This chapter provides an introduction to computer vision in general, and the SimpleCV framework in particular. The primary goal is to understand the possibilities and considerations to keep in mind when creating a vision system. As part of the process, this chapter will cover:
The importance of computer vision
An introduction to the SimpleCV framework
Hard problems to solve with computer vision
Problems that are relatively easy for computer vision
An introduction to vision systems
The typical components of a vision system
As cameras are becoming standard PC hardware and a required feature of mobile devices, computer vision is moving from a niche tool to an increasingly common tool for a diverse range of applications. Some of these applications probably spring readily to mind, such as facial recognition programs or gaming interfaces like the Kinect. Computer vision is also being used in things like automotive safety systems, where a car detects when when the driver starts to drift from the lane or is getting drowsy. It is used in point-and-shoot cameras to help detect faces or other central objects to focus on. The tools are used for high tech special effects or basic effects, such as the virtual yellow first-and-ten line in football games or the motion blurs on a hockey puck. It has applications in industrial automation, biometrics, medicine, and even planetary exploration. It’s also used in some more surprising fields, such as agriculture, where it is used to inspect and grade fruits and vegetables. It’s a diverse field, with more and more interesting applications popping up every day.
At its core, computer vision is built upon the fields of mathematics, physics, biology, engineering, and of course, computer science. There are many fields related to computer vision, such as machine learning, signal processing, robotics, and artificial intelligence. Yet even though it is a field built on advanced concepts, more and more tools are making it accessible to everyone from hobbyists to vision engineers to academic researchers.
It is an exciting time in this field, and there are an endless number of possibilities for applications. One of the things that makes it exciting is that these days, the hardware requirements are inexpensive enough to allow more casual developers to enter the field, opening the door to many new applications and innovations.
SimpleCV, which stands for Simple Computer Vision, is an easy-to-use Python framework that bundles together open source computer vision libraries and algorithms for solving problems. Its goal is to make it easier for programmers to develop computer vision systems, streamlining and simplifying many of the most common tasks. You do not have to have a background in computer vision to use the SimpleCV framework, or a computer science degree from a top-name engineering school. Even if you don’t know Python, it is a pretty easy language to learn. Most of the code in this book will be relatively easy to pick up, regardless of your programming background. What you do need is an interest in computer vision, or helping to make computers “see.” In case you don’t know much about computer vision, we’ll give you some background on the subject in this chapter. Then in the next chapter, we’ll jump into creating vision systems with the SimpleCV framework.
Vision is a classic example of a problem that humans handle well, but with which machines struggle. The human eye takes in a huge amount of visual information, and then the brain processes it all without any conscious thought. Computer vision is the science of creating a similar capability in computers and, if possible, to improve upon it. The more technical definition, though, would be that computer vision is the science of having computers acquire, process, and analyze digital images. The term machine vision is often used in conjunction with computer vision. Machine vision is frequently defined as the application of computer vision to industrial tasks.
One of the challenges for computers is that humans have a surprising amount of “hardware” for collecting and deciphering visual data. Most people probably haven’t spent much time thinking about the challenges involved in sight. For instance, consider what is involved in reading a book. While the eye is capturing the visual input, the brain needs to distinguish between data that represents the book and that which is merely background data to be ignored. One of the ways to do this is through depth perception, which is reinforced by several systems in the body:
Eye muscles that can determine distance based on how much effort is exerted to bend the eye’s lens.
Stereo vision that detects slightly different pictures of the same scene, as seen by each eye. Similar pictures mean the object is far away, while different pictures mean the object is close.
The slight motion of the body and head, which creates the parallax effect. This is the effect where the position of an object appears to move when viewed from different positions. Because this difference is greater when the object is nearby and smaller when the object is further away, the parallax effect helps estimate the distance to an object.
