Perl is the world’s number one solution for transforming and gluing data together, and Oracle is the world’s number one solution for storing that data. In this book we’ll explore the interface between two of the finest American inventions since baseball and pretzels. We’re going to grab that Oracle data, we’re going to flip that Oracle data, and we’re going to munge that Oracle data. And we’re going to do it all in Perl!
The goal of this book is to explore the frontier connecting the Perl and Oracle worlds, having as much fun along the way as possible. There are many routes through this largely unexplored territory, and one we think is particularly important is the one focused on Oracle database administration. We are Oracle DBAs ourselves and we know the frustrations the job can bring. We’ve found Perl an enormous help to us in performing administrative tasks — both routine ones, like adding new users to the database, and more complex ones, like monitoring database connectivity in real time and tracking down database performance problems by comparing SQL execution plans. We want to share the information we’ve acquired over the years about Perl and its many Oracle applications. We also want to give you access to our own Oracle database administration scripts, which we’ve packaged up in the Perl Database Administration (PDBA) Toolkit described in this book and freely available on the O’Reilly web site.
This chapter sets the scene by introducing you to Perl and how it connects to Oracle. We’ll look at the following:
- Perl’s origins and advantages
We’ll take a look at where Perl came from and what makes it such a popular and powerful language.
- Perl/Oracle architecture
We’ll see how Perl connects to the Oracle database via the Perl DBI module, the DBD::Oracle program, and Oracle’s own OCI product. These modules interact to allow Perl programs access to Oracle databases.
- Perl for Oracle DBAs
We’ll discuss why Perl is a particularly appropriate language for Oracle DBAs to learn and use.
We’ll also provide a list of additional Perl resources.
Perl is a wonderful language with a rich history and culture. Many books have been written about its capabilities and roots. In this book we’ll be focusing on how Perl and Oracle work together, and we’ll only skim the surface of Perl’s overall capabilities, giving you just enough detail so you’ll appreciate what Perl can do for you.
In a nutshell, Perl is a freely available interpreted scripting language that combines the best capabilities of a variety of other languages. Despite borrowing other language capabilities, the whole of Perl is far greater than the sum of its parts. Perl was designed especially to be:
Extremely fast, in order to be useful when scanning through large files
Especially good at text handling, because data comes in many different forms and Perl has to handle them all
Extensible, in order for Perl to expand users’ horizons, not restrict them
A tutorial for basic Perl is outside the scope of this book. Fortunately, there are many excellent web sites and books containing the information you need to get going. We’ve collected references to what we consider to be the best Perl books and online documentation in Section 1.4 at the end of this chapter. The appendixes provide quick references to different aspects of Perl’s capabilities. For online information, check out the main Perl portals at:
| http://www.perl.com |
| http://www.perl.org |
| http://www.activestate.com (for Win32) |
Before we get into the details of how Perl and Oracle interact, let’s take a step back to look at where Perl came from.
Larry Wall created Perl back in 1987 with the goal of making “the easy things easy and the hard things possible” — originally just for himself, but ultimately for a whole generation of developers. Larry had been working on a complex system and had been trying to get Unix’s awk utility to do his bidding. He finally gave up on it and under the auspices of a secret project for the National Security Agency known as the “Blacker,” he decided to create a new language by raiding a primeval soup of technologies and splicing together the genetic structures of awk, sed, sh and C, as well as csh, Pascal, and BASIC. The first release of Perl, Perl 1.0, arrived after a nine-month gestation period.
Perl was unlike any other computer language that had come before it, and this sea change was partially reflected in the name. The original name, “Pearl,” stood for “Practical Extraction And Report Language,” but in the spirit of this compact language, Larry wanted to save typing that extra fifth character. The name quickly morphed into Perl, which by now also stood for “Pathologically Eclectic Rubbish Lister.” This self-irreverence further distinguished the language and gave it a certain counter-culture cachet.
Perhaps the most accurate summary of what Perl is best for can be found in the README file written by its author for Perl Version 1.0:
Perl is a interpreted language optimized for scanning arbitrary text files, extracting information from those text files, and printing reports based on that information. It’s also a good language for many system management tasks. The language is intended to be practical (easy to use, efficient, complete) rather than beautiful (tiny, elegant, minimal). It combines (in the author’s opinion, anyway) some of the best features of C, sed, awk, and sh, so people familiar with those languages should have little difficulty with it. (Language historians will also note some vestiges of csh, Pascal, and even BASIC|PLUS.) Expression syntax corresponds quite closely to C expression syntax. If you have a problem that would ordinarily use sed or awk or sh, but it exceeds their capabilities or must run a little faster, and you don’t want to write the silly thing in C, then perl may be for you. There are also translators to turn your sed and awk scripts into perl scripts. OK, enough hype.
