Chapter 4. Networking and Security
An essential aspect of working with instances is configuring their network connectivity. While cloud providers start customers off with a basic, working network configuration, it’s important to understand the ways to construct different network topologies, so that your clusters can communicate effectively internally, and back and forth with your own systems and with the outside world.
Network topology is of primary importance when setting up Hadoop clusters. Worker daemons like datanodes and node managers must be able to work with namenodes and resource managers, and clients must understand where to send jobs to run and where cluster data resides. You will likely spend more time designing and maintaining the network architecture of your clusters than the instances and images that serve as their building blocks.
Security considerations are intertwined with network design. Once network connections are made, you need to determine the rules by which they are used. Which parts of the network can talk to which other parts of the network? What can reach out to the internet? What can reach in from the internet? What ports should be exposed, and to whom?
This chapter covers a wide range of topics, and is more of an introduction to cloud networks and security than an application of them to Hadoop, although there are some pointers. Chapter 14 goes into much more detail about designing a network and security rules for a Hadoop cluster.
A Drink of CIDR
Before diving into the details of cloud provider network services, it’s helpful to be familiar with CIDR (Classless Inter-Domain Routing) notation, a way of denoting a continuous range of IP addresses. The scopes of network partitions and the rules that apply to activity in them are defined using CIDR notation. In this book, the term “CIDR” or “CIDR block” is used to refer to an IP address range specified in CIDR notation.
An IP address range expressed in CIDR notation has two parts: a starting IP address and a decimal number counting the number of leading bits of value 1 in the network mask, which is as long as the IP address itself. An IP address lies within the range if it matches the starting IP address when logically ANDed with the network mask.
Here are some examples that illustrate how to interpret CIDRs:
-
The range 192.168.0.0/24 represents the IP addresses from 192.168.0.0 to 192.168.0.255, for a total of 256 addresses.
-
The range 172.16.0.0/20 represents the IP addresses from 172.16.0.0 to 172.16.15.255, for a total of 4,096 addresses. Note that the number of 1 bits in the network mask does not need to be a multiple of 4, although it commonly is.
-
The range 192.168.100.123/32 represents only the single IP address 192.168.100.123. It is common practice to target a single IP address, in a security rule for example, using a /32 block.
For more about the role of CIDR in IP routing and allocation, see the Wikipedia article on Classless Inter-Domain Routing. Their usefulness in allocating IP addresses is why CIDR blocks are used to delimit virtual networks in the cloud.
Virtual Networks
Cloud providers establish virtual networks as the top-level containers where instances live. Each virtual network is separate from other virtual networks, and instances within a virtual network always communicate with each other more directly than with instances in other virtual networks or outside of the cloud provider.
A virtual network is just a basic, coarse-grained concept. To enable finer control of network topology, each virtual network is divided up into subnetworks or subnets. A subnet is not just a lower-level instance container; it also covers a range of private IP addresses. There are normally several subnets within a virtual network, each with a distinct range of private IP addresses.
Tip
RFC 1918 establishes three ranges of private IP addresses. Cloud providers use these ranges to define subnets. Any of these blocks, including just portions of them, can be used for a subnet:
-
10.0.0.0–10.255.255.255 (CIDR 10.0.0.0/8)
-
172.16.0.0–172.31.255.255 (CIDR 172.16.0.0/12)
-
192.168.0.0–192.168.255.255 (CIDR 192.168.0.0/16)
Note
Amazon Web Services calls its virtual networks Virtual Private Clouds or VPCs. Each VPC has a private IP address range, and the address range for each subnet within a VPC must be a subset of the VPC’s range. The subnet ranges do not have to completely cover the VPC range.
For example, a single virtual network could be designed to cover the entire 16-bit private IP address block of 192.168.0.0/16. One way to divide the network, as shown in Figure 4-1, is into four subnets, each covering a distinct quarter of the block: 192.168.0.0/18, 192.168.64.0/18, 192.168.128.0/18, and 192.168.192.0/18.

