Chapter 4. Privacy Attacks
In this chapter, you’ll think like a security analyst and an attacker. Proactive privacy and security creates a cyclical approach, where you spend time envisioning potential threats and attacks and then experiment with how you can protect against them. Because security is never done, you continue this cycle as threats evolve and as your system changes.
When you complete the first round of interventions and mitigations, there is usually another round waiting for you. Since security is always evolving and so are new attacks, this chapter acts as a foundation for your understanding, but you’ll want to keep up-to-date by following research, trends, and threats.
Privacy Attacks: Analyzing Common Attack Vectors
Thinking like a security analyst requires knowing what is possible, what is probable, and how to best plan for potential attacks in a proactive, rather than reactive, way. In this section, you’ll analyze well-known attack vectors, where both researchers and curious data folks were able to reveal sensitive details meant to remain secret. By analyzing these attacks, you will build an understanding of the more common approaches to reveal sensitive data and be better able to protect data against them.
Netflix Prize Attack
You may think that your online behaviors are fairly general and nonidentifiable. Although some of your behaviors might be more common, such having a Gmail address, liking a popular post, or watching a popular video, there are likely some combinations that make you you.1 Your collection of interests, your location, your demographic details, and how you interact with the world and others make you stick out, especially over a longer period of time. Let’s investigate how this happens by looking at an attack on the Netflix Prize Dataset.
In 2007 Netflix ran a competition, called the Netflix Prize, for the best recommendation algorithm to predict user ratings. As part of the contest, Netflix shared a “random” sample of users’ viewing history and ratings that were “anonymized.”2 It contained 100,480,507 records of 480,189 users; the data was protected by removing “identifiers” but replacing them with pseudonymous IDs so that participants could use these individual identifiers to see content the user had rated.
Arvind Narayanan and Vitaly Shmatikov were two researchers with interest in data security at the University of Texas, Austin. They wondered if the individuals in this dataset could be de-anonymized (or re-identified) by looking at potential patterns and outliers. They began evaluating the users in the dataset and identifying those who were overrepresented as part of the sample.3
They were able to then compare the most active users in the dataset with a dataset they acquired by scraping IMDB, the popular movie website. By constraining the search space to a small date range from the date in the Netflix set, they were able to match similar reviews for the same content. This allowed them to successfully link individuals in the Netflix dataset with IMBD profiles.
Figure 4-1 shows the probability of linkage (or re-identification) based on this technique. The time span ranges for the bar legend show the number of days used to define the window of time between the review in the dataset and the online reviews. For each of the buckets on the x-axis, you can see the chance of finding the individual based on the number of reviews found online, such as when three out of four reviews in the dataset were found online.
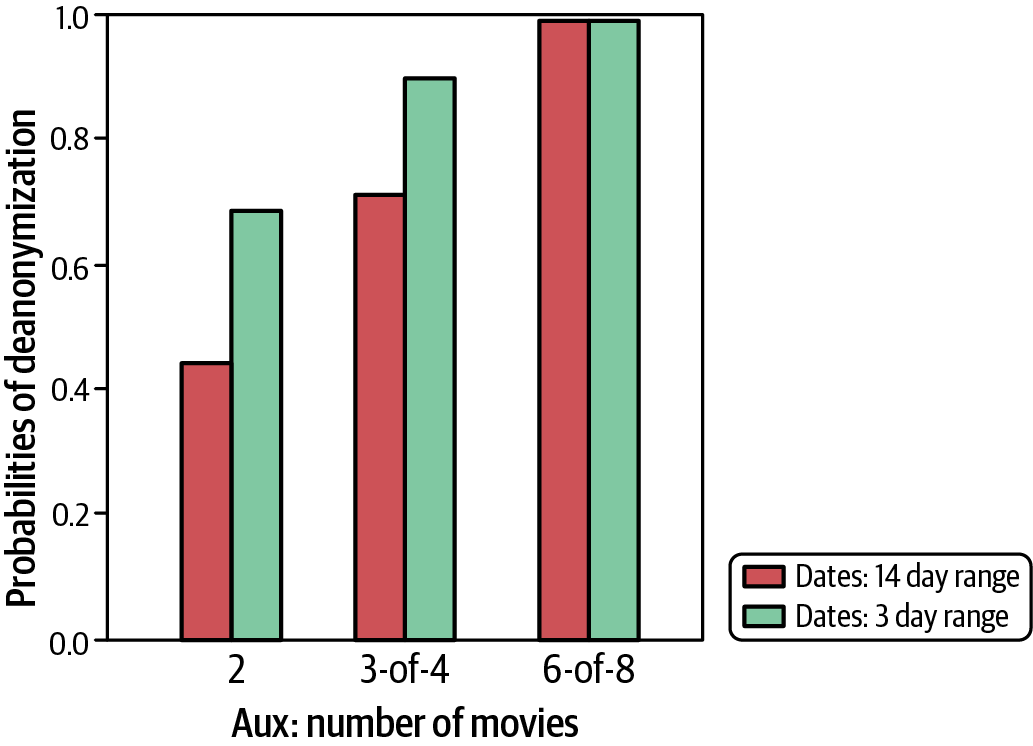
Figure 4-1. Netflix Prize reconstruction attack success
Although some users change usernames on each website or use pseudonyms that are difficult to link to real identities, some people use familiar patterns, including their actual names. If their IMDB profile or username revealed more information about them (such as a first name, a location, or a set of profiles that had more information), the ability for an attacker to then further identify the individual becomes trivial.
You might be thinking, “So what? They reviewed the movies publicly, why should I worry about their privacy?” There are a few reasons. First, most users and people do not have an accurate way to gauge their own privacy risk. This means they can greatly underestimate their risk of posting things in a public forum or other service. It could also be that they did not post some of the videos they privately watched on Netflix, which would now be public if Netflix released those reviews. As you recall from the Preface via Nissenbaum and boyd’s work—technology obfuscates the context and user choices—meaning users are often confused or unclear what level of risk they are taking on and how to control their own privacy. An absolutist view would be to never post anything publicly, but insisting people sacrifice the utility and enjoyment of technology as the only secure or private option is setting them up to fail.
Second, users cannot anticipate future data releases or breaches and their effects on prior decisions. Unless people live in a jurisdiction like the EU that gives them the right to be forgotten or to request removal of information, many things they did online will remain there indefinitely. Sometimes a user is not aware of the availability of their information—like when the website does not implement Privacy by Design so posts are public by default. Sometimes the data is collected illegally via a breach or when walled garden data is collected without consent for resale or reuse. Sometimes providing data is obligatory, such as to medical providers, to a government, or within a workplace. No one can know the conditions of every data acquisition or release if no consent information is released alongside the data.
Finally, your responsibility—as those who hold the data—is similar to the responsibility of those who build public infrastructure. Protections exist for everyone, not just the most cautious. The governance obligation when you take ownership of data from individuals is to make responsible decisions. Protecting all users, even those who actively participate in public spaces, is part of the job. This work supports the communal nature of the internet and other public spaces.
Thinking more generally about these types of attacks can help you determine how to avoid them when you release data. The Netflix dataset shows the power of linkage and singling out attacks, which are common vectors you should learn and avoid.
Linkage Attacks
Linkage attacks use more than one data source and link them together to re-identify individuals or to gain more information to identify individuals. In general, linkage attacks are successful when attackers have an auxiliary data source that connects easily with another dataset as was the case with the Netflix Prize and IMDB dataset. When you imagine the possible datasets available, you have to think of both privately held and publicly held ones. This can and should include databases you know might have been breached recently or in the past.
