Chapter 1. Introduction to Serverless, Amazon Web Services, and AWS Lambda
To start off your serverless journey, we’re going to take you on a brief tour of the cloud and then define serverless. After that, we dive into Amazon Web Services (AWS)—this will be new to some of you and a refresher to others.
With those foundations set, we introduce Lambda—what it is, why you might use it, what you can build with Lambda, and how Java and Lambda work together.
A Quick History Lesson
Let’s travel back in time to 2006. No one has an iPhone yet, Ruby on Rails is a hot new programming environment, and Twitter is being launched. More germane to us, however, is that at this point in time many people are hosting their server-side applications on physical servers that they own and have racked in a data center.
In August 2006 something happened that would fundamentally change this model. Amazon’s new IT division, AWS, announced the launch of Elastic Compute Cloud (EC2).
EC2 was one of the first infrastructure-as-a-service (IaaS) products. IaaS allows companies to rent compute capacity—that is, a host to run their internet-facing server applications—rather than buying their own machines. It also allows them to provision hosts just in time, with the delay from requesting a machine to its availability being on the order of minutes. In 2006 this was all possible because of the advances in virtualization technology—all EC2 hosts at that time were virtual machines.
EC2’s five key advantages are:
- Reduced labor cost
-
Before IaaS, companies needed to hire specific technical operations staff who would work in data centers and manage their physical servers. This meant everything from power and networking to racking and installing to fixing physical problems with machines like bad RAM to setting up the operating system (OS). With IaaS all of this goes away and instead becomes the responsibility of the IaaS service provider (AWS in the case of EC2).
- Reduced risk
-
When managing their own physical servers, companies are exposed to problems caused by unplanned incidents like failing hardware. This introduces downtime periods of highly volatile length since hardware problems are usually infrequent and can take a long time to fix. With IaaS, the customer, while still having some work to do in the event of a hardware failure, no longer needs know what to do to fix the hardware. Instead the customer can simply request a new machine instance, available within a few minutes, and reinstall the application, limiting exposure to such issues.
- Reduced infrastructure cost
-
In many scenarios the cost of a connected EC2 instance is cheaper than running your own hardware when you take into account power, networking, etc. This is especially valid when you want to run hosts for a only few days or weeks, rather than many months or years at a stretch. Similarly, renting hosts by the hour rather than buying them outright allows different accounting: EC2 machines are an operating expense (Opex) rather than the capital expense (Capex) of physical machines, typically allowing much more favorable accounting flexibility.
- Scaling
-
Infrastructure costs drop significantly when considering the scaling benefits IaaS brings. With IaaS, companies have far more flexibility in scaling the numbers and types of servers they run. There is no longer a need to buy 10 high-end servers up front because you think you might need them in a few months’ time. Instead, you can start with one or two low-powered, inexpensive virtual machines (VMs) and then scale your number and types of VMs up and down over time without any negative cost impact.
- Lead time
-
In the bad old days of self-hosted servers, it could take months to procure and provision a server for a new application. If you came up with an idea you wanted to try within a few weeks, then that was just too bad. With IaaS, lead time goes from months to minutes. This has ushered in the age of rapid product experimentation, as encouraged by the ideas in Lean Startup.
The Cloud Grows
IaaS was one of the first key elements of the cloud, along with storage (e.g., AWS Simple Storage Service (S3)). AWS was an early mover in cloud services, and is still a leading provider, but there are many other cloud vendors such as Microsoft and Google.
The next evolution of the cloud was platform as a service (PaaS). One of the most popular PaaS providers is Heroku. PaaS layers on top of IaaS, abstracting the management of the host’s operating system. With PaaS you deploy just applications, and the platform is responsible for OS installation, patch upgrades, system-level monitoring, service discovery, etc.
An alternative to using a PaaS is to use containers. Docker has become incredibly popular over the last few years as a way to more clearly delineate an application’s system requirements from the nitty-gritty of the operating system itself. There are cloud-based services to host and manage/orchestrate containers on a team’s behalf, and these are often referred to as containers-as-a-service (CaaS) products. Amazon, Google, and Microsoft all offer CaaS platforms. Managing fleets of Docker containers has been made easier by use of tools like Kubernetes, either in a self-managed form or as part of a CaaS (e.g., GKE from Google, EKS from Amazon, or AKS from Microsoft).
All three of these ideas—IaaS, PaaS, and CaaS—can be grouped as compute as a service; in other words, they are different types of generic environments that we can run our own specialized software in. PaaS and CasS differ from IaaS by raising the level of abstraction further, allowing us to hand off more of our “heavy lifting” to others.
Enter Serverless
Serverless is the next evolution of cloud computing and can be divided into two ideas: backend as a service and functions as a service.