Figure 4-1. A virtual network with four subnets
After a virtual network is established, subnets must be created within it as homes for instances that will reside in the virtual network. Sometimes the cloud provider establishes one or more default subnets, and sometimes it is up to you to define them. The size of the private IP range of a subnet dictates its capacity for instances: for example, a range like 192.168.123.0/28 only supports 16 instances, while a range like 172.16.0.0/16 supports thousands. Instances that reside in the same subnet can communicate more quickly and easily than those in separate subnets, so sizing subnets appropriately is important for designing efficient clusters.
When you provision an instance on a cloud provider, you choose its subnet. The cloud provider assigns the instance an IP address from the remaining unused addresses in the subnet’s range, and that IP address sticks with the instance until it is terminated.
Note
The private IP address for an Azure virtual machine can either be static or dynamic. A dynamic private IP address, which is the default, is dissociated from the virtual machine even when it is stopped, while a static private IP remains across stops until termination. In order to avoid needing to reconfigure your Hadoop cluster after virtual machines are stopped and started, you will want to use static addresses.
Most of the time, a Hadoop cluster should reside within a single subnet, itself within one virtual network. Not only is this arrangement simplest, it is the least expensive and has the best performance. Chapter 10 explores other arrangements in terms of establishing high availability.
Private DNS
When an instance is provisioned inside a subnet, it is assigned not only a private IP address, but also a private DNS hostname. The hostname is automatically generated for you and registered with the cloud provider’s internal DNS infrastructure. It may simply be a form of the public IP address or some random string, and thus have no meaning. The cloud provider also automatically configures each instance’s network settings so that processes running on it can resolve private DNS hostnames successfully, both its own and those of others in the virtual network.
A private DNS hostname can be resolved to a private IP address only by instances within the virtual network of the instance it is assigned to. Other instances, including those in other virtual networks of the same cloud provider, must use a public DNS hostname or public IP address, if those are assigned at all.
Note
In Azure, two virtual networks can be peered, so that instances in them can communicate using private IP addresses. The two networks must have private IP address ranges that do not overlap.
In practice, private DNS hostnames have limited usefulness in working with a Hadoop cluster; the private IP addresses work just as well, and are often shorter and therefore easier to work with. Given all the other things to think about when managing virtual networks and how instances are deployed within them, you may find that private DNS can essentially be ignored.
Public IP Addresses and DNS
While an instance is always assigned a private IP address, it may also be assigned a public IP address. The public IP address is not part of the instance’s subnet’s IP range, but is instead assigned from the block of IP addresses administered by the cloud provider. An instance with a public IP address is therefore addressable from outside the virtual network and, in particular, from the internet.
While having a public IP address is a prerequisite for an instance to have connectivity outside the virtual network, it does not mean that the instance can be reached, or itself reach out from the virtual network. That depends on the security rules that govern the instance and routing rules that apply to the subnet.
A cloud provider may also assign a public DNS hostname to an instance with a public IP address. The typical public DNS hostname is under the domain of the cloud provider and, like a private DNS hostname, often has no real meaning. Still, the cloud provider does establish resolution of the public DNS hostname to the public IP address for external clients, so it is usable.
If you have a DNS domain that you want to use for assigning public DNS hostnames to your instances, you can use the cloud provider’s public DNS component to manage assignments (AWS Route 53, Google Cloud DNS, and Azure DNS). In the context of configuring and using Hadoop clusters, however, it’s almost always sufficient to work with private DNS hostnames for instances. Save public DNS hostnames for those few gateway instances1 that host public-facing interfaces to your system.
Tip
Without a public IP address or public DNS hostname, an instance is not reachable from the internet. It is therefore much more difficult to accidentally expose such an instance through, for example, overly permissive security settings.
The private and public addresses for instances in a virtual network provide a logical means for finding where instances are. It is not as obvious how to understand where a virtual network and subnets within it are located.
Virtual Networks and Regions
The location of a subnet in a virtual network, or of an entire virtual network, is determined in different ways, depending on the cloud provider.
A subnet in AWS and Google Cloud Platform, besides determining the private IP address for an instance, also determines the region where the instance resides. In AWS, each subnet that you define is assigned to an availability zone, so instances in the subnet run in that availability zone, in the zone’s region. In Google Cloud, the arrangement is slightly different: each subnet is associated with an entire region, but when you provision a new instance, you can select an availability zone in the subnet’s region.