One approach to evaluating potential linkage attacks is to actively seek out potential data that others could use in connection with any data you plan to release publicly. Are there public websites that can be viewed or scraped that allow a person to easily gather information they could use in a linkage attack? Are there known public data sources that would easily link to the data you are providing? Or have there been recent large data breaches where data could be used to link individuals in a compromising way?
Warning
As you know from Chapter 2 and your exploration of differential privacy, imagining all possible auxiliary information is an exhausting task that is prone to error. Unfortunately, you cannot know what every attacker will know or have available to them. You can, however, control the data you release and to whom!
Another approach is to ensure all data that is publicly released undergoes state-of-the-art privacy protections, like differential privacy. You might determine this is required for all data shared with third parties, with partners, or even across parts of your organization. As you learned in Chapter 2, this also helps protect against auxiliary information that will get released in the future.
One possible way to determine if your data is easily linkable is to look at the uniqueness of your dataset and the data points themselves. You can determine whether your data is easily linkable by using cardinality analysis, like Google’s KHyperLogLog paper.
Expansive datasets are part of the problem. When vast amounts of data are collected and are not properly tagged as person-related or where governance and documentation were not properly implemented, a grave danger is introduced to privacy. How do you determine what data is re-identifiable?
Cardinality analysis can help you determine this. When you have a large dataset, it is the many unique combinations of those data points that can reveal or leak information about an individual, such as their device identifier, their location, their website, or their favorite music service. These small points in aggregate get hidden, making it difficult to see each one as unique.
Let’s say you have a bunch of different variables in your logging or datasets that are person-related but not necessarily identifiable. You’d like to explore if this data has hidden privacy risks by determining if the variables themselves or combinations of them are actually identifiable. These identifiers can be any piece of data collected from users, but the ones used by the researchers were things like browser agents, logged application settings, and other application or browser details.
What you’d like to find is the uniqueness of any one of these potential identifiers and combinations of them that are potentially or certainly unique. To do this, the researchers developed a two-part data structure that combines the power of two different hashing mechanisms. The first is a K Min Values hashing mechanism, which calculates the density of the dataset, and, therefore, its uniqueness, by looking at the distance between the K smallest hashes. At the same time, the variables and matched unique user IDs are passed to HyperLogLog or HyperLogLog++, which are highly efficient at cardinality estimations. By combining these two powerful mechanisms, the authors were able to create a fast and efficient method to quickly eject variables that were not very unique and variables that had a lot of users.4
Not only that, KHyperLogLog data structures can be joined to discover how combinations expose users to privacy risk. With this two-level structure, they can also be used to compare actual PII data with this “pseudonymous” data to determine if some variable combinations function as unique identifiers. In Google’s own use of the algorithm, they were able to find and rectify privacy bugs, such as storing the exact phone volume location with too high precision.
With these results, you can either recommend that the disparate sources with those unique combinations of variables are never combined or provide appropriate privacy and security precautions to reduce the risk of re-identification attacks or erroneous linkage. This is especially relevant for automated data processing or training large deep learning models, where the linkage could be identified without human oversight and exploited by algorithms or other automations.
This type of cardinality analysis also helps you determine how likely it is that a user can be singled out. Let’s explore what attacks are possible if a person is indeed easily identifiable in the group.
Singling Out Attacks
Singling out attacks work by singling out an individual in a public release and attempting to gather more information about them via the same dataset or via other sources. These attacks can also be performed in reverse, by bringing information about an individual to a released dataset and attempting to deduce whether this person is included and can be identified.
Let’s walk through an example of each.
Say you are a data scientist querying a naively anonymized database. You want to find out the salary of a particular individual, and you know that she is the only woman over 60 at the company. If the database allows you to get “aggregated” responses without additional security of differential privacy, I can perform a series of queries that targets this woman and exposes her salary to me. For example, if it is truly naive, I can ask for the salary of all women over 60, immediately returning her salary. If it is better protected but still doesn’t account for singling out attacks, I can perform a series of queries (one for all salaries of people over 60, one for all salaries of men over 60) and use their difference to reveal her salary.
Another real-world example is the re-identification of celebrities in the New York City taxi dataset. The dataset was released to the public as part of a Freedom of Information Act (FOIA) request in 2014. A data scientist with the dataset noticed an odd pattern, where the pseudonymous identifiers of several taxi medallions were repeated, sometimes showing the same taxi in multiple locations at the same time. This is impossible, of course, but it left an important clue. The scientist correctly inferred that this value actually represented a null value, where the medallion information was missing.
Via this discovery, the scientist was able to reverse engineer the hashing mechanism used (this was easy, as no salt5 was added!). The rest of the data was easily reversible by creating a rainbow table.
Once that dataset was revealed, it was soon linked to paparazzi photos of celebrities getting out of taxis because the medallion identifier must be visible on many parts of the taxi—the doors, the rear, the license plate, etc. There is a Gawker article that exposes how different celebrities tipped, since the data was now easily linkable. This is an example of bringing auxiliary information to a poorly anonymized data source, making it a linkage attack as well as a singling out attack. Although one might not care about the privacy of celebrities, this also means any other person getting out of a cab in a photo is identifiable. Privacy depends on proper protections, and allowing cracks in the privacy for some (here: celebrities) erodes privacy protection for all.
But singling out and linking data aren’t the only types of privacy attacks. Sensitive details exist everywhere, and even when you release aggregate data with some protections, you can inadvertently release sensitive details. Let’s investigate how aggregated data leaks information.
Strava Heat Map Attack
In 2018, the exercise tracking application Strava released a global activity map. It allowed users and onlookers to view activities (jogging, biking, hiking) from all over the world. It also boasted that data was anonymized. It took less than a day before interesting less populated areas of the map were highlighted on social media. While Strava had a large user base in North America and Western/Central Europe, it did not have many users in Africa and the Middle East. But there were still active routes there. Zooming in on those routes revealed outlines of previously undocumented US and NATO military bases, which were intended to remain secret.
Figure 4-2 shows a Strava screengrab of a US military base in Afghanistan. This base and similar ones were exposed in the days and weeks following the global heat map release, highlighted in a Twitter thread by a security-minded Twitter user (@Nrg8000) and several replies. On the day the map was released, many reports made clear that the outliers—data coming from Strava users in Africa and the Middle East—exposed military secrets of more than one nation-state.