Backend as a Service
Backend as a service (BaaS) allows us to replace server-side components that we code and/or manage ourselves with off-the-shelf services. It’s closer in concept to software as a service (SaaS) than it is to things like virtual instances and containers. SaaS is typically about outsourcing business processes, though—think HR or sales tools or, on the technical side, products like GitHub—whereas with BaaS, we’re breaking up our applications into smaller pieces and implementing some of those pieces entirely with externally hosted products.
BaaS services are domain-generic remote components (i.e., not in-process libraries) that we can incorporate into our products, with an application programming interface (API) being a typical integration paradigm.
BaaS has become especially popular with teams developing mobile apps or single-page web apps. Many such teams are able to rely significantly on third-party services to perform tasks that they would otherwise have needed to do themselves. Let’s look at a couple of examples.
First up we have services like Google’s Firebase. Firebase is a database product that is fully managed by a vendor (Google in this case) that can be accessed directly from a mobile or web application without the need for our own intermediary application server. This represents one aspect of BaaS: services that manage data components on our behalf.
BaaS services also allow us to rely on application logic that someone else has implemented. A good example here is authentication—many applications implement their own code to perform sign-up, login, password management, etc., but more often than not this code is similar across many apps. Such repetition across teams and businesses is ripe for extraction into an external service, and that’s precisely the aim of products like Auth0 and Amazon’s Cognito. Both of these products allow mobile apps and web apps to have fully featured authentication and user management, but without a development team having to write or manage any of the code to implement those features.
The term BaaS came to prominence with the rise in mobile application development; in fact, the term is sometimes referred to as mobile backend as a service (MBaaS). However, the key idea of using fully externally managed products as part of our application development is not unique to mobile development, or even frontend development in general.
Functions as a Service
The other half of serverless is functions as a service (FaaS). FaaS, like IaaS, PaaS, and CaaS, is another form of compute as a service—a generic environment within which we can run our own software. Some people like to use the term serverless compute instead of FaaS.
With FaaS we deploy our code as independent functions or operations, and we configure those functions to be called, or triggered, when a specific event or request occurs within the FaaS platform. The platform itself calls our functions by instantiating a dedicated environment for each event—this environment consists of an ephemeral, fully managed lightweight virtual machine, or container; the FaaS runtime; and our code.
The result of this type of environment is that we have no concern for the runtime management of our code, unlike any other style of compute platform.
Furthermore, because of several factors of serverless in general that we describe in a moment, with FaaS we have no concern for hosts or processes, and scaling and resource management are handled on our behalf.
Differentiating Serverless
The idea of using externally hosted application components, as we do with BaaS, is not new—people have been using hosted SQL databases for a decade or more—so what makes some of these services qualify as backends as a service? And what aspects do BaaS and FaaS have in common that cause us to group them into the idea of serverless computing?
There are five key criteria that differentiate serverless services—both BaaS and FaaS—that allow us to approach architecting applications in a new way. These criteria are as follows:
- Does not require managing a long-lived host or application instance
-
This is the core of serverless. Most other ways of operating server-side software require us to deploy, run, and monitor an instance of an application (whether programmed by us or others), and that application’s lifetime spans more than one request. Serverless implies the opposite of this: there is no long-lived server process, or server host, that we need to manage. That’s not to say those servers don’t exist—they absolutely do—but they are not our concern or responsibility.
- Self auto-scales and auto-provisions, dependent on load
-
Auto-scaling is the ability of a system to adjust capacity requirements dynamically based upon load. Most existing auto-scaling solutions require some amount of work by the utilizing team. Serverless services self auto-scale from the first time you use them with no effort at all.
Serverless services also auto-provision when they perform auto-scaling. They remove all the effort of allocating capacity, both in terms of number and size of underlying resources. This is a huge operational burden lifted.
- Has costs that are based on precise usage, up from and down to zero usage
-
This is closely tied to the previous point—serverless costs are precisely correlated with usage. The cost of using a BaaS database, for instance, should be closely tied to usage, not predefined capacity. This cost should be largely derived from actual amount of storage used and/or requests made.
Note that we’re not saying costs should be solely based on usage—there may be some overhead cost for using the service in general—but the lion’s share of the costs should be proportional to fine-grained usage.
- Has performance capabilities defined in terms other than host size/count
-
It’s reasonable and useful for a serverless platform to expose some performance configuration. However, this configuration should be completely abstracted from whatever underlying instance or host types are being used.
- Has implicit high availability
-
When operating applications, we typically use the term high availability (HA) to mean that a service will continue to process requests even when an underlying component fails. With a serverless service we expect the vendor to provide HA transparently for us.
As an example, if we’re using a BaaS database, we assume that the provider is doing whatever is necessary to handle the failure of individual hosts or internal components.
What Is AWS?
We’ve talked about AWS a few times already in this chapter, and now it’s time to look at this behemoth of cloud providers in a little more detail.