The association of regions with subnets in these providers make subnets the means by which you take geography into account when architecting the network topology for your clusters. There is a need to strike a balance between the fast, open communication possible between instances in a single subnet with the availability and reliability benefits of distributing instances across regions and therefore across subnets. Figure 4-2 shows an example virtual network demonstrating subnets in different locations.
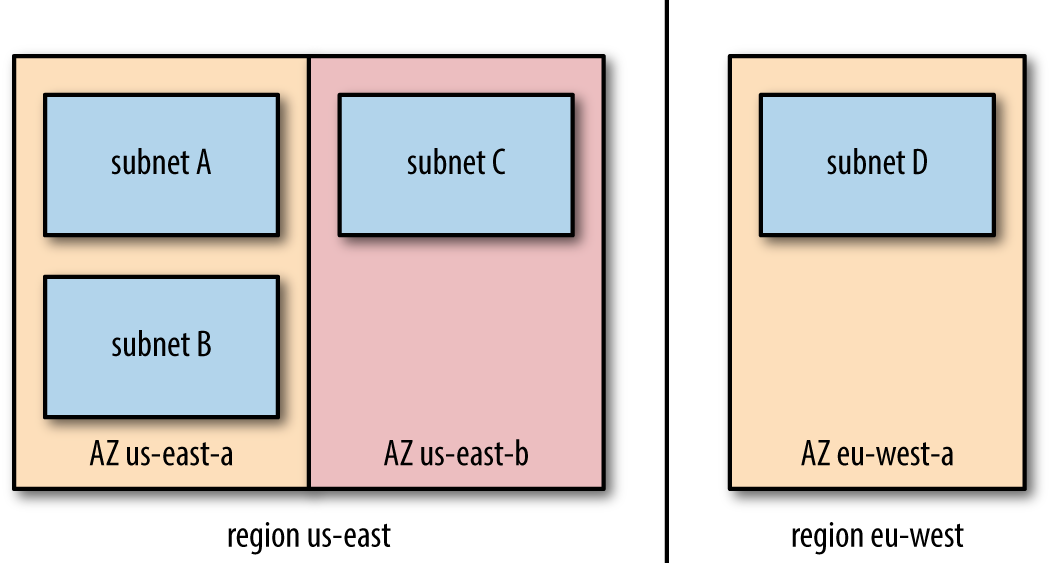
Figure 4-2. A virtual network spanning two regions and multiple availability zones
Region determination works differently in Azure. With this provider, each subnet and, in turn, each virtual network is associated with a resource group, and a resource group specifies the region for all its resources. So, setting up a cluster that spans regions is somewhat more challenging in Azure, since you will need multiple resource groups, which spreads out management.
Chapter 10 goes into detail about spanning clusters across availability zones and regions. The general advice is to never span regions, and rarely even span availability zones, due to the impact to performance and the high cost of data transfer, given the large amount of intracluster traffic that Hadoop generates. An architecture that keeps clusters confined to single regions, and even single availability zones, is much more cost effective.
Routing
Cloud networking is about much more than placing instances in the right IP address ranges in the right geographic regions. Instances need paths to follow for communication with other instances and with the world outside the cloud provider. These paths are called routes.
From the point of view of an instance, there are several possibilities for where a route leads. The shortest and simplest path is back to the instance’s own subnet. There are also usually routes that lead to other subnets in the instance’s virtual network. Some other routes lead outside the network, either to other virtual networks, or completely outside the cloud provider.
A route is comprised of an IP address range and a destination. The route declares that a resource whose IP address falls within its range can be reached by communicating with the route’s destination. Sometimes the destination is the desired resource itself, a direct route; but sometimes it is a device, specialized instance, or cloud provider feature that handles establishing communication. In general, that sort of intermediary destination is called a gateway.
Here are some examples of routes, which are also illustrated in Figure 4-3:
-
For IP addresses in the CIDR range 192.168.128.0/18, the destination is subnet C.
-
For IP addresses in the CIDR range 10.0.0.0/8, the destination is the corporate VPN gateway.
-
For any IP address (CIDR 0.0.0.0/0), the destination is the internet gateway.