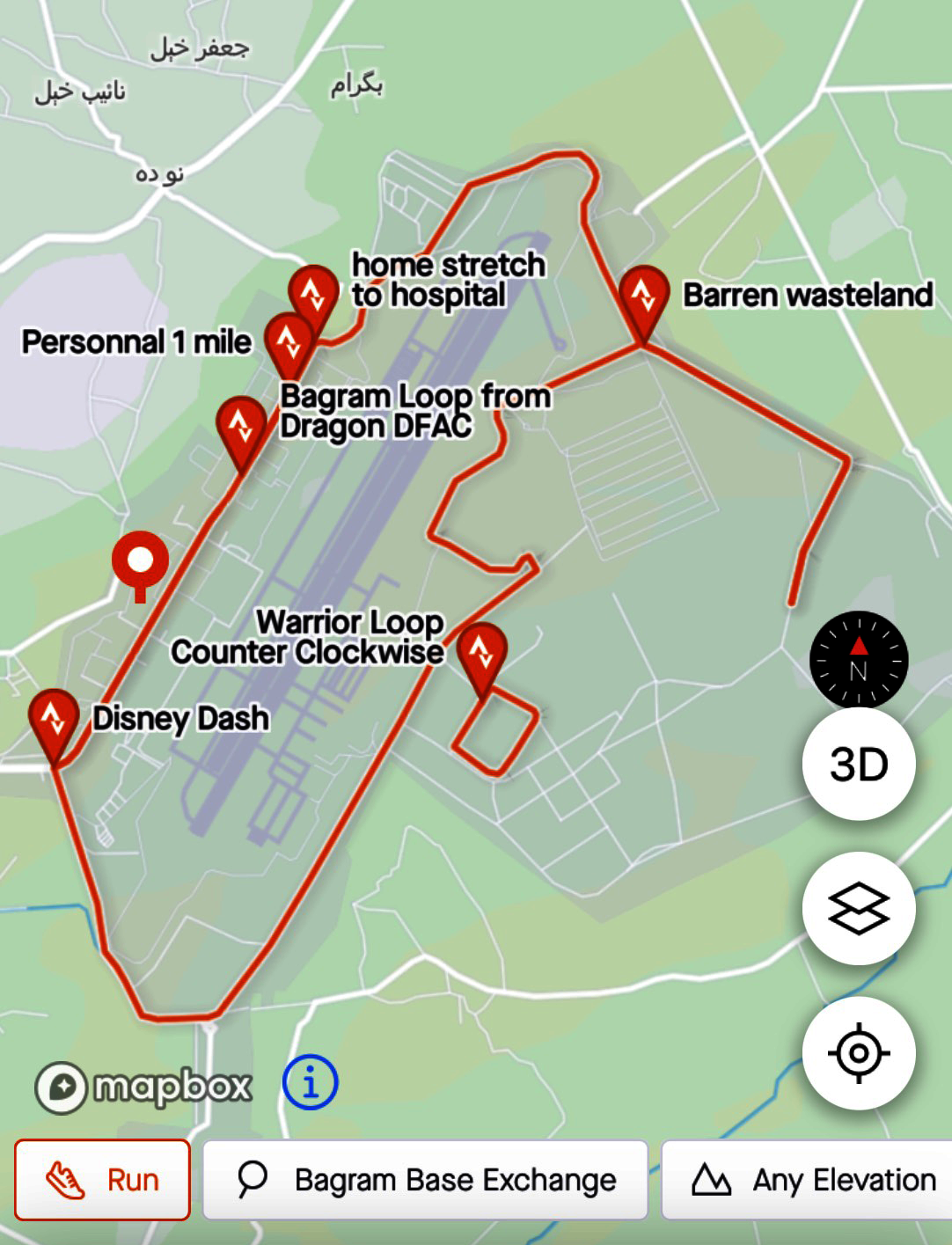
Figure 4-2. Bagram Military Base on the Strava application
This is a great example of how sensitive data can inadvertently link to other sensitive data. Here, personal data for US and NATO service members leaked confidential information about the military bases and operations. This demonstrates how individual privacy and group privacy relate. In this case, individual privacy exposure linked with group membership exposes extra information (here: confidential information).
Individual privacy, as discussed in Chapter 2, allows you to guarantee privacy for a particular individual. Differential privacy measures those guarantees and keeps them within a particular range that you can designate and validate.
Group privacy refers to the ability to guarantee privacy for a larger group. This could be similar to expanding the privacy unit under differential privacy conditions so that it covers a larger number of people (like a household unit for a census). But, as you might imagine, zooming out to say all members of a particular profession, gender, or race/ethnicity would be incredibly difficult if they represented a large portion of the population.
Even when you can guarantee privacy for individuals, you often end up “leaking” information about groups. In a way, this is great, because this is the power of data science and statistics! It is very helpful to use data to investigate, compare across groups, and develop conclusions while still maintaining strict privacy guarantees for individuals.
The Strava example shows how a concentration of users at a particular sensitive location revealed confidential information. But there are other examples where data collected in a voluntary and privacy-friendly way revealed group information. In a lawsuit against Google for underpaying women and gender-diverse individuals as compared to their male counterparts, data was collected internally using a Google form. The sheet asked for voluntary input of the person’s engineering grade, their gender, and their salary and additional bonuses paid in the prior year.6
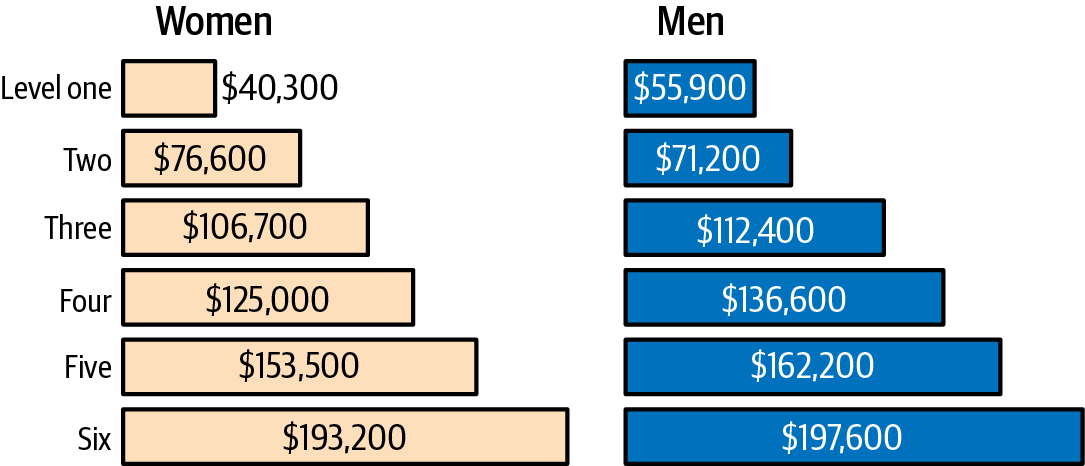
Figure 4-3. Aggregated consensual data collection at Google reveals salary disparity
This data in aggregate revealed a stark salary disparity between male employees and their women and gender minority counterparts at a variety of engineering grades. Figure 4-3 shows the details of this disparity and was used as evidence in court. At every level, except level 2, women and gender minorities were paid less than their men counterparts.7
As you can see, group privacy may at times be undesirable, because you want to make decisions based on private attributes. However, in the case of the secrecy breach for Strava users, it would have been useful to let users opt in rather than deploying a default opt-in. Strava later fixed this option via an opt-out option, but only after secret information was leaked. This is a good example of how Privacy by Design principles can help you choose safe defaults and consent options!
Another interesting attack on privacy and group identity is called the membership inference attack.
Membership Inference Attack
What if I told you that I could determine if your data was used to train a model. This might not matter if billions of people were used to train the model, but it certainly would matter if the training set was much smaller and if your membership in it revealed something particular about you, such as your sexual orientation, illnesses or other health-related information, your financial status, and so on.
In a membership inference attack, the attacker tries to learn if a person was a member of the training data. When models are trained on smaller datasets or if a person is an outlier, this person might be particularly vulnerable.
Reza Shokri discovered membership inference attacks in 2016. The process works as follows: the attacker trains a shadow model, which is a model that should be as close to the real model as possible. This mirrors the process of transfer learning, where the goal is to adapt information in one model to quickly train another—usually in a related field, such as when sharing base weights and layers between large computer vision models helps speed up training. Then, there is a Generative Adversarial Network (GAN)–like architecture that trains a discriminator, which is used to determine if a person (in vector form) was in the training dataset or not. This discriminator infers, from the output of the model itself, whether the data point was included in the training data.8 You can see the full architecture in Figure 4-4, which shows the many shadow models being trained, with their output feeding into the “Attack training set,” which operates as data to train the discriminator.