Since its launch in 2006, AWS has grown at a mind-boggling rate, in terms of the number and type of service offered, the capacity that the AWS cloud provides, and the number of companies using it. Let’s look at all of those aspects.
Types of Service
AWS has more than a hundred different services. Some of these are fairly low level—networking, virtual machines, basic block storage. Above these services, in abstraction, come the component services—databases, platforms as a service, message buses. Then on top of all of these come true application components—user management, machine learning, data analysis.
Sideways of this stack are the management services necessary to work with AWS at scale—security, cost reporting, deployment, monitoring, etc.
This combination of services is shown in Figure 1-1.
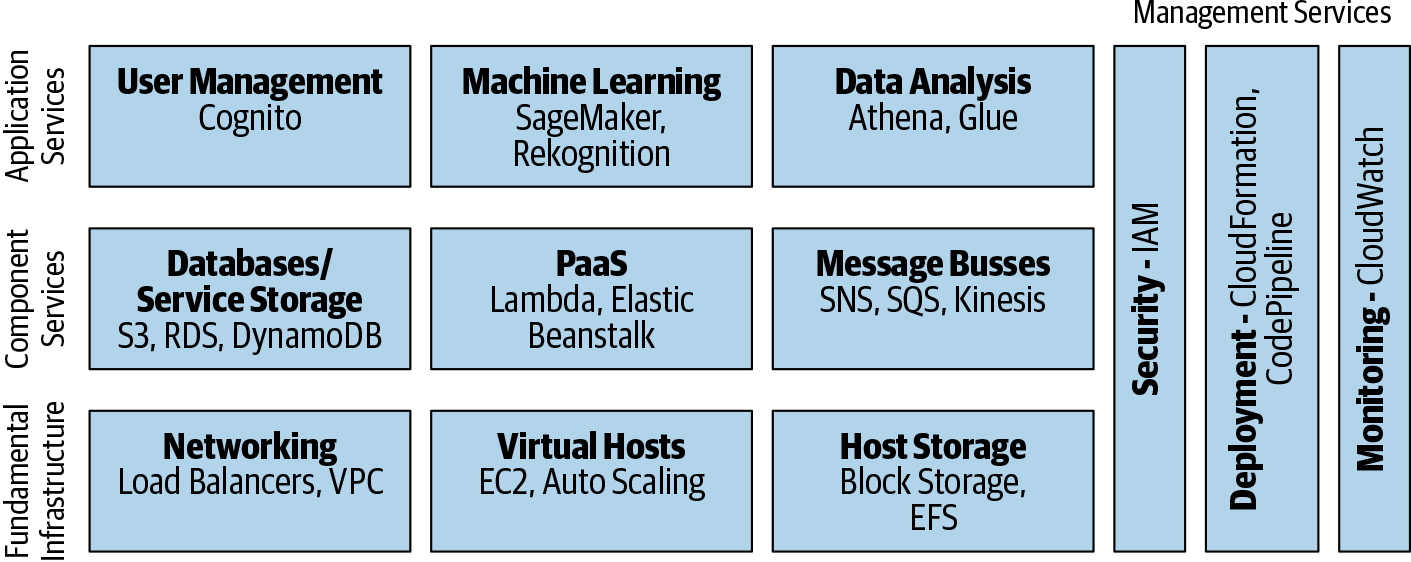
Figure 1-1. AWS service layers
AWS likes to pitch itself as the ultimate IT “Lego brick” provider—it provides a vast number of pluggable types of resources that can be joined together to create huge, massively scalable, enterprise-grade applications.
Capacity
AWS houses its computers in more than 60 data centers spread around the world as shown in Figure 1-2. In AWS terminology, each data center corresponds to an Availability Zone (AZ), and clusters of data centers in close proximity to each other are grouped into regions. AWS has more than 20 different regions, across 5 continents.
That’s a lot of computers.
While the total number of regions continues to grow, so does the capacity within each region. A vast number of US-based internet companies run their systems in the us-east-1 region in Northern Virginia (just outside Washington DC)—and the more companies that run their systems there, the more confident AWS is in increasing the number of servers available. This is a virtuous cycle between Amazon and its customers.