The Unix world embraced the Perl language, and the fast-growing Perl development community gradually built their favorite language into the world’s supreme text-processing engine. Over the next few years, Perl grew ever more powerful. Perl’s regular expression handling was enhanced, the ability to handle binary files was added to the language, and the three main variable types were honed and sculpted. Soon the Perl Artistic License was adopted, and with the publication of the first edition of Programming Perl, the definitive guide to the language, the camel became the Perl trademark.[3]
Perl has become hugely popular, largely because of its extremely fast text processing and its ability to glue difficult things together with ease. With the explosion of the interactive Internet in the 1990s, Perl found itself superbly pre-adapted to become the new tool of an Internet generation. It glued those trillions of text packets into one big global village! And as the World Wide Web burst on the scene, Perl continued to evolve, emerging as the premier language for developing web applications. Perl 4 brought the release of modules allowing Perl to interact with Oracle (and other) databases. The current version of Perl, Perl 5, contains long-sought object-oriented features.
Although Perl’s origins were in the Unix world, it was ported to Windows back in 1995 by Dick Hardt and Hip Communications, the forerunners of ActiveState. Windows NT administrators then discovered a whole new world of functionality via the Win32 modules supplied by ActiveState, and Perl became their dominant scripting language. Perl was a lifesaver for busy administrators performing large NT system updates. (Adding 100 users to a system via the repetitive and arthritic point-and-click method really is no fun!)
Win32 Perl became so popular that there was some danger that the Unix and Windows versions would diverge. But Larry Wall was not about to let this happen. Those not familiar with Perl may wonder why it matters. What difference would it make if the Unix and Win32 Perls were different? In fact, it is this hard-won unity that gives Perl its power. You can write a single script on one operating system, and as long as you don’t use native methods, you can run it unchanged on every other kind of machine, from Linux to Windows NT to Solaris and back again. That is a huge advantage in our multiplatform, networked computing world.
Over the years, an enthusiastic and partisan army of Perl volunteers has extended Perl in a myriad of ways. CPAN (the Comprehensive Perl Archive Network), an online repository of Perl core files, documentation, and contributed modules, has become a model for an open source development community. Check out:
| http://www.cpan.org |
Literally thousands of Perl modules are now available on CPAN, providing virtually any application you can imagine — and many you haven’t yet imagined. Just about every Perl module we describe in this book, from core modules like Perl and Perl DBI themselves to Oracle-specific database administration scripts like OraExplain and Orac, can be downloaded from CPAN.
New Perl modules go through an evolutionary process that begins with an individual developer’s code, which he or she posts to CPAN. As others learn about the new module and start downloading and testing it, and relying upon it, it becomes more and more acceptable. If it’s good enough, and if enough people and products rely upon it, the Perl gods ultimately might decide to include the new module in the next general Perl distribution.
When Java, Microsoft’s Active Server Pages (ASP), and similar corporate tools came along, many people assumed that they would sweep the inelegant Perl away. However, this hasn’t come to pass. Instead, Perl has grown exponentially both in market share and stature, especially since its 1994 Perl 5 adoption of reference technology, which greatly increased its scope in terms of both extensibility and object orientation. Tim Bunce’s Perl DBI module, built on the object-oriented base, gave Perl the ability to interface with Oracle and other databases. The fact that Perl can now dynamically glue the Internet to the database has greatly increased corporate acceptance of the language.
There are nearly as many reasons why people choose to use Perl as there are people who use Perl. Aside from the language’s specific capabilities, we think there are a few key reasons for Perl’s awesome acceptance among programmers and nonprogrammers alike:
- Practicality
Unlike some languages that have developed within the ivory towers of computer science departments, Perl is a practical language. It is unbound by dogma and driven by day-to-day practicalities. With its flexible syntax, it gives users enormous freedom to do what they want to do.
- Bandwidth
Perl is one of the most concise languages around. In ten lines of Perl code, you can achieve more than is possible in any other language. Disciplined use of Perl can thus reduce program maintenance costs (because there’s less to maintain) and aid clarity (because there’s less code to try to understand).