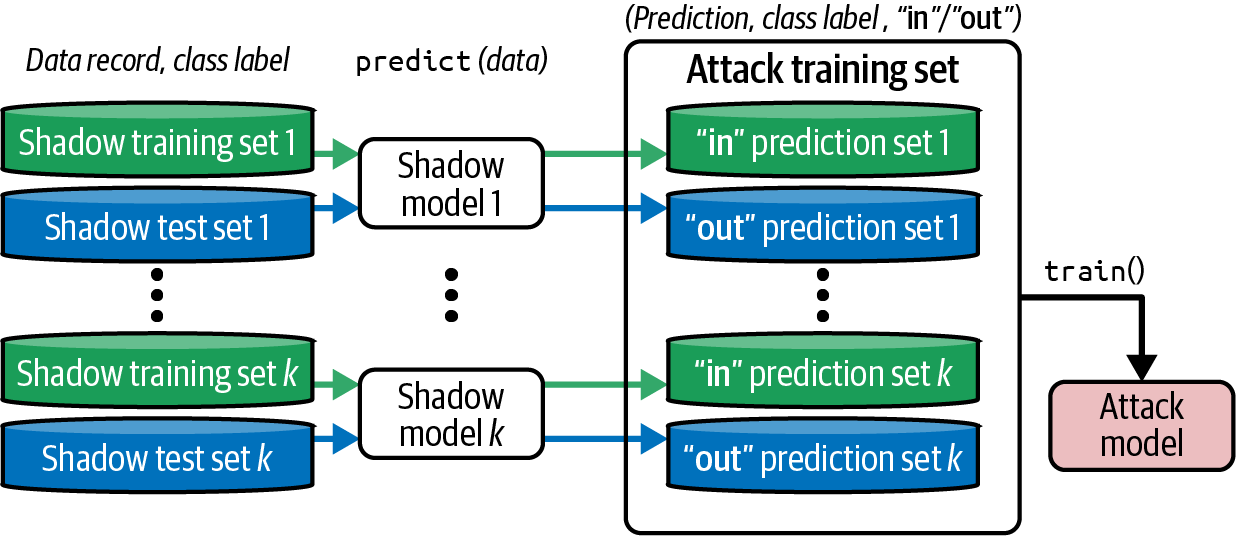
Figure 4-4. Membership inference attack architecture
You can probably guess what this process reveals! If a model overfits or if an outlier leaks particular information about itself into the model, it will have fairly different probability ranges for the training versus testing data. This is also why it’s particularly dangerous for outliers, models trained on a small dataset, or models with poor generalization.
Tip
A membership inference attack points out the importance of models generalizing well and the impact of outliers on the resulting model(s). Privacy techniques and technologies can help reduce the influence of outliers and promote generalization. Your goal as a data scientist is to ensure that your models are performant, which means to avoid this type of private information leakage. In Chapter 5, you’ll review ways to train models on personal data using differential privacy.
Let’s walk through the required steps to perform a membership inference attack:
-
Adequate training data must be collected from the model itself via sequential queries of possible inputs or gathered from available public or private datasets to which the attacker has access.
-
The attacker builds several shadow models, which should mimic the model (i.e., take similar inputs and produce similar outputs as the target model). These shadow models should be tuned for high precision and recall on samples of the training data that was collected. Note that the attack aims to have different training and testing splits for each shadow model, and there must be enough data to perform this step.
-
Once the shadow models are trained, the predictions for examples from the other datasets that were not part of their training as well as data from their own training dataset are recorded. This is now the training dataset for the discriminator.
-
The attacker trains a discriminator with this new training dataset. This discriminator is used to evaluate the target API and determine whether a datapoint is in the target model by evaluating the API model output with the discriminator. These attacks can, therefore, be run without full access to the model or in what is called a closed-box environment.
Shokri and his fellow researchers tested these attacks against Amazon and Google Cloud machine learning systems and a local model. In their experiments, they achieved 74% accuracy against Amazon’s machine learning as a service and 94% accuracy against Google’s machine learning as a service, making it clear that machine learning tasks expose private information. In a more recent paper, researchers were able to run this attack within private and decentralized systems such as federated learning (see Chapter 6), a type of machine learning architecture supported by Google and other large companies to promote private data use in a secure and privacy-friendly machine learning system. Since then, Shokri’s research group has released an open source library to measure membership inference attack privacy leakage.
Note
Recommender systems are becoming increasingly more personalized—employing demographic information, net worth, and other sensitive fields. For models trained on a small population, an attacker who knows a few pieces of information about someone can then determine if they were included in the training dataset so long as they can mock the probable input features. This applies to other information used for selection of the training data population, such as gender, age, race, location, immigration status, sexual orientation, political affiliation, and buying preferences.
In later research, Shokri and several other researchers found that model explanations leak private information, particularly for outliers. When using standard ways to explain why a model reached a particular prediction or output, these explanations leaked information about outliers in particular. This type of behavior is likely more prevalent the more that sensitive data is used to make decisions in the model.
This increased model granularity and sensitivity has other risks, including exposing these sensitive attributes for people who are curious what types of people were included in the training data.
Inferring Sensitive Attributes
Membership inference attacks can be generalized to describe group attributes of the training data population, called an attribute privacy attack. In this case, the attacker wants to learn things about the underlying population and uses the same technique to test theories about types of people who might be represented in the training dataset.
This attack reveals sensitive group details. If you are training a model with your user base and they are predominantly from certain regions, have certain personal characteristics, or are in a small targeted group with a particular shared attribute, such as their browsing or spending habits, this information could then be available to anyone with access to the model endpoint, so long as these attributes can be exposed via feature input or model behavior. At this point, it would not only be a privacy attack but also likely a proprietary information leak!
This isn’t the only way sensitive attributes are leaked, however. A research paper from 2013 demonstrated that Facebook likes were a strong determinant of private attributes, such as sexual orientation, gender, political leaning, or drug use. This research was performed at Cambridge University; one of the researchers went on to work with Cambridge Analytica, where these types of patterns were exploited to manipulate voting behavior.9
This underscores the guidance from differential privacy research. It is extremely difficult to determine what attributes an external source might be able to find, use, or link. It serves as an example of how revealing seemingly innocuous data points—such as Facebook likes or web search behavior—can be. Whenever you are collecting data from humans, you need to be aware of the possibility that this data will leak other sensitive attributes.
For these reasons, it’s important to treat all data collected about humans as potentially sensitive and to use the techniques in this book, along with your further research and experimentation, to protect this data and the related persons.
Warning
Learning sensitive or private attributes from seemingly nonsensitive data points is a significant contributor to model unfairness and discriminatory models. If the resulting model learns sensitive attributes leaked via training data correlations, these models reproduce societal biases and accelerate systemic oppression. This problem goes beyond the scope of privacy as well as this book; I recommend reading Algorithms of Oppression by Safiya Umoja Noble (NYU Press, 2018) and following the work of Timnit Gebru and team at DAIR and the Algorithmic Justice League to learn more.
Other Model Leakage Attacks: Memorization
Part of the problem with how models learn is they can end up memorizing or inadvertently storing information. This occurs easily if the examples are outliers. It also can occur if a particular sensitive example is shown many times. This phenomenon is correlated with parameter and model size (more parameters, more memorization). Findings from the Secret Sharer demonstrate this, but several other research circles confirmed this at the time of that publication.
What Carlini et al. showed, in the Secret Sharer, was that large models have a tendency to overfit and memorize parts of the dataset. In this case, it was a large language model that memorized secret tokens in the dataset (such as credit card numbers, Social Security numbers, etc.). I presume that Google was able to identify this behavior in other nonpublic and non-research-facing datasets, which led to the publication of this particular piece of research that was specifically trained on the Enron emails.
Therefore, the larger models grow—which at this point seems to have no upper limit—the greater the chance of some semblance of memorization and overfitting, particularly for outliers, both via their characteristics and/or their frequency.