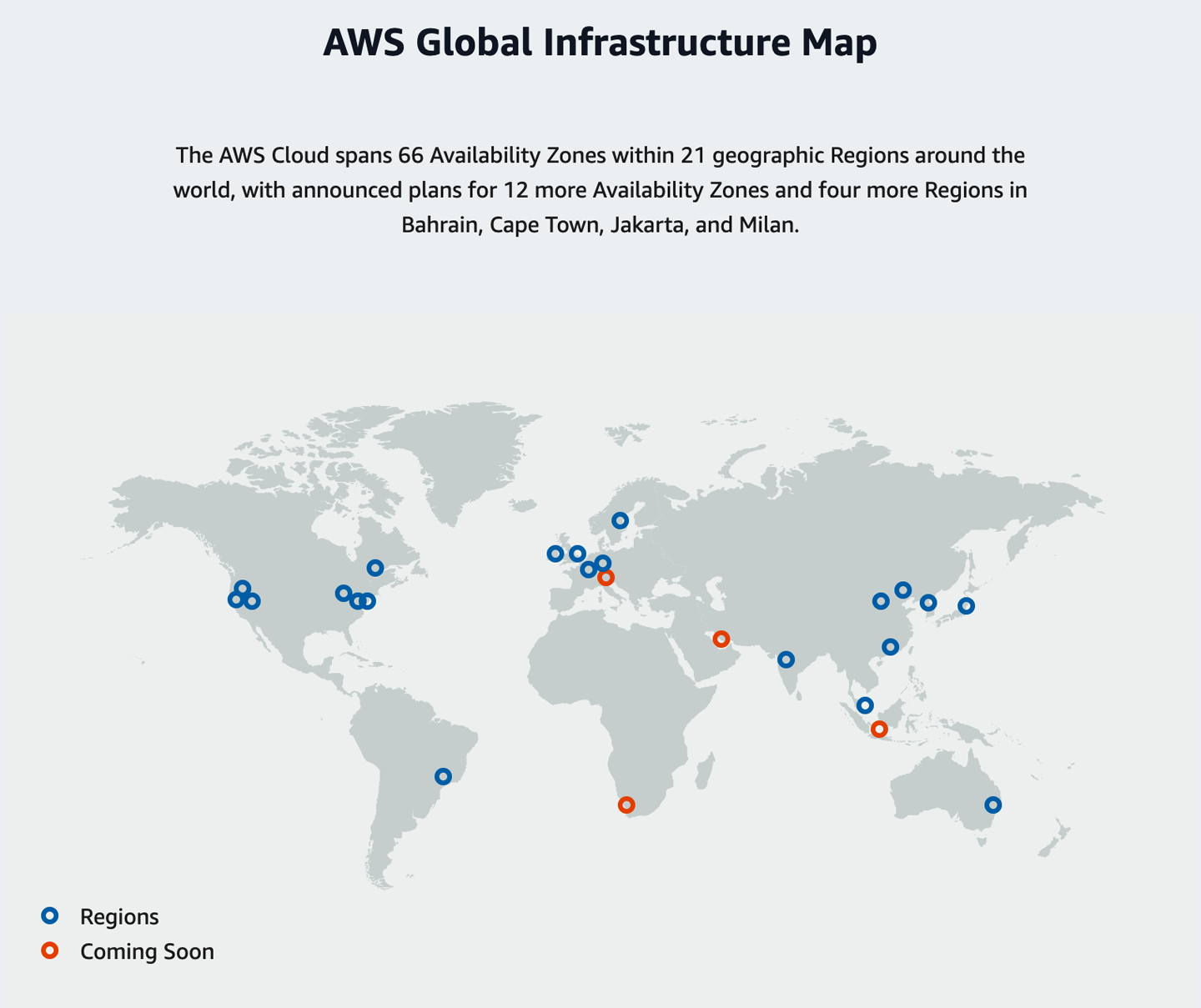
Figure 1-2. AWS regions (source: AWS)
When you use some of Amazon’s lower-level services, like EC2, you’ll typically specify an Availability Zone to use. With the higher-level services, though, you’ll usually specify only a region, and Amazon will handle any problems for you on an individual data center level.
A compelling aspect of Amazon’s region model is that each region is largely independent, logistically and from a software management point of view. That means that if a physical problem like a power outage, or a software problem like a deployment bug, happens in one region, the others will almost certainly be unaffected. The region model does make for some extra work from our point of view as users, but overall it works well.
Who Uses AWS?
AWS has a vast number of customers, spread all around the planet. Massive enterprises, governments, startups, individuals, and everyone in between use AWS. Many of the internet services you use are probably hosted on AWS.
AWS is not just for websites. Many companies have moved a lot of their “backend” IT infrastructure to AWS, finding it a more compelling option than running their own physical infrastructure.
AWS, of course, doesn’t have a monopoly. Google and Microsoft are their biggest competitors, at least in the English-speaking world, while Alibaba Cloud competes with them in the growing Chinese market. And there are plenty of other cloud providers offering services suited to specific types of customer.
How Do You Use AWS?
Your first interaction with AWS will likely be via the AWS Web Console. To do this, you will need some kind of access credential, which will give you permissions within an account. An account is a construct that maps to billing (i.e., paying AWS for the services you use), but it is also a grouping of defined service configurations within AWS. Companies tend to run a number of production applications in one account. (Accounts can also have subaccounts, but we won’t be talking about them too much in this book—just know that if you’re using credentials supplied by a company, they might be for a specific subaccount.)
