Any organization that uses the Oracle relational database management system (RDBMS) probably has multiple databases. There are a variety of reasons why you might use more than a single database in a distributed database system:
Different databases may be associated with particular business functions, such as manufacturing or human resources.
Databases may be aligned with geographic boundaries, such as a behemoth database at a headquarters site and smaller databases at regional offices.
Two different databases may be required to access the same data in different ways, such as an order entry database whose transactions are aggregated and analyzed in a data warehouse.
A busy Internet commerce site may create multiple copies of the same database to attain horizontal scalability.
A copy of a production database may be created to serve as a development test bed.
Sometimes the relationship between multiple databases is part of a well-planned architecture, in which distributed databases are designed and implemented as such from the beginning. In other cases, though, the relationship is unforeseen; it is quite common for distributed databases to evolve as businesses expand, requirements grow, and applications spawn. But common to all cases is the need to copy or reference data in one or more remote databases.
A distributed database system will meet one or more of the following objectives:
- Availability
Data must be available at the local site even when a remote site is unreachable.
- Survivability
The failure of any single database instance must not impact the ongoing business.
- Data collection
Regional data such as sales receipts is consolidated and aggregated at a single site.
- Data extraction
A data warehouse extracts transaction records from an online transaction processing (OLTP) system.
- Decentralized data
Data may be updated in several databases.
- Maintenance
There must be support for activities such as load testing with data from production in a benchmarking database.
Oracle Corporation introduced interdatabase connectivity with SQL*Net in Oracle Version 5 and simplified its usage considerably with the database links feature in Oracle Version 6, opening up a world of distributed possibilities. Oracle now supplies a variety of techniques that you can use to establish interdatabase connectivity and data sharing. Each technique has its advantages and disadvantages, but in many cases the best solution is not immediately obvious.
Before delving into Oracle’s offerings in the distributed database systems area, I’ll clarify some terminology and concepts.
I have found thatthere is a great deal of confusion surrounding the various products and terminology from Oracle. I think it’s worthwhile to clarify some of these terms up front so you’ll get the most benefit from this book.
- Database/ database instance
These terms are often used interchangeably, but they are not the same thing. In Oracle parlance, a database is the set of physical files containing data. These files comprise tablespaces, redo logs, and control files. A database instance (or simply instance) is the set of processes and memory structures that manipulate a database.
A database may be accessed by one or more database instances, and a database instance may access exactly one database.
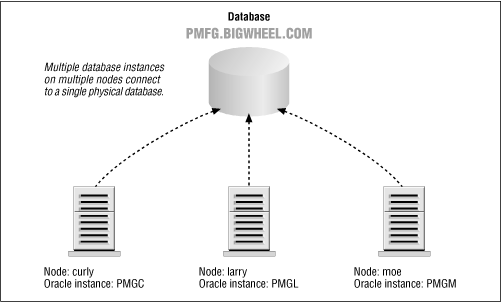
- Oracle parallel server
Oracle parallel server(OPS) is a technology that allows two or more database instances, generally on different machines, to open and manipulate one database, as shown in Figure 1.1. In other words, the physical data files (and therefore data) in a database can be seen, inserted, updated, and deleted by users logging on to two or more different instances; the instances run on different machines but access the same physical database.
Oracle parallel server requires an operating system that supports clustering and a distributed lock manager because the multiple database instances must share information about the data that is updated, the lock resources, and so on. For example, if a user on instance A updates a row, and a user on instance B performs a query that would return that row, instance B must instruct instance A to write the updated data to the physical database so that the query will deliver the updated information.
Oracle parallel server is intended to provide failover capabilities —capabilities that allow a second machine to take over the processing being performed by the first in the event of machine failure (e.g., CPU or motherboard failure). It does not provide any protection from disk failure. Occasionally, parallel server technology is used to achieve horizontal scalability, a concept I’ll discuss later in this chapter.
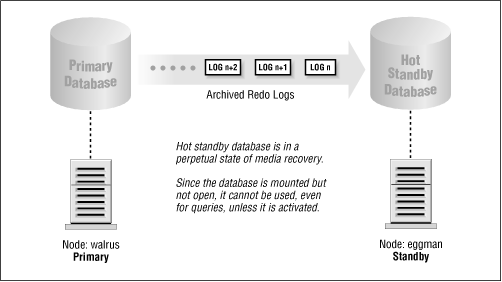
- Standby database
Oracle introduced the standby database in Version 7.2, although some sites had created their own homegrown varieties earlier. A standby database is one that shadows a normal database and is always in recovery mode. Whenever a redo log is archived in the primary database, the archived redo log is applied to the standby database, as shown in Figure 1.2. Generally, the standby database resides on a separate machine and uses separate storage.
If the primary database fails, the DBA can open the standby database and point users to it instead of to the primary database. Once this occurs, what had been the standby database becomes the primary database, and it cannot be put back into standby mode again.
- Advanced replication
A dvanced replication, also known as symmetric replication or multi-master replication , refers to maintaining a table or tables in multiple databases such that DML (Data Manipulation Language) can be issued in any of the databases and applied to the others automatically. The DML may be propagated synchronously (i.e., DML is committed locally and remotely as a single transaction) or asynchronously (i.e., DML committed locally is placed in a queue from which it is applied at the remote site later). Advanced replication can be used to deliver high availability, in the sense that the unavailability of any one site does not affect the others, or it may be used as part of a survivability policy in which every database has a replicated copy that can be used in the event of failure. Unlike parallel server, advanced replication involves numerous databases and numerous database instances.
- Parallel query
The parallel query option (PQO) is a technology that can divide complicated or long-running queries into several independent queries and allocate separate processes to execute the smaller queries. A coordinator process collects the results of the smaller queries and constructs the final result set. Parallel queries are effective only on machines that have multiple CPUs.
- Parallel DML
Oracle introduced the parallel DML feature in Oracle8. Parallel DML is similar to parallel query, except that the independent processes perform DML. For example, an update of several hundred thousand rows can be doled out to several processes that execute the update on separate ranges of the table.
Get Oracle Distributed Systems now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

