Parrot’s Architecture
The Parrot system is divided into four main parts, each with its own specific task. The diagram in Figure 5-1 shows the parts, and the way source code and control flows through Parrot. Each of the four parts of Parrot are covered briefly here, with the features and parts of the interpreter covered in more detail afterward.
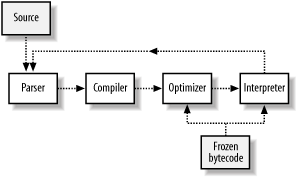
Figure 5-1. Parrot’s flow
The flow starts with source code, which is passed into the parser module. The parser processes that source into a form that the compiler module can handle. The compiler module takes the processed source and emits bytecode, which Parrot can directly execute. That bytecode is passed into the optimizer module, which processes the bytecode and produces bytecode that is hopefully faster than what the compiler emitted. Finally, the bytecode is handed off to the interpreter module, which interprets the bytecode. Since compilation and execution are so tightly woven in Perl, the control may well end up back at the parser to parse more code.
Parrot’s compiler module also has the capability to freeze bytecode to disk and read that frozen bytecode back again, bypassing the parser and compilation phases entirely. The bytecode can be directly executed, or handed to the optimizer to work on before execution. This may happen if you’ve loaded in a precompiled library and want Parrot to optimize the combination of your code and the library ...
Get Perl 6 Essentials now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