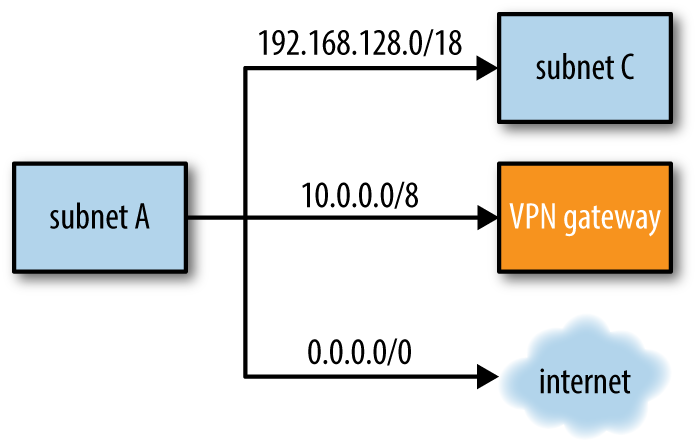
Figure 4-3. Routes leading from a subnet to various destinations
A cloud instance has a set of routes to look through, which are arranged into a route table or routing table. Given an IP address to communicate with, the route table is consulted, and the best match for the destination IP address is used. Sometimes there is only one route that satisfies the need, but sometimes there are multiple. In that case, generally, the route that most specifically matches the IP address is chosen.
Suppose that an instance has an associated route table listing the three example routes as shown in Figure 4-3. When a process on the instance attempts to initiate communication with 10.0.0.126, the instance’s networking system consults the route table and looks for the best match. The IP address does not fall within the range for subnet C, so that route is discarded. The VPN route and the internet route both match; however, the VPN route is a better match, so that route is chosen.
If there is no match at all, then network communication will fail. That is why it is typical for there to be a catch-all (or default) route for CIDR 0.0.0.0/0 that leads to the internet, the idea being that any IP address not accounted for must be outside the cloud provider.
Tip
Designing a cloud network architecture can appear daunting. A cloud provider gives you a lot of power and flexibility, but that carries complexity as well. Fortunately, when you create your first virtual network, the cloud provider sets up a reasonable default configuration for networking so you can get started quickly. For exploratory use the configuration is often acceptable, but before long you will want to look at routing and security rules to ensure they are set up for what you need, such as your first Hadoop cluster.
Routing is an important factor in building out a functioning Hadoop cluster. The daemons that comprise each service, like HDFS and YARN, need to be able to connect to each other, and the HDFS datanodes in particular need to be available for calls from pieces of other services. If all of a cluster’s daemons are confined to a single subnet, then the cloud provider’s default routing is enough; some providers can even handle routing across subnets automatically or with their defaults. For reaching out farther, such as across VPNs or to the internet, it usually becomes necessary to define some routes, as the defaults start out restrictive for the sake of security.
Each cloud provider provides routing services in a different way.
Routing in AWS
In AWS, a route table is an independent object that is associated with VPCs and subnets. Each VPC has a route table that is used as the default for subnets that do not have their own route tables.
The destination for each route is termed a target. There are a variety of targets available, some of which are described here:
-
A “local” target points to the virtual network of the communicating instance. This covers not only that instance’s own subnet, but other subnets in the same VPC.
-
An internet gateway target provides access to the internet, outside the cloud provider. When a subnet has a route to the internet, it is called a public subnet; without one, it is called a private subnet. See “Public and Private Subnets” for more detailed descriptions.
-
A virtual private gateway links to your corporate network’s VPN device, allowing access to resources within that network. To establish this connection, you must define a customer gateway in AWS representing the VPN device, create a virtual private gateway that links to it, and then define the IP address ranges covered by the gateway.
-
A VPC peering connection allows for communication between VPCs using just private IP addresses.
-
A network address translation (NAT) gateway provides access to the internet for private subnets. The gateway itself resides in a public subnet.
Routing in Google Cloud Platform
In Google Cloud Platform, each route is associated with a network, so all instances in the network may have use of it. Routes and instances are associated by tags: if a route has a tag, then it is associated with any instance with a matching tag; if a route has no tag, it applies to all instances in the network.
All of the routes defined for a network form the network’s route collection, while all of the routes that are associated with an instance form that instance’s routing table.
The destination for each route is termed its next hop. There are a variety of destinations available, some of which are described here:
-
A subnet, or portion of a subnet, can be designated as the next hop by providing a CIDR block for its private IP addresses.