- Range
Literally thousands of Perl modules are available for download from CPAN, covering virtually every computing requirement imaginable. The abundance of prebuilt code modules makes Perl the number one choice for anyone with a wide range of programming needs — and that description fits most Oracle DBAs.
We believe that Perl’s popularity is based to a large extent on the fact that it has resisted the temptation to try to become the most elegant language of its time. A linguist by training, Larry Wall took many lessons from the development of real-world natural human languages, and blended the necessary messiness of those languages into his evolving design for Perl. In the following sections we’ll look at how the English language itself offers some important Perl analogies.
Although natural languages such as English are difficult and messy, even a baby can learn them. The messiness of such languages aids learning, develops expression, and allows the human mind to map complex real-world problems onto the symbolic logic of complex real-world languages. Perl tries to follow this pattern — it’s very intentionally designed for humans rather than computers. You need only a little Perl to get going, just as a baby needs only a little language to ask for a chocolate ice cream. Indeed most of the fun of Perl is that you never stop learning about its new elements. This characteristic of Perl contrasts with some other languages where you have to learn virtually the entire shooting match before you can do the simplest thing, such as print:
"Hello World! :-)"
It also means that it’s okay to know only parts of the whole language — every Perl programmer is on the same flat learning curve as every other Perl programmer, merely at a different position.
Perl is optimized for expressive power, rather than ease of operation. Once you’ve learned an element of Perl, such as the structure of hashes (described in Appendix A), you can use this knowledge in many different ways to achieve many different ends. Again, this is similar to English, in which you can learn a rhetorical debating technique and then employ it in many different ways to get what you want.
In many computer languages, there’s often a single acceptable way to do a certain thing — for example, communicate with a distant server. Perl is different. So is English. In real life, when you introduce yourself to other people, there are many different ways to successfully perform this occasionally tricky verbal task. It’s the same in Perl. What counts is what works best for you, not some rigid adherence to a strictly enforced protocol. As with formal introductions, of course, there are certain conventions that most people use. There is peer pressure even among Perl programmers. But Perl itself doesn’t care; if you want to do something different, you are free to do so.
English is a successful language mainly because it looks forward into the future, rather than backward towards its origins. It’s built up from Latin, Greek, French, Anglo-Saxon, and many other elements. And if it needs to borrow the word “veranda” from the Portuguese in order to describe a covered porch, it just goes right ahead without worrying about whether doing so breaks some rule. Perl is the same: if it sees a great idea in Java, it just goes right ahead and borrows it, slipping it in so the join is invisible. Eventually, if it’s a successful graft, even Java programmers may come to think that the idea originally came from Perl. It is this continuous evolution that transforms Perl from the ordinary into the extraordinary.
English is also successful because it’s so good at handling ambiguity. Although there are few cases, genders, or definitive word endings in the English language, local ambiguities are quickly resolved by the juxtaposition of certain other words, conventions, and punctuation. Perl is the same: some pieces of isolated code can be quite ambiguous, but the ambiguity is quickly resolved in the context of its word order, punctuation, and relationship to other code fragments. There are even pronouns in Perl, such as $_ and @_ for “it” and “they”!
In a pure computer language world, you could visit the local cinema in an infinite number of ways; for example, you could float up to 10,000 feet, disappear, and then rematerialize in your favorite seat to watch The Lord of the Rings. But the fact is that you’d most often walk or drive there. Similarly, Perl recognizes that most people tend to want to do things in familiar ways (e.g., opening a file, processing the lines in it, and then closing the file). So Perl will typically assume that you’ll be following a natural order unless you tell it explicitly that you won’t be.
Lawyers have taken the once straightforward English language and twisted it into the most tortuous logic the human mind could devise — unfortunately, this is the route most often taken by other computer languages. They start simply enough, but develop a rigid straitjacket of theoretical perfection before drowning in a bog of complexity. You’ll be pleased to hear that Perl is much friendlier. There is no ideology that must be obeyed. A country run by Perl programmers would be a really cool place to live!
Natural languages have evolved with the involvement of different people over a long period of time — indeed, they continue to evolve. They’re also continuously diverging into separate dialects and even other languages. Perl too began as an amalgam of different ideas, shepherded together by Larry Wall. It has since continued as a cooperative effort, with many contributing voices. The eventual creation of Perl 6 will be one vast community effort (something we hope you’ll be part of).