You can also see this behavior in synthetic GANs, as explained in This Person (Probably) Exists. This research pointed out that GANs based on person-related data, such as the faces on This Person Does Not Exist, are often actually traceable to the source dataset. This was reported in several other cases where professional models were paid to sit and have photos taken. Later those photos were used to create fake influencers. In the faces and bodies of those synthetic influencers, the original human models could find parts of their faces and bodies. This obviously means those people do exist, and so do the parts of them that ended up in an influencer without their explicit consent. I like to call these types of GANs data washing, because—via the machine learning training—personhood, authorship, and attribution are removed. The result is, supposedly, a completely new creation, but you now know this is not really true.
Tip
These types of models are growing every week, and it’s hard to keep up with all of them. If you have used any of the large GPT-based models such as ChatGPT, I challenge you to find a person who you think might be part of the scraped training data but not someone too popular where they would appear in many sources. Ask the model who this person is and compare it with text from the person’s website, Wikipedia, or social media sites. You might be surprised to see these outliers’ own words parroted back from the “AI.”
By now, you might be realizing how valuable and sensitive trained models can be. Let’s review ways that attackers have stolen models from production systems.
Model-Stealing Attacks
Models are increasingly valuable assets, and the more you integrate them into production systems, the more they are shipped to the edge of the infrastructure. There, they are either on the public-facing internet or deployed directly on user devices—laptops, smartphones, and appliances. The result is an increasing threat of model-stealing attacks, where an attacker is able to get either the model itself or a close enough approximation that they could use it for their own machine learning or to extract other details.
Why is this a problem? Well, if the model contains sensitive or proprietary information or is seen as a company asset, then this type of attack is as bad as someone stealing money or data from your organization! If the model is already open source or a fine-tuned model built on a large open source model, the risk or threat is much lower.
How do these attacks work? One of the first papers articulating this type of attack was released by Florian Tramèr et al. in 2016. The group was able to train several models using the Amazon and Google Cloud APIs that were available at that time. They generated and gathered a dataset that reflected the data that this model used. They set up a series of API requests and were able to optimize their requests to span the search space of the input data. By saving those data points, they now had a training set and could build a variety of models. Then, a cyclical approach to fine-tune the model was used to ensure the model closely matched the production system.
Note
I taught an O’Reilly live course on several of these attacks in the past, with example notebooks (and a few more) if you’d like to walk through some attacks. There are also many implementations available on GitHub, likely with updates for a particular architecture or language if you have a specific use case you’d like to test.
When you ship models to a device, users have an even easier way to inspect the behavior of the model and to run queries in a low-latency environment. Several researchers and enthusiasts have explored models shipped to Android and iOS devices and how to reverse engineer the model weights and architecture. Protecting models that are shipped to end devices is still very much an open problem. One piece of advice is to use differential privacy as part of your training steps (see Chapter 5), obfuscate the model architecture using transfer learning and distillation, or keep multiple models as part of a process, shipping only those that are required to run offline to a phone. You might also find that using federated learning—where the model is owned by all devices—fits the scenario best (see Chapter 6). As this is an active area of research, I recommend searching for recent research and discussing these concerns openly with the security and privacy experts at your organization in order to find a fitting mitigation.
Similarly, model inversion attacks exploit models to target an individual user. In 2015, researchers were able to extract noisy images from facial recognition models that revealed semi-accurate photos. The only data needed to perform this attack was the target class they were trying to reveal and access to the model prediction API. They used a search method that aimed to maximize activation, allowing them to get closer to the optimal input: in this case, a person’s face (see Figure 4-5 to view the extracted image versus the real image; this was generated using an open source repository modeled after the initial research).

Figure 4-5. Extracted noisy face from a model inversion attack (left) and a training set image of the victim (right); the attacker is given only the person’s name and access to a facial recognition system that returns a class confidence score
If a model is particularly sensitive, you should treat it as a high-value asset, wrapping it in several layers of protection. That said, you’ll need to balance the usability of the system with the model value. Privacy technologies are handy for this. In Chapter 6, you will learn more about shipping parts of models closer to devices while keeping them updated and safe.
So if privacy technologies can help create models that leak less information, is there any way to attack these privacy technologies? Let’s explore ways researchers have proven that privacy technology itself can be attacked.
Attacks Against Privacy Protocols
When I discussed differential privacy in Chapter 2, I referenced attacks against differential privacy mechanisms. Let’s dive a bit deeper into the types of attacks that have been performed and what libraries do to prevent those attacks.
In 2012, Ilya Mironov was able to perform an initial attack on a differentially private mechanism that used a Laplace distribution due to how floating-point systems function. When you sample from a Laplace distribution, you attempt to model a continuous space, but this isn’t how computers actually work. What researchers have been able to show is that there is a tendency for floating-point machines to sample randomness in predictable ways. This makes sense, if you think about the need for someone to write code that creates entropy—generally, computers are not very good sources of true entropy.
In this attack, the attacker will observe several query responses for this differential privacy mechanism and try to determine whether or not it came from a random distribution sample. If the attacker knows the type of distribution (e.g., Laplace or Gaussian) and the mechanism uses no special source of randomness—but instead calls built-in functions for random sampling methods—this attack can succeed.
To prevent this attack, some post-processing needs to be performed on the addition of random noise to the distribution. This post-processing should be built directly into the library, be peer reviewed and audited, and use methods that will work across all machines.10
Note
Successful attacks on k-anonymity and weaker mechanisms for anonymization are commonplace enough that they often don’t get much attention. That said, a simple search in ArXiv for “re-identification” can turn up the latest research. I also recommend reading Aloni Cohen’s successful attack on k-anonymous EdX data.
Timing attacks have also been proven to work against differential privacy mechanisms. The attacker observes the amount of time the response takes and then builds a statistical model to discern what part of the noise distribution was selected. Timing attacks are common against computationally complex operations—like cryptography—and notoriously difficult to prevent when rapid responses are the goal.
To be clear, these attack vectors are not all the possible privacy attacks on data or machine learning systems, but they should help you be alert and thoughtful. I hope this overview gave you an idea of what to look out for and how to reason about the more common types of attacks.
Warning
You haven’t even begun to scratch the surface of other types of attacks on machine learning models, such as adversarial attacks that attempt to “trick” the model into a particular result or poisoning or Byzantine attacks, which make models drift in a particular fashion. For a good overview of that space, I recommend starting with Battista Biggio’s Wild Patterns paper and then checking out the latest on ArXiv! There are also some interesting conferences, such as the ACM’s AI and Security conference and the NeurIPS’s Safety Workshop.
In the next section, you’ll learn data security basics as an overview in case you are new to security. You’ll see how working with data security professionals helps manage attacks and related risk and supports privacy and security concerns in your data science work.
Data Security
Data security overlaps with data privacy and data governance in fairly significant ways. Security is a required step in data governance—restricting access, preventing insecure or questionable usage of data, setting up security controls for safer data, and assisting when something goes wrong (i.e., data is breached or stolen). Obviously, if data is breached, so is privacy. These fields complement one another, but they are definitely not the same.
Although these systems and processes are not often the responsibility of the data science team, you should be familiar with these measures and the conversations around them. They will come up when you are managing and maintaining sensitive data. This knowledge will also help you consider potential attacks and protect the data you are using.
Data security is almost always concerned with the CIA triad, which stands for:
- Confidentiality
-
Data that is sensitive or confidential is made accessible only to those who should access the data. The data is not available—in any way—to others inside or outside of the organization.
- Integrity
-
The data can be trusted. It is valid and has not been tampered with by internal negligence or external tampering.