-
An internet gateway URL for the next hop provides direct access to the internet, as long as the source instance has an external (public) IP address.
-
The URL or IP address of a single instance can be the next hop. The instance needs to be configured with software that can provide connectivity to the ultimate desired destination. For example, the instance could use Squid as a proxy or perform NAT using iptables to provide internet access.
Google Cloud Platform provides a service called Cloud VPN to help manage connectivity between your corporate VPN device and your instances in virtual networks, as well as between virtual networks in Google Cloud Platform itself. A VPN gateway leading to a VPN tunnel is another possible next hop for a route.
Routing in Azure
In Azure, a route table is an independent object that is associated with subnets. A route table may be associated with multiple subnets, but a subnet can have only one route table.
Azure provides system routes for common needs, which are usually comprehensive enough that you do not need to define a route table at all. For example, system routes direct network traffic automatically within a subnet, between subnets in a virtual network, and to the internet and VPN gateways. If you define a route table for a subnet, its routes take precedence over system routes.
The destination for each route is termed its next hop. There are a variety of destinations available, some of which are described here:
-
The local virtual network can be specified as the next hop for traffic between subnets.
-
A virtual network gateway or VPN gateway for the next hop allows traffic to flow to other virtual networks or to a VPN.
-
Naming the internet as the next hop provides direct access to the internet.
-
A null route or black hole route can be used as the next hop to drop outgoing traffic completely.
Network Security Rules
If routing builds the roads for traffic between your instances, then security rules define the laws the traffic must obey. Cloud providers separate the definitions of the connections between instances from the definitions of how data may flow along those connections.
In a way, routing is a coarse-grained security measure: if there is no route defined between an instance and some destination, then absolutely no traffic can pass between them. When a route is established, however, then security rules provide a way to allow some kinds of traffic and disallow others.
As with routing, each cloud provider provides network security in different ways, but they share common concepts.
Inbound Versus Outbound
Inbound rules control traffic coming to an instance, while outbound rules control traffic leaving an instance. Most of the time, you will find yourself focusing on inbound rules, and allowing unrestricted traffic outbound. The implication is that you trust the activity of the instances that you yourself control, but need to protect them from traffic coming in from outside, particularly the internet.
Allow Versus Deny
An allow rule explicitly permits some form of network traffic, while a deny rule explicitly blocks it. If an allow rule and a deny rule conflict with each other, then usually the deny rule wins out. A common pattern is to establish an allow rule with a broad scope, and then use deny rules to pick out exceptions; for example, you could allow HTTP access from everywhere with one rule, and add deny rules that block IP ranges that are known to exhibit bad behaviors.
Some security rule structures do not use deny rules at all. Instead, they start from an initial implicit state of denying all traffic, and you add allow rules for only what you want to permit.
Network Security Rules in AWS
AWS provides two main mechanisms for securing your VPC.
Security groups
The most common mechanism used is security groups. A security group provides a set of rules that govern traffic to and from an instance. Each instance can belong to one or several security groups; a VPC also has a default security group that applies to instances that aren’t associated with any groups themselves.
Each rule in a security group only allows traffic. If none of the security groups for an instance allows a particular kind of traffic, then that traffic is denied by default.
A rule in a security group can apply to either inbound traffic or outbound traffic. An inbound rule allows traffic into an instance over a protocol (like TCP or UDP) and port or port range from either another security group or a range of IP addresses. Similarly, an outbound rule allows traffic out from an instance to either another security group or to a range of IP addresses. Here are some examples of typical inbound and outbound security group rules:
-
If you are running a web server on an instance, an inbound rule for TCP port 80 can allow access from your IP address, or the IP range for your corporate network, or the entire internet (0.0.0.0/0).
-
To allow SSH access to an instance, an inbound rule should permit access for TCP port 22. It’s best to restrict this rule to your own IP address, or those in your network.
-
If a process running on an instance will need to access a MySQL server elsewhere, an outbound rule over TCP port 3306 will allow it. The destination could be the IP address of the MySQL server or, if the server is running in EC2, the server’s security group.
Figure 4-4 shows how these rules appear in the AWS console. The image is a composite view of both the Inbound and Outbound tabs for a single security group.