But language fragmentation has been an ongoing problem for Perl. The solution has been a continuous release program over the last decade that has accommodated divergent tendencies. The CPAN architecture also offers a outlet for those with independent voices. The threatened Win32 divergence we discussed earlier in the Section 1.1.1.1 could have had a dramatic impact on the unity of Perl — and all that implies in terms of portability and extensibility. Thankfully, as we described earlier, that threat came to a happy conclusion. And it’s still true that if you write a Perl script on one operating system, then as long as you haven’t used native methods and system commands, the script can be copied to any other machine and will work there identically, regardless of operating system.
How do Oracle DBAs, developers, and users take advantage of everything that Perl has to offer? The architecture illustrated in the figures in the following sections show how the various Perl and Oracle modules fit together to make the Perl/Oracle connection clean and efficient. In the following sections we’ll take a look at the main components of this architecture:
Perl DBI
DBD::Oracle
OCI
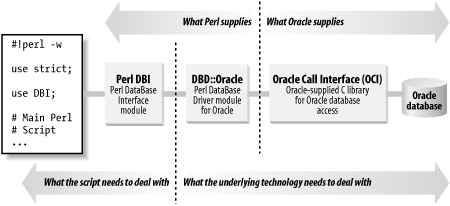
Perl DBI and DBD::Oracle are Perl modules available from CPAN. OCI is an Oracle Corporation product that comes with all versions of the Oracle database.
Perl DBI is a generic application programming interface (API). It is similar in concept to ODBC (Oracle DataBase Connectivity) and JDBC (Java DataBase Connectivity), but it has a Perl-based object-oriented architecture. Perl DBI’s object-oriented architecture allows it to have a single routing point to many different databases (shown in Figure 1-1), each via a database-specific driver. Oracle uses the DBD::Oracle driver, another Perl module that provides the actual communication to the low-level OCI code. It is OCI that makes the final connection to the Oracle database.
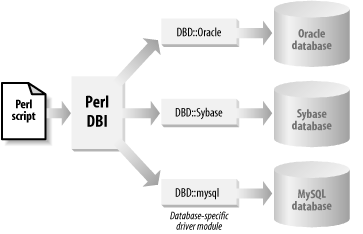
The beauty of Perl DBI is you can forget the details of the necessary connections beneath its simple API calls. The DBI package glides serenely over the surface of our databases, while the driver module, DBD::Oracle, does all the hard paddling beneath the surface.
Figure 1-2 shows how all the modules fit together on the Perl and Oracle sides.
The origins of Perl DBI date back more than a decade. Way back in 1991, an Oracle DBA, Kevin Stock, created a database connection program called OraPerl that was released for Perl 4. Over time, similar Perl 4 programs appeared, such as Michael Peppler’s Sybperl, designed for communication with the Sybase database. In a parallel development, starting around September of 1992, a Perl-based group was working on a specification for DBPerl, a database-independent specification for Perl 4. Within two years they were just ready to start implementing DBPerl when Larry Wall started releasing the alpha version of the object-oriented Perl 5. Taking advantage of both Perl 5 and the earlier Call Level Interface (CLI) work from the SQL Access Group, the DBPerl team relaid the foundations of Perl DBI within an object-oriented framework, creating this new architecture in a similar form to that employed by the familiar API of ODBC. Meanwhile, Tim Bunce wrote an emulation layer for OraPerl Version 2.4 that let people easily move their legacy Perl 4 OraPerl scripts over to Perl 5 and Perl DBI.
With the new DBI architecture, you could now transparently employ just one Perl module to connect to every type of database, as long as you had the right driver. Fortunately for Oracle DBAs, Tim Bunce, the main creator of Perl DBI, is also the main creator of DBD::Oracle, which automatically keeps Oracle on the cutting edge of Perl DBI’s development schedule.
We won’t try to describe all of the capabilities of Perl DBI here, but Table 1-1 provides a summary of the main calls (e.g., DBI class methods) to OCI. For additional background information about Perl DBI, see Appendix B. And for much more information, consult the references listed under Section 1.4.2 at the end of this chapter.