- Availability
-
The data and related services are properly available for their intended purpose. This usually has to do with agreements like service level agreements (SLAs) or service level objectives (SLOs) that outline availability metrics.
Clearly, these are also the goals of most data teams, but there is a focus on potential malicious activity or actors—external or internal (referred to as internal threats).
Figure 4-6 imagines some of the intersections between these topics in data security via a data science lens. It is not exhaustive but should provide guidance and inspire ideas on how these fields overlap.
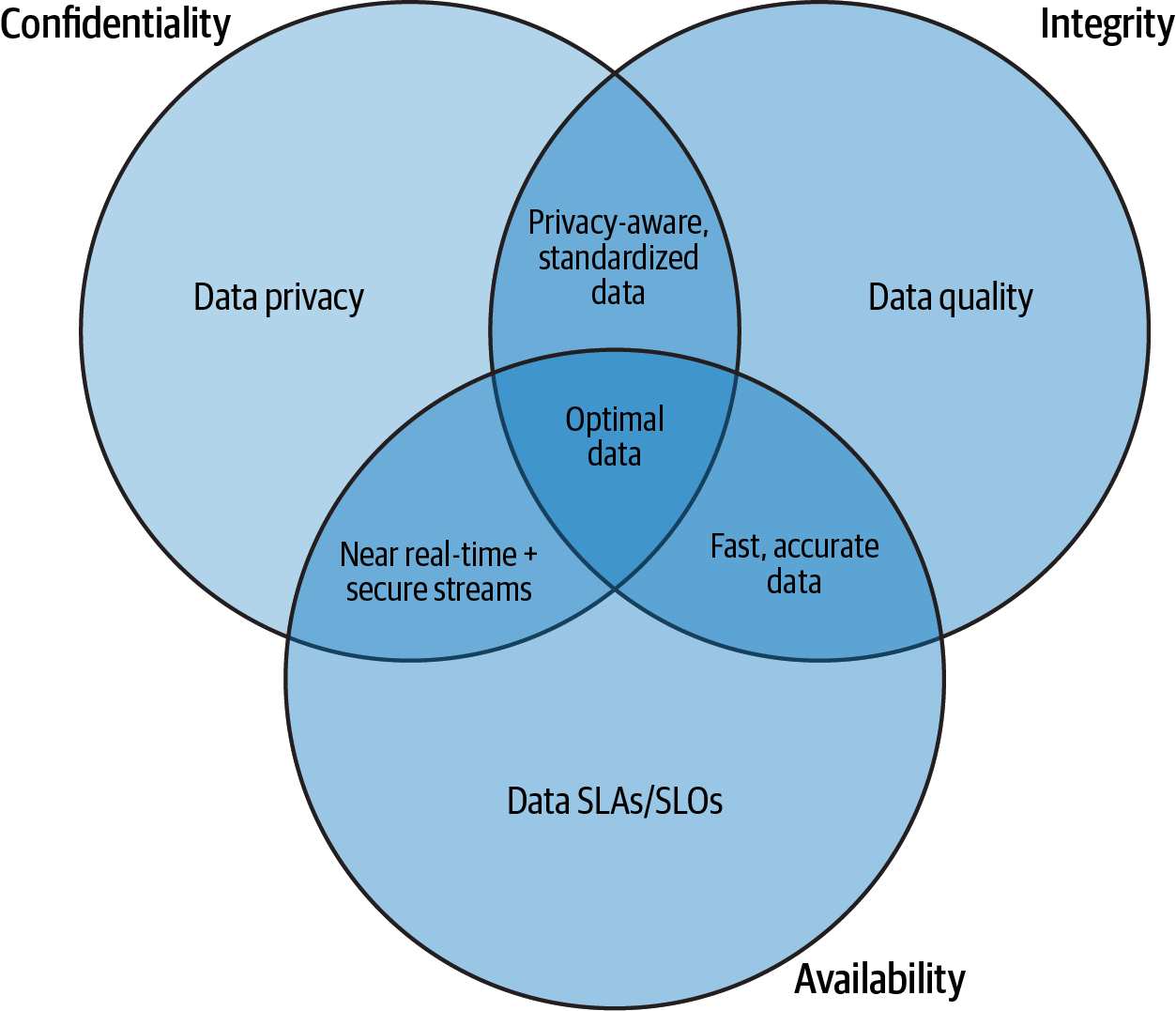
Figure 4-6. Data security principles in data science
Data security professionals have several major concerns when it comes to managing data, implementing data governance, and supporting privacy initiatives. In the following sections, you’ll learn key building blocks and technologies you will encounter when working on these systems with security professionals and get a few tips for collaboration.
Access Control
Access control systems, often connected with authentication and identity providers such as Microsoft Active Directory, Google Single-Sign-On (SSO), and AWS Identity and Access Management (IAM), allow administrators to manage who has access to what data and in what form. These systems allow you to form groups of individuals and/or services that have the proper authentication credentials to access, read, change, or add to data. There are several reasons why access control in this manner is useful. For example, you might want to shut down write access to the data in case the service is ever compromised by a malicious actor who might use the service to manipulate the data (perhaps by encrypting it in a ransomware attack). And, of course, it is possible that even a read of that particular data by a malicious actor can create a significant security risk.
For example, you might have an API service for a machine learning model that pulls data for training and testing. This service requires read-only access, as it will not—and should not—modify the data.
Or, suppose you have a person-related database that you’d like to secure more heavily than other databases. You could set access controls for a smaller group of individuals as well as use built-in security features to ensure that every access is logged and that each query returns masked content for some of the fields. Pseudonymization techniques (see Chapter 1), such as masking, or ideally the use of differential privacy (see Chapter 2) would provide extra protection for access and also allow for a stronger audit trail in case there is a suspected breach.
Data Loss Prevention
Data loss prevention technologies measure ingress and egress interfaces for systems or networks to determine if sensitive data is leaving a trusted region. They are often used by data security professionals to provide an extra layer of protection for sensitive data and to guard against data exfiltration attacks—when someone is exporting or moving data in an unapproved manner. A malicious actor might break into the network to take files and data, or this can happen via an internal threat, such as an employee exporting data to another party or device for unapproved usage. It could also be nonmalicious and insider, for instance, where “shadow IT” operations have made the transfer of sensitive data internally commonplace (although still not approved!).
Data loss prevention technology can often detect these data flows by looking at network activity and network packet headers or metadata. Many of the top solutions available use statistical modeling and/or machine learning as part of the offering. Your skills in data science will help you understand that anomalous network behavior (like gigabytes of data flowing to a new IP address) or data flowing at odd hours is a good indication something might be amiss. Depending on how the network is architected and managed, there may also be deep packet inspection, allowing the network administrators and the data loss prevention technology a closer look at what exactly is being sent over the network.
If your organization uses data loss prevention technology, it’s important for the data team to understand where and how it is being used so new data services you build don’t get flagged as potentially malicious. It might also be interesting to learn more about the technology in use, in case you would like to support those efforts. For more detail regarding data prevention technology, I recommend reading through the documentation provided by Google Cloud’s service.
Extra Security Controls
Additional security measures, beyond basic access control mechanisms, are commonplace at most organizations today, ranging from encrypting all data at rest and ensuring encryption keys are rotated to changing server access points via networking restrictions or cloud identity services like Amazon’s Identity and Access Management (IAM). The purpose of extra security controls is to reduce the risk of an internal or external attack by adding protections and defenses.
Development teams—including data scientists—often complain about these protections that make data harder to access should an intruder infiltrate the servers, network, or systems. It can mean a few extra steps for well-intentioned actors, like a data analyst trying to get their job done.