After the brain has focused on the book, the next step is to process
the marks on the page into something useful. The brain’s advanced pattern
recognition system has been taught which of the black marks on this page
represent letters and how the letters group together to form words. While
certain elements of reading are the product of education and training,
such as learning the alphabet, the brain’s pattern matching is also able
to map words written in several
different fonts
back to that original alphabet (Wingdings notwithstanding).
Take the above challenges of reading, and then multiply them with the constant stream of information through time, with each moment possibly including various changes in the data. Hold the book at a slightly different angle (or tip the e-reader a little bit). Hold it closer or further away. Turn a page. Is it still the same book? These are all challenges that are unconsciously solved by the brain. In fact, one of the first tests given to babies is whether their eyes can track objects. A newborn baby already has a basic ability to track an object, but computers struggle with the same task.
That said, there are quite a few things that computers can do better than humans:
Computers can look at the same thing for hours and hours. They don’t get tired or bored.
Computers can quantify image data in a way that humans cannot. For example, computers can measure dimensions of objects very precisely and look for angles and distances between features in an image.
Computers can see places in a picture where the pixels next to each other have very different colors. These places are called “edges,” and computers can tell exactly where edges are and quantitatively measure how strong they are.
Computers can see places where adjacent pixels share a similar color and provide measurements on shapes and sizes. These are often called “connected components”—or more colloquially—“blobs.”
Computers can compare two images and see very precisely the difference between them. Even if something is moving imperceptibly for hours—a computer can use image differences to measure how much it changes.
Part of the practice of computer vision is finding places where the computer’s eye can be used in a way that would be difficult or impractical for humans. One of the goals of this book is to show how computers can be used in these cases.
In many ways, computer vision problems mirror the challenges of using computers in general: computers are good at computation, but weak at reasoning. Computer vision is effective for tasks such as measuring objects, identifying differences between objects, finding high contrast regions, and so on. These tasks all work best under conditions of stable lighting. Computers struggle when working with irregular objects, classifying and reasoning about an object, and tracking objects in motion. All of these problems would also compounded by poor lighting conditions or moving elements.
For example, consider the image shown in Figure 1-1. What is it a picture of? A human can easily identify it as a bolt. For a computer to make that determination, it will require a large database with pictures of bolts, pictures of objects that are not bolts, and computation time to train the algorithm. Even with that information, the computer may regularly fail, especially when dealing with similar objects, such as distinguishing between bolts and screws.

However, a computer does very well at tasks such as counting the number of threads per inch. Humans can count the threads as well, of course, but it would be a slow and error prone, not to mention headache inducing, process. In contrast, it is relatively easy to write an algorithm that detects each thread. Then it is a simple matter of computing the number of those threads in an inch. This is an excellent example of a problem prone to error when performed by a human, but easily handled by a computer.
Some other classic examples of easy versus hard problems are listed in Table 1-1.
Table 1-1. Easy and hard problems for computer vision
| Easy | Hard |
|---|---|
How wide is this plate? Is it dirty? | Look at a picture of a random kitchen, and find all the dirty plates. |
Did something change between these two images? | Track an object or person moving through a crowded room of other people. |
Measure the diameter of a wheel. Check to see if it is bent. | Identify arbitrary parts on pictures of bicycles. |
What color is this leaf? | What kind of leaf is this? |
Furthermore, all of the challenges of computer vision are amplified in certain environments. One of the biggest challenges is the lighting. Low light often results in a lot of noise in an image, requiring various tricks to try to clean up the image. In addition, some types of objects are difficult to analyze, such as shiny objects that may be reflecting other objects in their surroundings.
Note that hard problems do not mean impossible problems. The later chapters of this book look at some of the more advanced features of computer vision systems. These chapters will discuss techniques such as finding, identifying, and tracking objects.
A vision system is something that evaluates data from an image source (typically a camera), extracts data about those images, and does something with the results. For example, consider a parking space monitor. This system watches a parking space, and detects parking violations in which unauthorized cars attempt to park in the spot. If the owner’s car is in the space or if the space is empty, then there is no violation. If someone else is parked in the space, then there is a problem. Figure 1-2 outlines the overall logic flow for such a system.
