Chapter 4. Co-occurrence and Recommendation
Once you’ve captured user histories as part of the input data, you’re ready to build the recommendation model using co-occurrence. So the next question is: how does co-occurrence work in recommendations? Let’s take a look at the theory behind the machine-learning model that uses co-occurrence (but without the scary math).
Think about three people: Alice, Charles, and Bob. We’ve got some user-history data about what they want (inferentially, anyway) based on what they bought (see Figure 4-1).

In this toy microexample, we would predict that Bob would like a puppy. Alice likes apples and puppies, and because we know Bob likes apples, we will predict that he wants a puppy, too. Hence our starting this paper by suggesting that observations as simple as “I want a pony” are key to making a recommendation model work. Of course, real recommendations depend on user-behavior histories for huge numbers of users, not this tiny sample—but our toy example should give you an idea of how a recommender model works.
So, back to Bob. As it turns out, Bob did want a puppy, but he also wants a pony. So do Alice, Charles, and a new user in the crowd, Amelia. They all want a pony (we do, too). Where does that leave us?
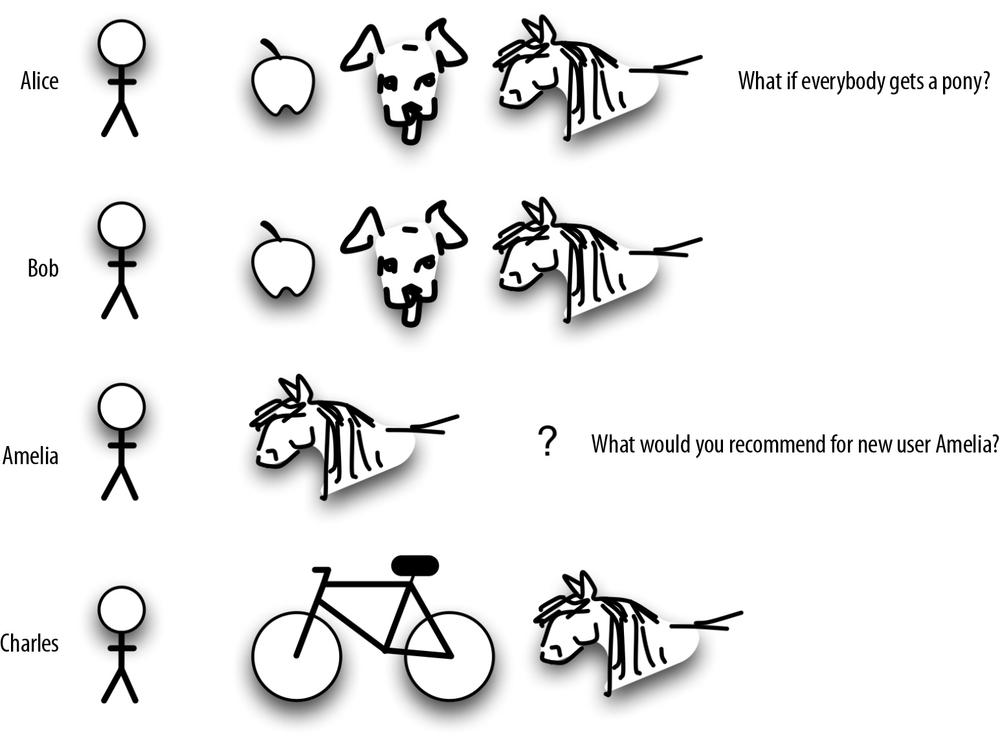
The problem is, if everybody gets a pony, it’s not a very good indicator of what else to predict (see Figure 4-2). It’s too common of a behavior, like knowing that almost everybody buys toilet tissue or clicks on the home page on a website.
What we are looking for in user histories is not only co-occurrence of items that is interesting or anomalous co-occurrence. And with millions or even hundreds of millions of users and items, it’s too much for a human to understand in detail. That’s why we need machine learning to make that decision for us so that we can provide good recommendations.