That said, these protections help ensure data accessibility is appropriate. The more valuable the data, the more controls and protections it should have. Lead by example and help champion these measures, which also provide better data privacy. Most technologists have learned and used these basic data security measures, such as using authentication systems, managing keys, and checking proper access, and data folks need to learn them as well. If you end up specializing in data privacy and security, you might even suggest and implement these systems one day.
Threat Modeling and Incident Response
Security professionals often use threat modeling and incident response to assess security risks. These are commonly performed by the information security (infosec) teams, in conjunction with relevant compliance, audit, or legal experts.
Threat modeling involves mapping current processes, data flows, and procedures and then considering what malicious actors might do to attack the infrastructure or how they might trick employees to provide access or use the services for unintended purposes. When performed effectively, threat modeling is a continuous and agile exercise that keeps the data, applications, and humans as secure as possible.
Tip
In my experience, I’ve worked alongside amazing infosec professionals, who were open to learning about the data and machine learning topics I know and sharing their knowledge on topics like threat modeling. Your security team will know a lot more about the types of attacks that affect the systems in your organization and may be willing to teach you more. This knowledge will help you better assess risk and threats internally and externally. For a quick overview of agile threat modeling, I recommend reading Jim Gumbley’s Agile Threat Modeling post.
Incident response refers to the actions you need to take and the plan to use should you discover a security incident, such as a network intrusion, data breach, or other information leakage. An incident can be as small as someone posting a username or email on an internal log. But it can be huge—posting full credentials to a public repository or leaving a database open to the public with a poor password or none at all! Unfortunately, these incidents happen regularly, in part because many developers and data scientists are not taught about security hygiene—a term used by security communities to describe risk awareness and best practices.
Incidents will happen. When they happen, your team already should have worked through several incident response plans and know how to proceed. Security professionals create these plans, often with input from other teams that develop and maintain the affected platforms and/or services. Privacy professionals also often have a data breach response plan, which is particularly helpful for your work and often integrated into the incident response plans.
If you discover an incident, the first step is to take a deep breath, refrain from touching or doing anything, and contact security. They may need to collect forensic evidence and determine what services and storage were accessed or impacted along with attempting to identify the entry point, privilege escalations, as well as other evidence left behind. Think of it like a crime scene, where every fingerprint and smudge matters! Only once you have the all clear to turn off services or remediate the problem should you proceed with ways to help mitigate the incident. You may need to update a password, rotate a key, or change the networking rules if something was exposed. No one wants to be part of an incident, but having a plan in advance can make these events less chaotic and error prone. I recommend working on incident response plans with your security team as they relate to your privacy concerns about the data you use.
Probabilistic Reasoning About Attacks
What is reasonable to expect when preparing to defend your query mechanisms, APIs, and models against attack? How can you determine when you have built in enough privacy and security?
Security practitioners ask these questions daily. Generally, the advice is to ensure that enough mitigations are in place for the likelihood and potential impact of any threats. Let’s analyze how to think about these problems using probability.
An Average Attacker
Is there such a thing as an average attacker? Well, I ask you this: do you have an “average user” in your population? Probably not!
You might be able to cluster your users and find an average per “type” of user (for example, superusers, or beta testers/early adopters), but humans aren’t often average. Therefore, the idea of an average attack is flawed.
But can you use data to reason about expectations for a “typical” attacker and use probability to assist in how your organization thinks about attacks? Absolutely!
When you participate in a threat modeling exercise, you identify and then sort potential attack vectors by value (i.e., financial or reputational risk/reward) as well as likelihood. This is where your understanding of probability can help. Depending on the data at your organization, you might actually have hard information to support your reasoning around likelihood.
Humans are not very good at reasoning about likelihood without actual data. Research shows, in fact, that even security experts asked to rate risk and likelihood in a given scenario will rate it differently when they see the same scenario another time. Figure 4-7 shows data from a study in which Douglas Hubbard and his research team asked experts to rate the same scenarios over a period of time. His group was trying to determine if experts would rate these similarly every time—as expert assessments are often used as the sole data point to assess risk. If this was the case, you would see a perfect line where the x-axis equals the y-axis. Instead, you can see that there is often no consistent rating over time—even for the same rater and the very same scenario.11 This means that much of the way organizations currently classify risk is inherently malleable.
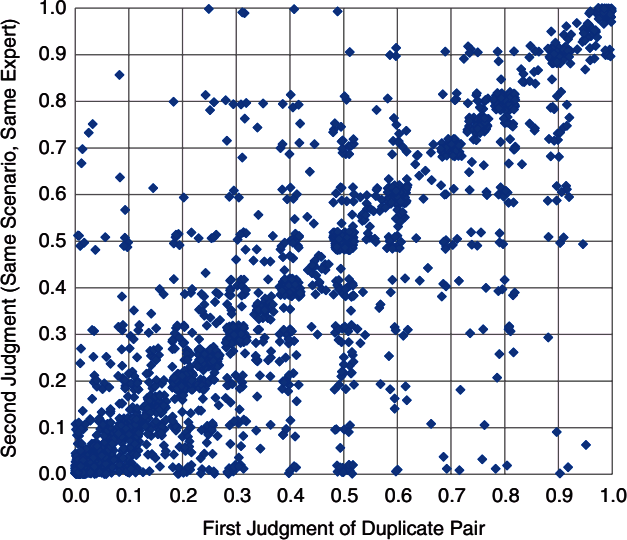
Figure 4-7. Hubbard’s expert risk assessment and its divergence
This is similar to the issue of “averaging” risk. When you reason about average risk in quantifiable privacy, you end up actually overexposing vulnerable populations in an unequal way. As described well in an article by DifferentialPrivacy.org, when you make average-case assumptions about the privacy risk, you risk overexposing outliers due to their already more precarious place in the data distribution.
So why, exactly, should you use probability to reason about privacy and security risk? Let’s take a look at current ways of measuring risk (not averaging it!) and determine if there are some places where data science can be useful.
Measuring Risk, Assessing Threats
You might be familiar with the tried and true risk matrix, which attempts to map and then block risk into different regions to determine what should be addressed. This system would be great if inputs were actually consistent, quantifiable, and realistic measurements, but inputs are often riddled with personal biases and high uncertainty.
As a data scientist, you are tasked with reducing uncertainty via observation, experimentation, and scientific inquiry. Sometimes it works and you build a probabilistic model of reality; other times it doesn’t and you can measure only how much uncertainty to expect (or keep experimenting!).
Your data science toolkit can assist in assessing threats and measuring risks, but only when there is historical data. If there is not a quorum of experts to help model, if uncertainty is high and information low, you are unlikely to provide significant assistance.
However, there is a growing push in the security communities to create more quantifiable risk scenarios; here you can help model the question to make it answerable. One way might be to think through dependent and independent variables of a complex problem or threat, identifying those that change often versus those that are fairly static. There might also be open data or internal data to support an assessment of the distribution of these variables over time.
Tip
Modeling experiments have proven quite fruitful in security research. One great example of this is the initial research that uncovered Rowhammer, a way to exploit dynamic memory and read from your neighbors in large data centers. This research showed that this threat vector—previously believed to be quite uncommon—was occurring at much higher rates. Building data-driven security experiments to validate threats can help ensure that these models are based in reality.
For data science purposes, the main risks that need to be managed are access to the data, data infrastructure, and models. Let’s review a few mitigations that can help ensure that you have appropriate protections in place.
Data Security Mitigations
With your improved understanding of data security, you can now select the areas of data security that you want to incorporate into your work. In this section, particularly relevant protections for data science and machine learning work are highlighted, but, of course, the field is large. This can be your starting point, but it is not a comprehensive list.