If you haven’t been given credentials by your company, you’ll need to create an account. You can do this by supplying AWS with your credit card details, but know that AWS supplies a generous free tier, and if you just stick to the basic exercises in this book, you shouldn’t end up needing to pay AWS anything.
Your credentials may be in the form of a typical username and password or may be via a single sign-on (SSO) workflow (e.g., via Google Apps or Microsoft Active Directory). Either way, eventually you’ll successfully log in to the web console. Using the web console for the first time can be a daunting experience, with all 100+ AWS services craving your attention—Amazon Polly shouting “PICK ME!!!” in equal measure to a strange thing called Macie. And then of course what about all of those services known only by an acronym—what are they?
Part of the reason for the overwhelming nature of the home page of the AWS Console is because it really isn’t developed as one product—it’s developed as a hundred different products, all given a link on the home page. Also, drilling into one product may look quite different from another because each product is given a good amount of autonomy within the AWS universe. Sometimes using AWS might feel like a spelunking exercise in navigating the AWS corporate organization—don’t worry, we all feel that way.
Apart from the web console, the other way of interacting with AWS is via its extensive API. One great aspect that Amazon has had from very early in its history, even before the times of AWS, is that each service must be fully usable via a public API, and this means that for all intents and purposes anything that is possible to configure in AWS can be done via the API.
Layered on top of the API is the CLI—the command line interface—which we use in this book. The CLI is most simply described as a thin client application that communicates with the AWS API. We talk about configuring the CLI in the next chapter (“AWS Command Line Interface”).
What Is AWS Lambda?
Lambda is Amazon’s FaaS platform. We briefly mentioned FaaS earlier, but now it’s time to dig into it in some more detail.
Functions as a Service
As we introduced before, FaaS is a new way of building and deploying server-side software, oriented around deploying individual functions or operations. FaaS is where a lot of the buzz about serverless comes from; in fact, many people think that serverless is FaaS, but they’re missing out on the complete picture. While this book focuses on FaaS, we encourage you to consider BaaS too as you build out bigger applications.
When we deploy traditional server-side software, we start with a host instance, typically a VM instance or a container (see Figure 1-3). We then deploy our application, which usually runs as an operating system process, within the host. Usually our application contains code for several different but related operations; for instance, a web service may allow both retrieval and updating resources.
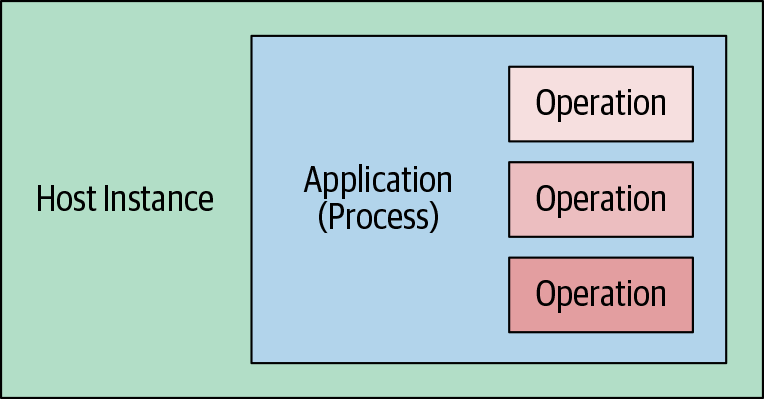
Figure 1-3. Traditional server-side software deployment
From an ownership point of view, we as users are responsible for all three aspects of this configuration—host instance, application process, and of course program operations.
FaaS changes this model of deployment and ownership (see Figure 1-4). We strip away both the host instance and the application process from our model. Instead, we focus on just the individual operations or functions that express our application’s logic. We upload those functions individually to a FaaS platform, which itself is the responsibility of the cloud vendor and not us.
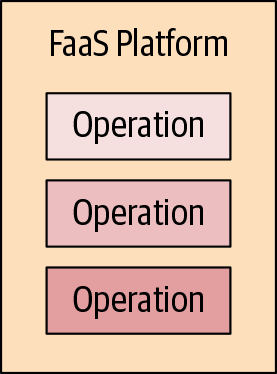
Figure 1-4. FaaS software deployment
The functions are not constantly active in an application process, though, sitting idle until they need to be run as they would in a traditional system. Instead, the FaaS platform is configured to listen for a specific event for each operation. When that event occurs, the platform instantiates the FaaS function and then calls it, passing the triggering event.
Once the function has finished executing, the FaaS platform is free to tear it down. Alternatively, as an optimization, it may keep the function around for a little while until there’s another event to be processed.
FaaS as Implemented by Lambda
AWS Lambda was launched in 2014, and it continues to grow in scope, maturity, and usage. Some Lambda functions might be very low throughput—perhaps just executing once per day, or even less frequently than that. But others may be executed billions of times per day.