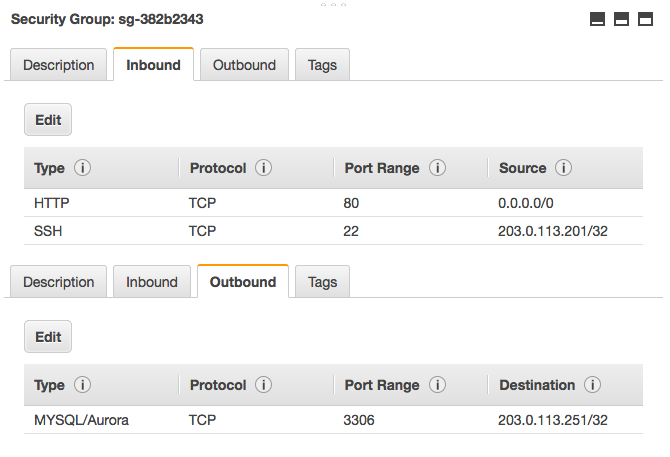
Figure 4-4. A security group with some example rules
Each VPC comes with a simple, default security group that allows outbound access to anywhere, but inbound access only from other instances in the same security group. This means that you need to set up SSH access from your local network before you can access instances provisioned there.
One convenient feature of security groups is that you only need to allow one side of a two-way connection. For example, it is enough to allow TCP port 80 inbound for a web server; since requests are allowed to flow in, AWS automatically permits responses to flow back outbound from the web server. This feature is not true of the other main mechanism for securing VPCs, network ACLs.
Network ACLs
Network ACLs are a secondary means of securing a VPC. Like security groups, they are comprised of a set of rules that govern network traffic. Unlike security groups, a network ACL is associated with a subnet, not individual instances. A subnet may only have one network ACL, or else it falls back to its VPC’s default network ACL.
A network ACL rule can either allow or deny traffic. While all of the rules in a security group apply to every network access decision, the rules in a network ACL are evaluated in a numbered order, top to bottom, and the first matching rule is enforced. If none of the rules match, then the fixed, final default rule in every network ACL denies the traffic.
Each network ACL rule is an inbound rule or outbound rule, as with security group rules. A rule applies to a protocol and port range, but sources and destinations are only specified as IP address ranges, not as security groups.
Figure 4-5 lays out a simple network ACL that allows limited inbound SSH access and HTTP access, but no other network traffic. The image is a composite view of both the Inbound Rules and Outbound Rules tabs for the ACL.
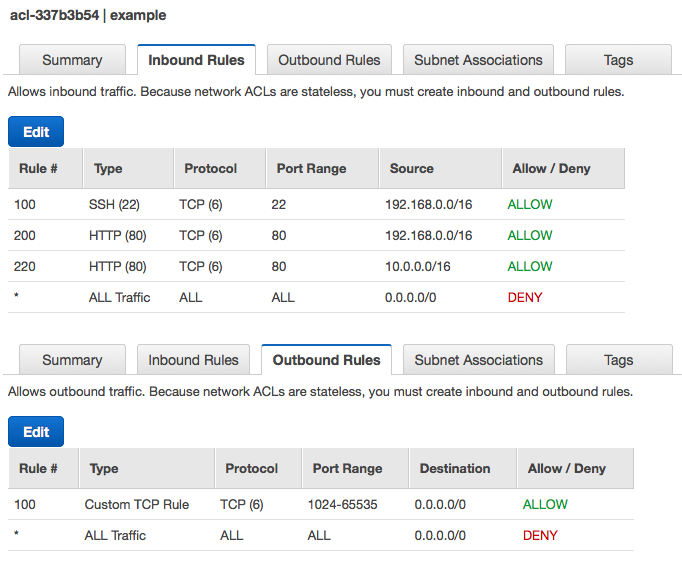
Figure 4-5. An ACL with some example rules
The inbound rules allow only SSH access from one IP address range and HTTP port 80 access from two IP address ranges. Any other inbound network access is blocked by the default final deny rule.