How Apache Mahout Builds a Model
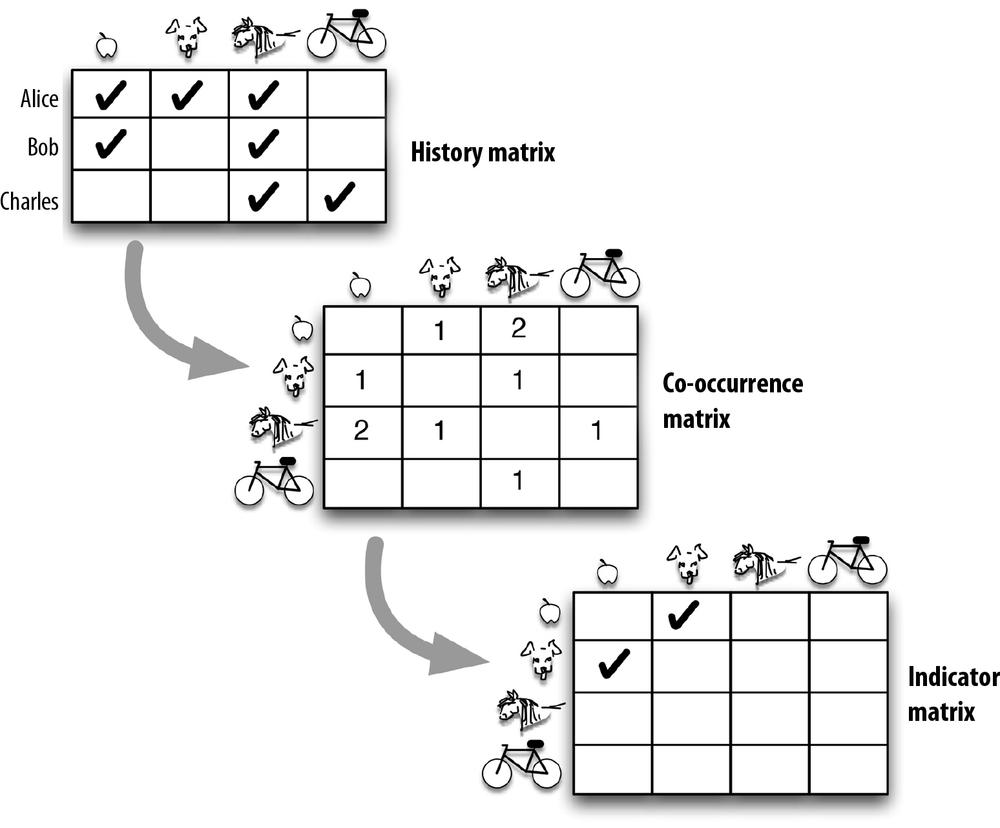
For our practical recommender, we are going to use an algorithm from the open source, scalable machine-learning library Apache Mahout to construct the recommendation model. What we want is to use Mahout’s matrix algebra to get us from user-behavior histories to useful indicators for recommendation. We will build three matrices for that purpose:
- History matrix
- Records the interactions between users and items as a user-by-item matrix
- Co-occurrence matrix
- Transforms the history matrix into an item-by-item matrix, recording which items appeared together in user histories
- Indicator matrix
- Retains only the anomalous (interesting) co-occurrences that will be the clues for recommendation
Figure 4-3 shows how we would represent that with our toy example.
Mahout’s ItemSimilarityJob runs the RowSimilarityJob, which in turn uses the log likelihood ratio test (LLR) to determine which co-occurrences are sufficiently anomalous to be of interest as indicators. So our “everybody wants a pony” observation is correct but not one of the indicators for recommendation.
Relevance Score
In order to make recommendations, we want to use items in recent user history as a query to find all items in our collection that have those recent history items as indicators. But we also want to have some way to sort items offered as recommendations in order of relevance. To do this, indicator items can be given a relevance score that is the sum of weights for each indicator. You can think of this step as giving bonus points to indicators that are most likely to give a good recommendation because they indicate something unusual or interesting about a person’s interests.
Ubiquitous items (such as ponies) are not even considered to be indicators. Fairly common indicators should have small weights. Rare indicators should have large weights. Relevance for each item to be recommended depends on the size of the sum of weighted values for indicators. Items with a large relevance score will be recommended first.
At this point, we have, in theory, all that we need to produce useful recommendations, but not yet in a manner to be used in practice. How do we deliver the recommendations to users? What will trigger the recommendations, and how do we do this in a timely manner?
In the practical recommender design, we exploit search-engine technology to easily deploy the recommender for production. Text retrieval, also known as text search, lets us store and update indicators and metadata for items, and it provides a way to quickly find items with the best indicator scores to be offered in recommendation in real time. As a bonus, a search engine lets us do conventional search as well. Among possible search engines that we could use, we chose to use Apache Solr to deploy our recommendation model. The benefits are enormous, as described in Chapter 5.
Get Practical Machine Learning: Innovations in Recommendation now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