Lambda implements the FaaS pattern by instantiating ephemeral, managed, Linux environments to host each of our function instances. Lambda guarantees that only one event is processed per environment at a time. At the time of writing, Lambda also requires that the function completes processing of the event within 15 minutes; otherwise, the execution is aborted.
Lambda provides an exceptionally lightweight programming and deployment model—we just provide a function, and associated dependencies, in a ZIP or JAR file, and Lambda fully manages the runtime environment.
Lambda is tightly integrated with many other AWS services. This corresponds to many different types of event source that can trigger Lambda functions, and this leads to the ability to build many different types of applications using Lambda.
Lambda is a fully serverless service, as defined by our differentiating criteria from earlier, specifically:
- Does not require managing a long-lived host or application instance
-
With Lambda we are fully abstracted from the underlying host running our code. Furthermore, we do not manage a long-lived application—once our code has finished processing a particular event, AWS is free to terminate the runtime environment.
- Self auto-scales and auto-provisions, dependent on load
-
This is one of the key benefits of Lambda—resource management and scaling is completely transparent. Once we upload our function code, the Lambda platform will create just enough environments to handle the load at any particular time. If one environment is enough then Lambda will create the environment when it is needed. If on the other hand hundreds of separate instances are required, then Lambda will scale out quickly and without any effort on our part.
- Has costs that are based on precise usage, up from and down to zero usage
-
AWS charges for Lambda only for the time that our code is executing per environment, down to a 100 ms precision. If our function is active for 200 ms every 5 minutes, then we’ll be charged only for 2.4 seconds of usage per hour. This precise usage cost structure is the same whether one instance of our function is required or a thousand.
- Has performance capabilities defined in terms other than host size/count
-
Since we are fully abstracted from the underlying host with Lambda, we can’t specify a number or type of underlying EC2 instances to use. Instead, we specify how much RAM our function requires (up to a maximum of 3GB), and other aspects of performance are tied to this too. We explore this in more detail later in the book—see “Memory and CPU”.
- Has implicit high availability
-
If a particular underlying host fails, then Lambda will automatically start environments on a different host. Similarly, if a particular data center/Availability Zone fails, then Lambda will automatically start environments in a different AZ in the same region. Note that it’s on us as AWS customers to handle a region-wide failure, and we talk about this toward the end of the book—see “Globally Distributed Applications”.
Why Lambda?
The basic benefits of the cloud, as we described earlier, apply to Lambda—it’s often cheaper to run in comparison to other types of host platform; it requires less effort and time to operate a Lambda application; and the scaling flexibility of Lambda surpasses any other compute option within AWS.
However, the key benefit from our perspective is how quickly you can build applications with Lambda when combined with other AWS services. We often hear of companies building brand new applications, deployed to production, in just a day or two. Being able to remove ourselves from so much of the infrastructure-related code we often write in regular applications is a huge time-saver.
Lambda also has more capacity, more maturity, and more integration points than any other FaaS platform. It’s not perfect, and some other products in our opinion offer better “developer UX” than Lambda. But absent any strong tie to an existing cloud vendor, we would recommend AWS Lambda for all of the reasons listed earlier.
What Does a Lambda Application Look Like?
Traditional long-running server applications often have at least one of two ways of starting work for a particular stimulus—they either open up a TCP/IP socket and wait for inbound connections or have an internal scheduling mechanism that will cause them to reach out to a remote resource to check for new work. Since Lambda is fundamentally an event-oriented platform and since Lambda enforces a timeout, neither of these patterns is applicable to a Lambda application. So how do we build a Lambda application?
The first point to consider is that at the lowest level Lambda functions can be invoked (called) in one of two ways:
-
Lambda functions can be called synchronously—named
RequestResponseby AWS. In this scenario, an upstream component calls the Lambda function and waits for whatever response the Lambda function generates. -
Alternatively, a Lambda function may be invoked asynchronously—named
Eventby AWS. This time the request from the upstream caller is responded to immediately by the Lambda platform, while the Lambda function proceeds with processing the request. No further response is returned to the caller in this scenario.
These two invocation models have various other behaviors, which we get into later, starting with “Invocation Types”. For now let’s see how they are used in some example applications.
Web API
An obvious question to ask is whether Lambda can be used in the implementation of an HTTP API, and fortunately the answer is yes! While Lambda functions aren’t HTTP servers themselves, we can use another AWS component, API Gateway, to provide the HTTP protocol and routing logic that we typically have within a web service (see Figure 1-5).