The outbound rules allow any traffic over nonprivileged TCP ports. This is necessary to permit outbound traffic for SSH and HTTP connections. Unlike security groups, network ACLs require you to allow both sides of two-way connections. Since it can be unpredictable what port a requesting process may use to connect out from its host, the network ACL rule here permits a wide range of ports.
To illustrate, here is an example of an HTTP client outside the virtual network performing an HTTP request to a server running inside the network. The simple ACL defined previously gates both the incoming request and outgoing response.
Inbound request from 10.1.2.3:12345 to port 80
-
rule 100: does not apply (port range)
-
rule 200: does not apply (source CIDR)
-
rule 220: applies, so access is allowed
Outbound response from port 80 to 10.1.2.3:12345
-
rule 100: applies, so access is allowed
Each VPC comes with a default network ACL that allows all traffic inbound and outbound. So, by default, your VPC does not make use of a network ACL for security, but it is still available for a second line of defense.
Network Security Rules in Google Cloud Platform
Google Cloud Platform supports firewall rules for governing traffic to instances in a network. Firewall rules are associated with the network itself, but they can apply to some or all of the instances in that network.
Each firewall rule only allows traffic. If none of the firewall rules for a network allow a particular kind of traffic, then that traffic is denied by default.
A firewall rule controls inbound traffic only. You can control outbound traffic from an instance using network utilities installed on the instance itself.
You can specify the source a firewall rule applies to as either a range of IP addresses, a subnet in the network, or an instance tag. When a subnet is specified, then the rule applies to all of the instances in that subnet as sources. An instance tag limits the applicability of a firewall rule to just instances with that tag.
Each firewall rule names a protocol (like TCP or UDP) and port or port range on the destination instances that it governs. Those instances can be either all of the instances in the network, or just instances with another instance tag, called a target tag.
Here are some examples of typical firewall rules. They are shown with some others in Figure 4-6:
-
If you are running a web server on an instance, a rule for TCP port 80 can allow access from your IP address, or the IP range for your corporate network, or the entire internet (0.0.0.0/0). To narrow down where the firewall rule applies, you can tag the web server instance as, say, “webserver”, and provide that tag as the target tag for the rule.
-
To allow SSH access to an instance, a rule should permit access for TCP port 22. It’s best to restrict this rule to your own IP address, or those in your network.
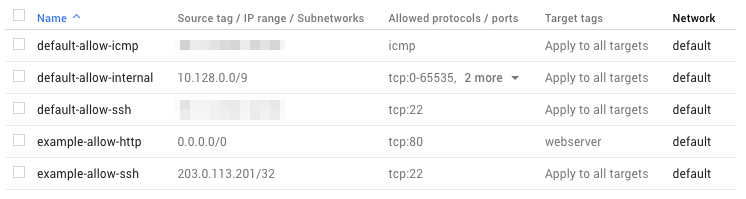
Figure 4-6. Some firewall rules (some source IP ranges are obscured)
The default network that Google Cloud Platform supplies for you comes with a small set of firewall rules that allow all traffic within the network as well as SSH (TCP port 22), RDP (port 3389), and ICMP from anywhere. This is a reasonable default behavior, although it makes sense to adjust the rules to limit sources to just your own IP address or your own network. Any new networks you create, however, do not start out with any firewall rules, and so absolutely no inbound access is permitted. It is up to you to build out the necessary firewall rules to gain access.
One convenient feature of firewall rules is that you only need to allow one side of a two-way connection. For example, it is enough to allow TCP port 80 inbound for a web server; since requests are allowed to flow in, Google Cloud Platform automatically permits responses to flow back outbound from the web server.
There are a few automatic firewall rules that are enforced on all networks. Here are some of them:
-
TCP port 25 (SMTP) is always blocked outbound from your network.
-
TCP ports 465 and 587 (SMTP over SSL) are also always blocked outbound, except to SMTP relay services hosted on Google Apps.
-
Network traffic using a protocol besides TCP, UDP, or ICMP is blocked unless the Protocol Forwarding feature of Google Cloud Platform is used to allow it.
Tip
Check the latest Google Cloud Platform documentation for ways to send email from its instances, such as SMTP relays, that involve third-party email providers.
One final security rule deserves mention here. If an instance does not have a external IP address assigned to it, then it is not granted access to the internet. This rule is enforced even if a network route provides a path to an internet gateway URL. To reach the internet from such an instance, it’s necessary to go through a gateway, using either NAT or a VPN.
