April 2013
Intermediate to advanced
115 pages
2h 42m
English
HTTP stands for HyperText Transfer Protocol, and is the basis upon which the Web is built. Each HTTP transaction consists of a request and a response. The HTTP protocol itself is made up of many pieces: the URL at which the request was directed, the verb that was used, other headers and status codes, and of course, the body of the responses, which is what we usually see when we browse the Web in a browser.
When surfing the Web, ideally we experience a smooth journey between all the various places that we’d like to visit. However, this is in stark contrast to what is happening behind the scenes as we make that journey. As we go along, clicking on links or causing the browser to make requests for us, a series of little “steps” is taking place behind the scenes. Each step is made up of a request/response pair; the client (usually your browser or phone if you’re surfing the Web) makes a request to the server, and the server processes the request and sends the response back. At every step along the way, the client makes a request and the server sends the response.
As an example, point a browser to http://oreilly.com/ and you’ll see a page that looks something like Figure 1-1; either the information desired can be found on the page, or the hyperlinks on that page direct us to journey onward for it.
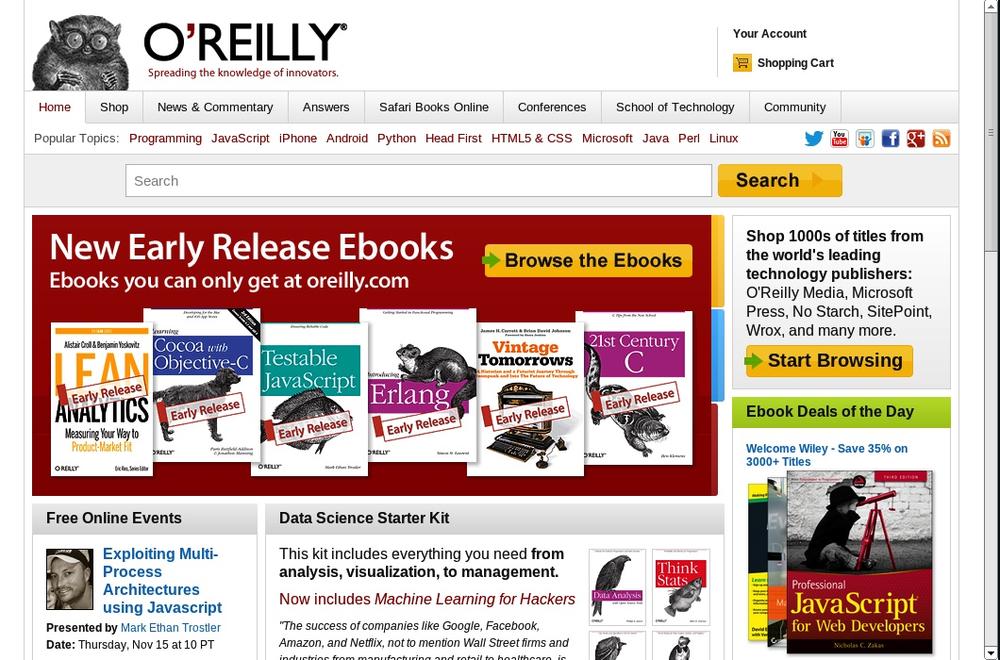
The web page arrives in the body of the HTTP response, ...
Read now
Unlock full access