Table 1-1. Main Perl DBI functions
As we’ve said, Oracle Corporation’s Oracle Call Interface (OCI) is the component in the Perl/Oracle architecture that makes the final connection to the Oracle database servers. This C-based API provides a comprehensive library used to connect into Oracle from the external world. Use of OCI lets your Perl programs take advantage of the following OCI capabilities:
High performance
Security features, including user authentication
Scalability
N-tiered authentication
Full and dynamic access to Oracle objects
User session handles
Multi-threaded capabilities
Support for accessing special Oracle datatypes such as LOBs (large objects)
Transactions
Dynamic connection and session management
Asynchronous event notification
Access to other databases
Full character set support
For more about OCI, see Chapter 7, where we describe Oracle::OCI, a new Perl module that provides an even closer interface between Perl and Oracle. You can get complete information about OCI at Oracle Corporation’s http://technet.oracle.com pages; in particular, see http://technet.oracle.com/tech/oci/.
In Table 1-2 we list the main OCI functions to give you a sense of the kinds of Oracle operations you can invoke from your Perl programs.
Table 1-2. Main OCI functions
|
OCI function |
Description |
|---|---|
|
OCIAttrSet( ) |
Sets handle attributes |
|
OCIAttrGet( ) |
Gets attributes from a handle |
|
OCIBindByName( ) |
Links variables to a SQL statement placeholder by name |
|
OCIBindByPos( ) |
Links variables to a SQL statement placeholder by position |
|
OCIDefineByPos( ) |
Links a typed select-list item with the output data buffer |
|
OCIDescribeAny( ) |
Describes schema objects |
|
OCIDescriptorAlloc( ) |
Allocates storage for descriptors and LOB locators |
|
OCIDescriptorFree( ) |
Releases the resources taken by descriptors |
|
OCIEnvInit( ) |
Allocates the initial OCI environment handle |
|
OCIErrorGet( ) |
Returns a buffered error message |
|
OCIHandleAlloc( ) |
Points to an allocated handle |
|
OCIHandleFree( ) |
Explicitly releases a memory handle and its resources |
|
OCIInitialize( ) |
Initializes the environment for OCI processes |
|
OCILobRead( ) |
Reads specified LOB and FILE portions into a buffer |
|
OCILobWrite( ) |
Writes a specified buffer into a LOB |
|
OCILogoff( ) |
Ends a login session |
|
OCILogon( ) |
Logs into the OCI session |
|
OCIParamGet( ) |
Gets the descriptor of a parameter attached to a statement handle |
|
OCIParamSet( ) |
Puts the object retrieval descriptor into an object retrieval handle |
|
OCIServerAttach( ) |
Creates the pathway to a data source |
|
OCIServerDetach( ) |
Detaches from a data source |
|
OCISessionBegin( ) |
Begins a user session for a given server |
|
OCISessionEnd( ) |
Ends a user session |
|
OCIStmtExecute( ) |
Sends an application request to the server |
|
OCIStmtFetch( ) |
Fetches data rows from previous queries |
|
OCIStmtPrepare( ) |
Prepares a SQL statement for later execution |
|
OCITransCommit( ) |
Commits a nominated transaction |
At the most basic level, virtually all outside programs — from web applications to standalone GUI applications — interact with Oracle through this OCI program layer. Fortunately, the OCI libraries are automatically available in every Oracle database installation, so no special installation process is required. You’ll generally discover the appropriate files under the $ORACLE_HOME/lib and $ORACLE_HOME/include directories, on Unix systems, and under %ORACLE_HOME%\lib and %ORACLE_HOME%\include on Win32.
Perl has become an increasingly popular tool for Oracle DBAs who need a quick way of handling the 101 different jobs a DBA is expected to do every day. Perl is operating system-independent, powerful, flexible, remarkably quick to code, and extremely fast in execution. These capabilities are especially important if you are working in a rapidly changing environment where one day you might be populating a data warehouse from a difficult data source, and the next you might be generating all of the information for a dynamic web application — and the whole time you’re performing all of your usual administrative tasks. That certainly describes the diverse world of an Oracle DBA!
Of course, the focus of any Oracle site’s business is data. And from the start, Perl was designed to be a data-processing engine, perhaps the finest and quickest in the world. It can find data, clean data, parse data, substitute data, print data, eat data, and spit data out from the other end in the exact format you require. It can do all of this with text data, binary data, and network data.