Network Security Rules in Azure
Azure provides network security groups for controlling traffic into and out of either subnets or individual virtual machines through their network interfaces. A virtual machine can be subject to its subnet’s network security group as well as its own.
A network security group holds a set of rules, each of which controls either inbound traffic or outbound traffic. An inbound rule allows or denies traffic into an instance over a protocol (like TCP or UDP) and port or port range from either a range of IP addresses, a default tag (defined next), or all sources. Similarly, an outbound rule allows or denies traffic out from an instance to either a range of IP addresses, a default tag, or all destinations.
A default tag is a symbolic representation for a set of IP addresses. For example, the virtual network tag stands in for the local virtual network and those connected to it. The internet tag represents the internet, outside of Azure’s infrastructure and connected VPNs.
Here are some examples of typical inbound and outbound security group rules:
-
If you are running a web server on an instance, an inbound rule for TCP port 80 can allow access from your IP address, or the IP range for your corporate network, or the entire internet using the internet default tag.
-
To allow SSH access to an instance, an inbound rule should permit access for TCP port 22. It’s best to restrict this rule to your own IP address, or those in your network.
-
If a process running on an instance will need to access a MySQL server elsewhere, an outbound rule over TCP port 3306 will allow it. The destination could be the IP address of the MySQL server.
Figure 4-7 shows how these rules appear in the Azure portal.
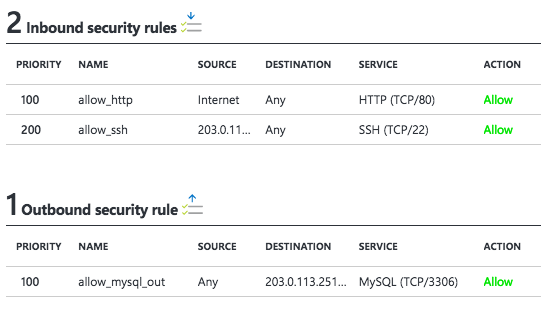
Figure 4-7. A network security group with some example rules
Rules are evaluated in priority order to determine which one holds sway. A lower number priority on a rule indicates a higher priority.
Every network security group has a default set of rules, which have lower priorities than any user-defined rules. They allow, among other things, all traffic from the same virtual network and all outbound traffic to the internet, but deny inbound traffic from anywhere but the virtual network. The rules can be overridden with user-defined rules.
Putting Networking and Security Together
As you have seen, there is a lot to think about when it comes to networking and security in a cloud provider. Getting started with them can feel like jumping into the deep end of a pool, or being dropped into a foreign land without a map. Here are some pointers to getting rolling.
Cloud providers do try to start you out with a sensible initial arrangement: a single virtual network with one or a few subnets, and default routing and security rules applied. Of all the concerns, routing tends to require the least amount of attention, as defaults and fallbacks define almost all of the necessary connections.
For small-to-medium Hadoop deployments, a single virtual network usually suffices. As described in the beginning of this chapter, it is useful to think of each virtual network as a container for your clusters. With subnets to provide any necessary divisions or regional variations, and ample IP addresses available, you may find you can go a long time before needing to define an entirely new network.
Routing and security rules become more important once traffic needs to be sent to or received from outside a virtual network. Keeping Hadoop clusters confined to single subnets or, at worst, single virtual networks eliminates most of the need to define routes and security rules. One important exception is allowing SSH access to some number of instances, which is described in the following chapters about getting started with each cloud provider. Another is opening up ports for applications running alongside clusters, or for web interfaces of Hadoop components. For these exceptions, the process is typically only defining a route if necessary and declaring a security rule that allows access.
What About the Data?
The purpose here of creating cloud instances, networking them together, and establishing routes and security rules is to stand up Hadoop clusters, and the purpose of these clusters is to work on data. The data moves through the network between instances, but where is it stored?
As you would expect, cloud providers offer ranges of storage options that include disks, databases, general object storage, and other services. Understanding how these storage options can be used is just as important for creating effective clusters as understanding networking and security.
1 See “Cluster Topologies” for a description of gateway instances.
Get Moving Hadoop to the Cloud now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