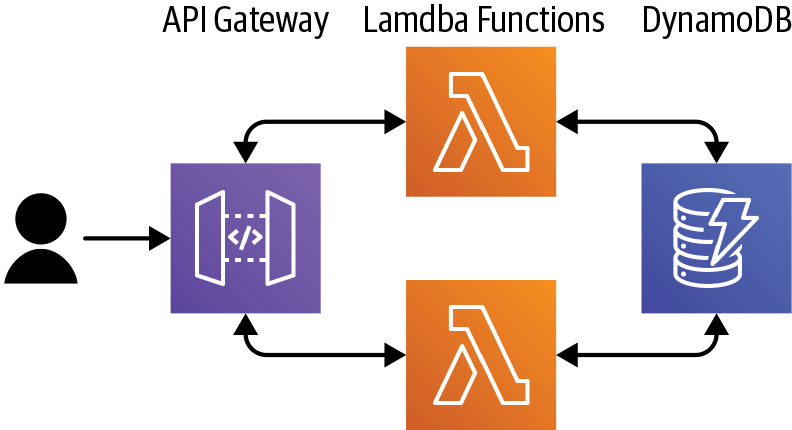
Figure 1-5. Web API using AWS Lambda
The above diagram shows a typical API as used by a single-page web app or by a mobile application. The user’s client makes various calls, via HTTP, to the backend to retrieve data and/or initiate requests. In our case, the component that handles the HTTP aspects of the request is Amazon API Gateway—it is an HTTP server.
We configure API Gateway with a mapping from request to handler (e.g., if a client makes a request to
GET /restaurants/123, then we can set up API Gateway to call a Lambda function named
RestaurantsFunction, passing the details of the request). API Gateway will invoke the Lambda
function synchronously and will wait for the function to evaluate the request and return a
response.
Since the Lambda function instance isn’t itself a remotely callable API, the API Gateway actually
makes a call to the Lambda platform, specifying the Lambda function to invoke, the type of
invocation (RequestResponse), and the request parameters. The Lambda platform then instantiates an
instance of RestaurantsFunction and invokes that with the request parameters.
The Lambda platform does have a few limitations, like the maximum timeout we’ve already mentioned,
but apart from that, it’s pretty much a standard Linux environment. In RestaurantsFunction we can,
for example, make a call to a database—Amazon’s DynamoDB is a popular database to use with Lambda,
partly due to the similar scaling capabilities of the two services.
Once the function has finished its work, it returns a response, since it was called in a synchronous fashion. This response is passed by the Lambda platform back to API Gateway, which transforms the response into an HTTP response message, which is itself passed back to the client.
Typically a web API will satisfy multiple types of requests, mapped to different HTTP paths and verbs (like GET, PUT, POST, etc.). When developing a Lambda-backed web API, you will usually implement different types of requests as different Lambda functions, although you are not forced to use such a design—you can handle all requests as one function if you’d like and switch logic inside the function based on the original HTTP request path and verb.
File processing
A common use case for Lambda is file processing. Let’s imagine a mobile application that can upload photos to a remote server, which we then want to make available to other parts of our product suite, but at different image sizes, as shown in Figure 1-6.
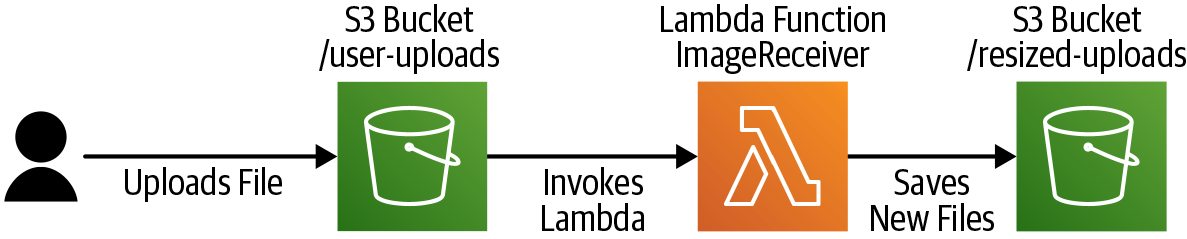
Figure 1-6. File processing using AWS Lambda
S3 is Amazon’s Simple Storage Service—the very same that was launched in 2006. Mobile applications can upload files to S3 via the AWS API, in a secure fashion.
S3 can be configured to invoke the Lambda platform when the file is uploaded, specifying the
function to be called, and passing a path to the file. As with the previous example, the Lambda
platform then instantiates the Lambda function and calls it with the request details passed this
time by S3. The difference now, though, is that this is an asynchronous invocation (S3 specified the
Event invocation type)—no value is returned to S3 nor does S3 wait for a return value.
This time our Lambda function exists solely for the purpose of a side effect—it loads the file specified by the request parameter and then creates new, resized versions of the file in a different S3 bucket. With the side effects complete, the Lambda function’s work is done. Since it created files in an S3 bucket, we may choose to add a Lambda trigger to that bucket also, invoking further Lambda functions that process these generated files, creating a processing pipeline.