Applying Web Security Basics
Since data work often involves offering data via endpoints and APIs, explore how those are accessed to borrow ideas from already well-defined approaches and apply them as you see fit.
For many decades, the Open Web Application Security Project (OWASP) has outlined what the top threats are for web applications and websites. OWASP also outlines protective controls, including protecting API endpoints by using access control and validating inputs. These controls are also useful for anyone creating a model API that will be available to users directly or indirectly.
Ensuring all model or data query endpoints are thoroughly tested is another useful measure. Work with the software engineers to outline potential attacks on models—adversarial attacks, poisoning attacks, and the privacy attacks outlined in this chapter.
If you are exposing a model directly for use, implement rate limiting and determine who your users are by requiring a clear sign-up process with human verification. If rate limiting is not an option, ensure you are validating input and that you have a response—for invalid queries or requests—that does not leak extra information.
Finally, if at all possible, do not connect your models or query interfaces directly to the public internet. Require an access control process that involves identity verification or wrap your model in several input processes, making the public internet data one of many data sources or one that never directly touches your model input.
Protecting Training Data and Models
As you have learned in this chapter, protecting your machine learning is about more than just protecting the model itself; it’s also about protecting the infrastructure that helps build and train your models.
Think about the technological supply chain verification (i.e., technological bill of materials)—you must ensure the data entering your model is properly protected. Therefore, you must automate your machine learning systems and your data workflows whenever possible. Ensure they are properly designed and tested for privacy and security concerns.
Goals for data usage are different from organization to organization. Here are some questions to explore and address as you design:
-
Does this data flow have person-related data? What have you implemented to mitigate privacy concerns?
-
Do you understand your organization’s interpretation of regulation enough to provide guidance regarding proper mitigations? If not, whom can you ask to assist in translating the legal concerns into technical concepts?
-
Does this data flow cross trust boundaries? If so, how are you addressing security concerns?
-
Have you implemented testing as part of this workflow to ensure that the mitigations are actually working?
-
Have you spoken with data consumers on data quality and analysis requirements so they can keep using this data?
-
Have you documented assumptions and governance requirements so others can easily understand this workflow?
-
Can you run integration tests to regularly sample data and ensure the system is working as expected?
-
Have you automated all that you can, but left human-readable documentation so others can validate or update the privacy and security controls should something shift?
-
Do you know what happens when something breaks?
In addition to addressing issues like these, you can also implement proper version control on your workflows and determine if version control for their resulting datasets or models is appropriate (see Chapter 1). As you learned in Chapter 1, ensuring that your workflows support self-documenting lineage and governance will already go a long way toward implementing data governance. This also helps accelerate and expand security and privacy work, as systems are well understood.
Now you’ve done what you can, given what you know about the threat landscape and regulatory environment. But, you know that keeps changing! This requires you to stay informed on new attacks and threats on the horizon. How can you learn about new attacks?
Staying Informed: Learning About New Attacks
You already know that new developments in machine learning and data science happen quickly. It’s unlikely that you have time to read every paper on the topic or to keep up with every conference talk, especially as interest in this topic continues to grow. How can you stay current enough to ensure you have things covered?
From a security aspect, I would recommend taking a look at some of the leading conferences, which are now beginning to have dedicated tracks for data privacy and security. For example, the long-running DEFCON conference now has a dedicated track for AI attacks called the AI Village.
There is also a great community around privacy technologies called OpenMined. Their Slack community—as well as their courses and conferences—focus exclusively on privacy in data science and machine learning.
Some additional newsletters and blogs might be of interest, including mine! Here is a short list:
- Probably Private
-
My newsletter on data privacy and its intersection with data science, with updates for this book and related topics
- Upturn
-
Newsletter on justice and privacy in technology
- Bruce Schneier on security
-
Security expertise blog covering a wide variety of security topics
- Lukasz Olejnik on cyber, privacy, and tech policy critique
-
Security, privacy, web technology, and tech policy
- IAPP’s Daily Dashboard
-
Daily updates from the International Association of Privacy Professionals (IAPP)
Tip
What I would recommend—more than anything—is finding your passion and niche within the community and following researchers and organizations that are doing interesting work in that area. This way, staying up-to-date feels more like following the work of good friends.
If you miss things and it’s important, it will likely come up in the context of your work. If you’ve built your connection with infosec coworkers, they will usually also keep you in the loop should anything of particular interest arise.
Summary
In this chapter, you learned about a wide variety of attacks on privacy—attacks to reveal extra information in the data, attacks against machine learning models, and attacks against privacy protections themselves. You also learned about collaboration with security peers and how working with them on privacy risk and mitigation is essential.
Security is a constantly evolving field—by the time this book is published, new attacks will have been created and used. Use this chapter as a start for your understanding of privacy and security risk that you will grow alongside your work on protecting privacy.
In the next chapter, you’ll dive deeper into your normal workflow to start exploring how to protect privacy in machine learning and data science.
1 Of course, your actual account details are definitely unique! What I am referring to here is that the act of using Gmail is not unique.
2 Reminder: if you release data publicly, you’ll want to first spend significant time determining how to protect it and how to describe the process used to protect it. Saying something is anonymized means that security and privacy researchers will feel invited to prove otherwise.
3 Indeed, this calls into question how random the sample was to begin with, and if Netflix preprocessed the data to segment a group of more active users. As you know from Chapter 2, outliers would be present and at greater risk for exposure.
4 If you have the inclination and time, read “KHyperLogLog: Estimating Reidentifiability and Joinability of Large Data at Scale” or take a look at a more visual walkthrough of KHyperLogLog to learn more about how these work in detail.
5 Salt is random data that is used by one-way hashes to protect against rainbow table—or precomputed attacks. To ensure one-way hashes are secure, you need cryptographically secure pseudorandom generation, which salt achieves when used with well-maintained cryptographic libraries.
6 This type of data collection does not provide strict guarantees like with differential privacy. It was voluntary disclosure, and the organizers did toggle what options were available to them and built the questionnaire to allow for more privacy. Creating anonymous and differentially private survey infrastructure would be a wonderful contribution for these types of use cases—keeping privacy guarantees high and providing ways that sensitive data can be used for equality and justice.
7 This data was collected prior to 2017 and released in 2017. Several other studies and actions in large US technology companies have revealed similar pay gaps or other mechanisms that oppress women and gender minorities—including an overrepresentation in junior roles. Several recent studies show this trend is changing, with now women and gender minorities earning more than male counterparts when they reach high levels, but with the same overrepresentation in junior roles. Analyzing data like this in a consensual and privacy-aware manner can help expose unfair and unequal treatment and track if diversity and equity initiatives are working.
8 If GANs are new to you, the high-level idea is that they have two machine learning models. One tries to make a decision based on the output of another, which then helps correct the error of the first. GANs are often used to produce different types of content and media, ranging from machine learning art to generated text photos or videos, including content like deep fakes.
9 Cambridge Analytica ran political advertisements on platforms like Facebook, which aimed to influence voters in the UK Brexit referendum and 2016 US Presidential election. It is difficult to determine how successful these targeted advertisements were, but the profiling used private attributes—such as voting behavior and political affiliation—inferred from Facebook likes and profile information.
10 If you’d like to learn more about these approaches, I recommend taking a look at Tumult Analytics’ approach or the Google paper on secure noise generation.
11 Douglas Hubbard and Richard Seiersen’s book, How to Measure Anything in Cybersecurity Risk (Wiley, 2016), is a great read for understanding the security community’s approach to data. Although the recommended methods are dated compared with today’s data analysis and probability, the foundational approaches can help you understand the lack of data and large problem space in which cybersecurity professionals operate.
Get Practical Data Privacy now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