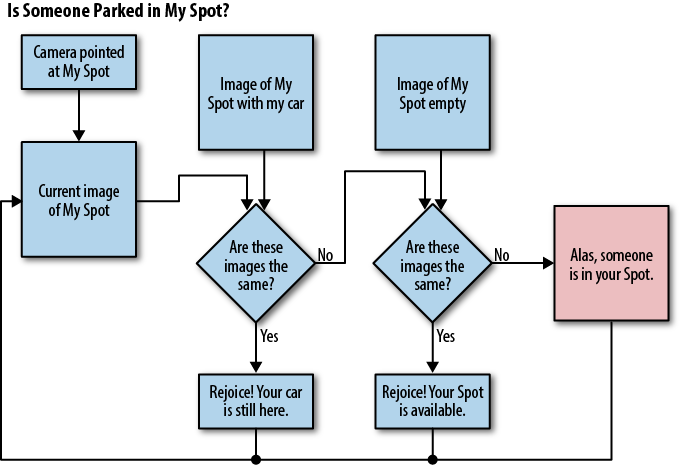
Although conceptually simple, the problem presents many complexities. Lighting conditions affect color detection and the ability to distinguish the car from the background. The car may be parked in a slightly different place each time, hindering the detection of the car versus an empty spot. The car might be dirty, making it hard to distinguish between the owner’s and the violator’s cars. The parking spot could be covered in snow, making it difficult to tell whether the parking spot is empty or not.
To help address the above complexities, a typical vision system has two general steps. The first step is to filter the input to narrow the range of information to be processed. The second step is to extract and process the key features of the image(s).
The first step in the machine vision system is to filter the information available. In the parking space example, the camera’s viewing area most likely overlaps with other parking spaces. A car in an adjacent parking space or a car in a space across the street is fine. Yet if they appear in the image, the car detection algorithm could inadvertently pick up these cars, creating a false positive. The obvious approach would be to crop the image to cover only the relevant parking space, though this book will also cover other approaches to filtering.
In addition to the challenge of having too much information, images must also be filtered because they have too little information. Humans work with a rich set of information, potentially detecting a car using multiple sensors of input to collect data and compare it against some sort of predefined car pattern. Machine vision systems have limited input, typically from a 2D camera, and therefore must use inexact and potentially error-prone proxies. This amplifies the potential for error. To minimize errors, only the necessary information should be used. For example, a brown spot in the parking space could represent a car, but it could also represent a paper bag blowing through the parking lot. Filtering out small objects could resolve this, improving the performance of the system.
Filtering plays another important role. As camera quality improves and image sizes grow, machine vision systems become more computationally taxing. If a system needs to operate in real time or near real time, the computing requirements of examining a large image may require unacceptable processing time. However, filtering the information controls the amount of data involved, which decreases how much processing must be done.
Once the image is filtered by removing some of the noise and narrowing the field to just the region of interest, the next step is to extract the relevant features. It is up to the programmer to translate those features into more applicable information. In the car example, it is not possible to tell the system to look for a car. Instead, the algorithm looks for car-like features, such as a rectangular license plate, or rough parameters on size, shape, and color. Then the program assumes that something matching those features must be a car.
Some commonly used features covered in this book include:
Color information: looking for changes in color to detect objects.
Blob extraction: detecting adjacent, similarly colored pixels.
Edges and corners: examining changes in brightness to identify the borders of objects.
Pattern recognition and template matching: adding basic intelligence by matching features with the features of known objects.
In certain domains, a vision system can go a step further. For example, if it is known that the image contains a barcode or text, such as a license plate, the image could be passed to the appropriate barcode reader or Optical Character Recognition (OCR) algorithm. A robust solution might be to read the car’s license plate number and then compare that number against a database of authorized cars.
Get Practical Computer Vision with SimpleCV now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

