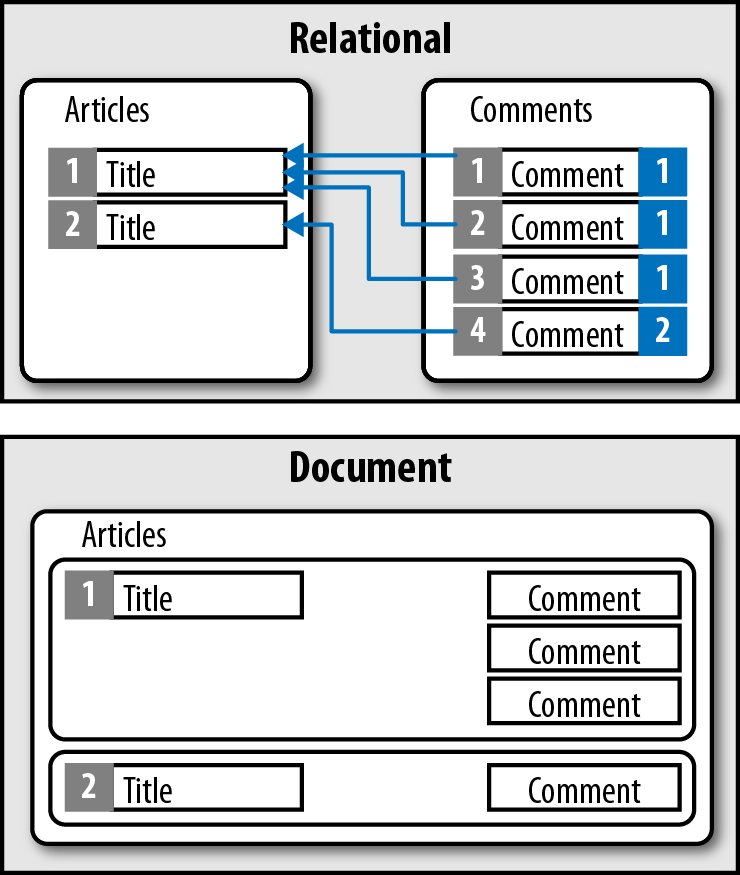
Often people think of PDF files and Word documents when they hear the term “document database,” which isn’t accurate. For all intents and purposes, a document is equivalent to an array in PHP.
MongoDB groups data into databases in the very same way as most relational databases do. If you have any experience with relational databases, you should think of these the same way. In an RDBMS, a database is a set of tables, stored procedures, views, and so on. In MongoDB, a database is a set of collections.
Collections correlate to tables within the relational database paradigm. For most purposes, you can think of them as tables (just don’t call them that). Just like tables, indexes are applied to collections. A collection is a collection of documents and indexes.
In MongoDB, the primary object is called a document. A document doesn’t have a direct correlation in the relational world. Documents do not have a predefined schema like relational database tables. A document is partly a row, in that it’s where the data is located, but it's also part columns, in that the schema is defined in each document (not table-wide).
The best way to think of a document is as a multidimensional array. In an array, you have a set of keys that map to values. The values could themselves be another array. In practical matters, a MongoDB document is a JSON array. Documents map extremely well to objects and other PHP data types like arrays and even multidimensional arrays.
As this text is intended for a PHP audience, the PHP array has the closest correlation of any data type. It’s nearly a perfect 1-to-1 correlation. It’s important to note that the PHP arrays are unique, as they permit key ⇒ value as well as enumerated keys. Not only can both types be used as an array, but they can coexist in the same array. Additionally, PHP doesn’t have the ability to have unordered arrays. MongoDB uses JSON for its data store, which doesn’t share these same properties. In a JavaScript JSON representation, there is a difference between a list (which has unordered, unkeyed values) and a hash (key/value pairs). In practical use, however, this difference is rarely, if ever, noticed.
MongoDB wasn’t written in a lab. It was written to solve real-world problems. It has been optimized to be extremely efficient at operational procedures. Great care was taken to optimize it in a few ways. The first thing you should notice in using MongoDB is that documents are really powerful. You can store a lot of associated data in a single document while keeping your data structured, normalized, and able to be queried. Whereas you previously needed to access a dozen or more tables to retrieve data for a given object, often in MongoDB this can be accomplished in a single document. Most CRUD operations become very simple save, find, and delete operations.
Because a MongoDB document is effectively a PHP object or array, creating a new document is easy. All you need to do is create a new PHP array or object and save it. The majority of this book will explain the various ways to interact with MongoDB from PHP. While it may require an adjustment from the relational way of thinking (which so many developers are accustomed to), the interface to MongoDB is a pleasure to use and feels very natural. By and large, things work in the way you would expect them to and in a way that will make you a more efficient developer.
MongoDB was designed from the ground up to be a very high-performance database. By itself, MongoDB provides measurable performance increases over relational databases on similar operations; however, many applications will experience a considerable improvement in performance (20x or more isn’t uncommon). This is because the core database operations are not only faster but also much more straightforward. For instance, inserting a blog post into a relational database may require inserts into many tables, such as a post table, a few inserts into a tags table, a few inserts into a posts_to_tags table, insert into a category table, inserts into a media table and corresponding joining table—the list could go on. This same overall objective can be accomplished with a single document write in MongoDB.
In addition to simplier and faster operations, MongoDB also makes heavy use of memory mapped files. At the risk of oversimplifying things, essentially what this means is that MongoDB performs read-through, write-through memory caching on all working data (or as much as will fit into RAM). With MongoDB, there really isn’t a need for MemCache for most use cases.
Even with very complex structured data, MongoDB is fully optimized for creating, reading, updating, and deleting objects. As described in the previous section, many operations that previously required complex joins or multitable transactions can usually be accomplished with a much simpler schema, which results in simpler operations and a significantly more straightforward model layer. Additionally, without the need to maintain cache and worrying about updating and expiring data, not only is the application simplified, but so is the architecture.
MongoDB is a fully consistent database in the same tradition as MySQL, PostgreSQL and most of the relational databases. This is one differentiator between MongoDB and the majority of the databases in the NoSQL space which are eventually consistent. Some eventually consistent databases, also called multi master databases, make claims to have full consistency, but such claims fall short as they require a redefinition of the term “consistency.”
While there is certainly a place for eventually consistent databases, most developers don’t realize what functionality they are giving up when they accept this compromise. It’s not just about data loss, but about functionality. With fully consistent databases, you can do things like increment values easily or append items without worrying about collisions. While these operations are trivial to perform in MongoDB, such operations in eventually consistent databases are impossible without a ton of extra logic and handling in the application.
To illustrate this difference, I’ll use a simple example. Say you wanted to write a very simple voting application that tracked the username of each voter (each user can only vote once) and the total. The logic is pretty straightforward: if a username is not in the array, increment the total and append the username to the array. In MongoDB, this is a very straightforward (and atomic) operation, but it's impossible to do with an eventually consistent database.
Get MongoDB and PHP now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