There are a variety of ways that Oracle DBAs can combine the power of Perl and Oracle. We describe four main paths in this book; the following list provides a road map:
- Existing modules and applications
All kinds of excellent Perl modules and complete open source applications are freely available for Oracle DBAs to use. The chapters in Part II of this book describe the Perl/Oracle applications that we consider the best of the bunch; these are listed in Table 1-3 and fall into several categories:
- Perl GUI applications
In Chapter 3, we describe Perl/Tk, Perl’s own tookit for developing graphical user interfaces, along with a variety of graphical Oracle applications and helper modules: OraExplain, StatsView, Orac, DDL::Oracle, SchemaDiff, Senora, DBD::Chart, SchemaView-Plus, as well as some Perl GUI integrated development environments (IDEs) and debuggers.
- Perl web-based applications
In Chapter 4, we discuss the use of Apache with Perl and Oracle and describe two particular applications, Oracletool and Karma. In Chapter 5 we show how using the Apache mod_perl module can greatly improve the performance of Perl web-based scripts. And in Chapter 6, we discuss two embedded Perl web scripting applications, Embperl and Mason.
- Connectivity tools
In Chapter 2, we describe how to install Perl DBI and DBD::Oracle to allow your Perl programs to interact with Oracle databases with great ease and efficiency. Later chapters describe some additional connectivity tools. In Chapter 7 we describe the new Oracle::OCI module that provides higher performance and a true one-to-one mapping with functions of the Oracle Call Interface. In Chapter 8, we describe Perl’s extproc_perl, Oracle’s EXTPROC, and the other modules that allow Perl to be essentially embedded into Oracle’s own PL/SQL language.
- Database administration scripts
Just about every Oracle DBA has his or her own set of scripts they’ve written to make their daily lives easier. Many of these DBAs have been kind enough to share the wealth with their peers. Following this trend, we’ve packaged up our own set of scripts and modules into an open source collection we call the PDBA Toolkit. As a side benefit, the toolkit provides us with a living breathing entity whose code we can use to illustrate the use of Perl. We describe this toolkit in Part III of this book.
- Data-processing scripts
Many Oracle DBAs spend at least part of their time dealing with data warehousing as well as database administration. They often need to clean and transform data that originates in other databases and applications and is now destined for Oracle. Perl, with its regular expressions and high performance, is one of the best solutions around for preparing data for use in data warehouse applications. Data munging is the term used to describe the data cleaning, formatting, and transformation often required by data warehouses. Appendix C, provides an essential guide to Perl regular expressions, and Appendix D, summarizes the many Perl modules available to perform data-processing and data-munging operations on all kinds of data, including numeric, text, date, and XML formats.
- Custom scripts
Helpful as all of these packaged solutions may be, DBAs often find it necessary to write their own custom queries and scripts to solve their immediate problems. Every DBA ends up needing to write quick 5- or 10-line ad hoc programs simply to glue things together in their databases. They also may find that the canned applications and tools available for Oracle are great, but not quite right for their needs. The nice thing about Perl is that it makes it easy for you to add, change, or customize. All of the applications we describe throughout this book are available in source form so you can modify them to suit your needs. Our own toolkit is designed specifically to accommodate such customization. The modular nature of the scripts, coupled with the documentation provided in Part III of this book (see Chapter 13, in particular) should make it easy for you. You’ll also find the appendixes helpful in learning the basics of Perl.
Table 1-3 lists all of the applications and tools mentioned in this book. We tried to include the most up-to-date information possible in this book at the time of publication, but because most of these programs are continually being enhanced, make sure to check out the sites listed in the table for current information.
Table 1-3. Perl/Oracle applications and related tools
We’ve collected what we consider to be the best online and offline resources for Perl in the following sections. If you run into problems or just want to expand your horizons, do check out the books, web sites, and mailing lists summarized here.
Appendix A summarizes the essential elements of Perl’s syntax, up to and including its object orientation. It also provides a full guide to the use of the very helpful perldoc command, which is the best way to access online manual page information on Perl once it has been installed.
The following web sites provide good springboards into the world of Perl:
- http://www.perl.com
Contains everything you ever wanted to know about Perl.
- http://www.perl.org
Another central resource for Perl users.
- http://learn.perl.org
Site dedicated to people fresh to Perl.
-
http://history.perl.org
http://www.wall.org Information on the history of Perl.
One of the wonderful benefits of open source tools like Perl is the large number of people out there willing to help you. There are literally hundreds of Perl mailing lists to choose from. Fortunately, there is one site for keeping tabs on all of them:
- http://lists.perl.org
An excellent central resource for tracking down virtually every kind of Perl mailing list you could possibly think of.