Other examples of Lambda applications
The previous two examples show two scenarios, with two different Lambda event sources. There are many other event sources that enable us to build many other types of applications. Just some of these are as follows:
-
We can build message-processing applications, using message buses like Simple Notification Service (SNS), Simple Queue Service (SQS), EventBridge, or Kinesis as the event source.
-
We can build email-processing applications, using Simple Email Service (SES) as the event source.
-
We can build scheduled-task applications, similar to cron programs, using CloudWatch Scheduled Events as the trigger.
Note that many of these services other than Lambda are BaaS services and therefore also serverless. Combining FaaS and BaaS to produce serverless architectures is an extraordinarily powerful technique due to their similar scaling, security, and cost characteristics. In fact, it’s such combinations of service that are driving the popularity of serverless computing.
We talk in depth about building applications in this way in Chapter 5.
AWS Lambda in the Java World
AWS Lambda natively supports a large number of languages. JavaScript and Python are very popular “getting started” languages for Lambda (as well as for significant production applications) partly because of their dynamically typed, noncompiled nature allowing for very fast development cycles.
We both got our start, however, using Lambda with Java. Java occasionally has a bad reputation in the Lambda world—some of which is fair, and some not. If what you need in a Lambda function can be expressed in 10 lines or so, it’s typically quicker to put something together in JavaScript or Python. However, for larger applications, there are many excellent reasons to implement Lambda functions in Java, a couple of which are as follows:
-
If you or your team is more familiar with Java than the other Lambda-supported languages, then you’ll have the ability to reuse these skills and libraries in a new runtime platform. Java is as much a “first-class language” in the Lambda ecosystem as JavaScript, Python, Go, etc., are—Lambda is not limiting you if you use Java. Further, if you already have a lot of code implemented in Java, then porting some of this to Lambda can be a significant time-to-market advantage, in comparison to reimplementing in a different language.
-
In high throughput messaging systems, the typical runtime performance benefit of Java over JavaScript or Python can be significant. Not only is “faster” normally “better” in any system, with Lambda “faster” can also result in tangible cost benefits due to Lambda’s pricing model.
For JVM workloads, Lambda natively supports, at the time of writing, the Java 8 and Java 11 runtimes. The Lambda platform will instantiate a version of the Java Runtime Environment within its Linux environment and then run our code within that Java VM. Our code, therefore, must be compatible with that runtime environment, but we’re not restricted to just using the Java language. Scala, Clojure, Kotlin, and more, can all be run on Lambda (see more at “Other JVM Languages and Lambda”).
There’s also an advanced option with Lambda to define your own runtime if neither of these Java versions is sufficient—we discuss this further in “Custom Runtimes”.
The Lambda platform supplies a few basic libraries with the runtime (e.g., a small subset of the AWS Java library) but any other libraries that your code needs must be supplied with your code itself. You will learn how to do that in “Build and Package”.
Finally, while Java has the programming construct of Lambda expressions, these are unrelated to AWS Lambda functions. You are free to use Java Lambda expressions within your AWS Lambda function if you’d like (since AWS Lambda supports Java 8 and later) or not.
Summary
In this chapter, you learned how serverless computing is the next evolution of the cloud—a way of building applications by relying on services that handle resource management, scaling, and more, transparently and without configuration.
Further, you now understand that functions as a service (FaaS) and backend as a service (BaaS) are the two halves of serverless, with FaaS being the general-purpose computing paradigm within serverless. For more information on serverless in general, we refer you to our free O’Reilly ebook What Is Serverless?
You also have at least a basic knowledge of Amazon Web Services—one of the world’s most popular cloud platforms. You’ve learned about the vast capacity that AWS has to host our applications and how you access AWS both via the web console and the API/CLI.
You’ve been introduced to AWS Lambda—Amazon’s FaaS product. We compared “thinking in Lambda” to a traditionally built application, talked about why you may want to use Lambda versus other FaaS implementations, and then gave some examples of applications built using Lambda.
Finally, you saw a quick overview of Java as a Lambda language option.
In Chapter 2 we implement our first Lambda function—get ready for a brave new world!
Exercises
-
Acquire credentials for an AWS account. The easiest way to do this is by creating a new account. As we mentioned earlier, if you do this, you’ll need to supply a credit card number, but everything we do in this book should be covered by the free tier, unless you get very enthusiastic with tests!
Alternatively you can use an existing AWS account, but if so, we recommend using a “development” account so as not to interfere with any “production” systems.
We also strongly recommend that whatever access you use grants you full administrative permissions within the account; otherwise, you’ll be bogged down by distracting security issues.
-
Log in to the AWS Console. Find the Lambda section—are there any functions there yet?
-
Extended task: Look at Amazon’s serverless marketing page, specifically where it describes the various services in its “serverless platform.” Which of these services fully satisfy the differentiating criteria of a serverless service we described earlier? Which don’t, and in what ways are they “mostly” serverless?
Get Programming AWS Lambda now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