- beginners-subscribe@perl.org
Send a blank email here to get attached to the Perl beginners’ mailing list.
- beginners@perl.org
Once registered, you can post your questions here.
- beginners-unsubscribe@perl.org
When you’re ready to move on to other lists, you can unsubscribe by sending another blank email to the preceding address.
- http://archive.develooper.com
Before posting any questions, you may want to check the Perl archive first.
There are enough books on Perl to fill the capacious saddles of several very large camels. Here we’ll list just a few of our favorite general texts.
- http://www.oreilly.com/catalog/lperl3 (the Llama book)
Learning Perl, by Randal L. Schwartz and Tom Christiansen, 3rd ed. (O’Reilly & Associates, 2001)
- http://www.oreilly.com/catalog/lperlwin (the Gecko book)
Learning Perl on Win32 Systems, by Randal L. Schwartz, Erik Olson, and Tom Christiansen (O’Reilly & Associates, 1997)
- http://www.oreilly.com/catalog/pperl3 (the Camel book)
Programming Perl, by Larry Wall, Tom Christiansen, and Jon Orwant, 3rd ed. (O’Reilly & Associates, 2000)
- http://www.roth.net/books/extensions2
Win32 Perl Programming: The Standard Extensions, by Dave Roth, 2nd ed. (New Riders Publishing, 2001)
- http://www.oreilly.com/catalog/perlnut
Perl in a Nutshell, by Ellen Siever, Stephen Spainhour, and Nathan Patwardhan (O’Reilly & Associates, 1998)
- http://www.oreilly.com/catalog/advperl (the Panther book)
Advanced Perl Programming, by Sriram Srinivasan (O’Reilly & Associates, 1997)
- http://www.effectiveperl.com (the Shiny Ball book)
Effective Perl Programming: Writing Better Programs with Perl, by Joseph N. Hall (Addison-Wesley, 1998)
- http://www.oreilly.com/catalog/regex (the Owls book)
Mastering Regular Expressions: Powerful Techniques for Perl and Other Tools, by Jeffrey Friedl (O’Reilly & Associates, 1997)
- http://www.manning.com/Conway/index.html (the Renaissance book)
If you want to learn more about Perl DBI, first check out Appendix B. It’s likely you’ll need more detailed information, however, if you’re planning to do anything complex. Here are some recommended resources.
The following sites are the best places to go for more information:
- http://dbi.perl.org
Central home page for the Perl DBI project and the best place to start
- http://dbi.perl.org/doc/faq.html
Central FAQ for Perl DBI
The DBI Users mailing list is the information backbone for the entire DBI community, and you’ll find a great deal of help available there. However, it’s generally considered good form if you at least search the DBI FAQ located at http://dbi.perl.org/doc/faq.html, and possibly the following mail archives, before posting any new questions:
- http://lists.perl.org/showlist.cgi?name=dbi-users
The folks at perl.org maintain the DBI Users mailing list, and you can register yourself with them at this web address.
- dbi-users-subscribe@perl.org
To subscribe to the mailing list, send an empty email here.
- dbi-users@perl.org
Once you’ve been successfully registered by http://perl.org, you can post your Perl DBI questions and comments via this email link.
- dbi-users-unsubscribe@perl.org
To unsubscribe from the mailing list, post an empty email here.
- http://archive.develooper.com/dbi-users@perl.org
The main archive attached to the central DBI Users mailing list, organized by date and threaded topic.
- http://www.xray.mpe.mpg.de/mailing-lists/dbi
Another searchable archive for the DBI mailing list. Again, you may want to search through this archive before posting any new mailing list questions.
Two O’Reilly books complement the one you’re reading right now. The first contains much more detail on the Perl DBI API; the second also describes Perl DBI, as well as many other open source technologies (including Tcl and Python) and their parallel use of OCI:
- http://www.oreilly.com/catalog/perldbi
Programming the Perl DBI: Database Programming with Perl, by Alligator Descartes and Tim Bunce (O’Reilly & Associates, 2000).
- http://www.oreilly.com/catalog/oracleopen
Oracle & Open Source: Tools and Applications, by Andy Duncan and Sean Hull (O’Reilly & Associates, 2001).
[3] The camel is a great image for Perl because it suggests a horse designed by more than one voice — perhaps a bit challenged in looks, but perfectly adapted for a difficult ecological niche.
Get Perl for Oracle DBAs now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

