Chapter 4. Imperative Programming
Until now most programs we have written have been pure, meaning that they never changed state. Whenever a function does something other than just return a value, it is known as a side effect. While pure functions have some interesting features like composability, the fact of the matter is that programs aren’t interesting unless they do something: save data to disk, print values to the screen, issue network traffic, and so on. These side effects are where things actually get done.
This chapter will cover how to change program state and alter control flow, which is known as imperative programming. This style of programming is considered to be more error-prone than functional programming because it opens up the opportunity for getting things wrong. The more detailed the instructions you give the computer to branch, or write certain values into certain memory locations, the more likely the programmer will make a mistake. When you programmed in the functional style, all of your data was immutable, so you couldn’t assign a wrong value by accident. However, if used judiciously, imperative programming can be a great boon for F# development.
Some potential benefits for imperative programming are:
Improved performance
Ease of maintenance through code clarity
Interoperability with existing code
Imperative programming is a style in which the program performs tasks by altering data in memory. This typically leads to patterns where programs are written as a series of statements or commands. Example 4-1 shows a hypothetical program for using a killer robot to take over the earth. The functions don’t return values, but do impact some part of the system, such as updating an internal data structure.
let robot = new GiantKillerRobot()
robot.Initialize()
robot.EyeLaserIntensity <- Intensity.Kill
robot.Target <- [| Animals; Humans; Superheroes |]
// Sequence for taking over the Earth
let earth = Planets.Earth
while robot.Active && earth.ContainsLife do
if robot.CurrentTarget.IsAlive then
robot.FireEyeLaserAt(robot.CurrentTarget)
else
robot.AquireNextTarget()Although the code snippet makes taking over the earth look fairly
easy, you don’t see all the hard work going on behind the scenes. The
Initialize function may require powering
up a nuclear reactor; and if Initialize
is called twice in a row, the reactor might explode. If Initialize were written in a purely functional
style, its output would depend only on the function’s input. Instead, what
happens during the function call to Initialize depends on the current state of
memory.
While this chapter won’t teach you how to program planet-conquering
robots, it will detail how to write F# programs that can change the
environment they run in. You will learn how to declare
variables, whose values you can change during the
course of your program. You’ll learn how to use mutable collection types,
which offer an easier-to-use alternative to F#’s list type. Finally, you will learn about control
flow and exceptions, allowing you to alter the order in which code
executes.
Understanding Memory in .NET
Before you can start making changes to memory, you first need to understand how memory works in .NET. Values in .NET applications are stored in one of two locations: on the stack or in the heap. (Experienced programmers may already be familiar with these concepts.) The stack is a fixed amount of memory for each process where local variables are stored. Local variables are temporary values used only for the duration of the function, like a loop counter. The stack is relatively limited in space, while the heap (also called RAM) may contain several gigabytes of data. .NET uses both the stack and the heap to take advantage of the cheap memory allocations on the stack when possible, and store data on the heap when more memory is required.
The area in memory where a value is stored affects how you can use it.
Value Types Versus Reference Types
Values stored on the stack are known as value types, and values stored on the heap are known as reference types.
Value types have a fixed size of bytes on the stack. int and float are both examples of value types,
because their size is constant. Reference types, on the other hand, only
store a pointer on the stack, which is the
address of some blob of memory on the heap. So while the pointer has a
fixed size—typically four or eight bytes—the blob of memory it points to
can be much larger. list and string are both examples of reference
types.
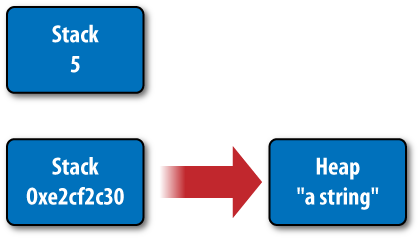
This is visualized in Figure 4-1. The integer 5 exists on the stack, and has no counterpart
on the heap. A string, however, exists on the stack as a memory address,
pointing to some sequence of characters on the heap.
Default Values
So far, each value we have declared in F# has been initialized as soon as it has been created, because in the functional style of programming values cannot be changed once declared. In imperative programming, however, there is no need to fully initialize values because you can update them later. This means there is a notion of a default value for both value and reference types, that is, the value something has before it has been initialized.
To get the default value of a type, use the type function Unchecked.defaultof<'a>. This will
return the default value for the type specified.
Note
A type function is a special type of function that takes no arguments other than a generic type parameter. There are several helpful type functions that we will explore in forthcoming chapters:
Unchecked.defaultof<'a>Gets the default value for
'atypeof<'a>Returns the
System.Typeobject describing'asizeof<'a>Returns the underlying stack size of
'a
For value types, their default value is simply a zero-bit pattern.
Because the size of a value type is known once it is created, its size
in bytes is allocated on the stack, with each byte being given the value
0b00000000.
The default value for reference types is a little more
complicated. Before reference types are initialized they first point to
a special address called null. This is used to
indicate an uninitialized reference type.
In F#, you can use the null
keyword to check if a reference type is equal to null. The following code defines a function to
check if its input is null or not,
and then calls it with an initialized and an uninitialized string
value:
> let isNull = functionnull-> true | _ -> false;; val isNull : obj -> bool > isNull "a string";; val it : bool = false > isNull (null: string);; val it : bool = true
However, reference types defined in F# do not have null as a proper value, meaning that they
cannot be assigned to be null:
> type Thing = Plant | Animal | Mineral;;
type Thing =
| Plant
| Animal
| Mineral
> // ERROR: Thing cannot be null
let testThing thing =
match thing with
| Plant -> "Plant"
| Animal -> "Animal"
| Mineral -> "Mineral"
| null -> "(null)";;
| null -> "(null)";;
------^^^^^
stdin(9,7): error FS0043: The type 'Thing' does not have 'null' as a proper value.This seems like a strange restriction, but it eliminates the need
for excessive null checking. (If you
call a method on an uninitialized reference type, your program will
throw a NullReferenceException,
so defensively checking all function parameters for null is typical.) If you do need to represent
an uninitialized state in F#, consider using the Option type instead of a reference type with
value null, where the value None represents an uninitialized state and
Some('a) represents an initialized
state.
Note
You can attribute some F# types to accept null as a proper value to ease
interoperation with other .NET languages; see Appendix B for more information.
Reference Type Aliasing
It is possible that two reference types point to the same memory address on the heap. This is known as aliasing. When this happens, modifying one value will silently modify the other because they both point to the same memory address. This situation can lead to bugs if you aren’t careful.
Example 4-2 creates one instance
of an array (which we’ll cover
shortly), but it has two values that point to the same instance.
Modifying value x also modifies
y and vice versa.
> // Value x points to an array, while y points // to the same value that x does let x = [| 0 |] let y = x;; val x : int array = [|0|] val y : int array = [|0|] >// If you modify the value of x...x.[0] <- 3;; val it : unit = () >// ... x will change...x;; val it : int array = [|3|] >// ... but so will y...y;; val it : int array = [|3|]
Changing Values
Now that you understand the basics of where and how data is
stored in .NET, you can look at how to change that data. Mutable values are those that you can
change, and can be declared using the mutable keyword. To
change the contents of a mutable value, use the left arrow operator, <-:
> letmutablemessage = "World";; val mutable message : string = "World" > printfn "Hello, %s" message;; Hello, World val it : unit = () > message<-"Universe";; val it : unit = () > printfn "Hello, %s" message;; Hello, Universe val it : unit = ()
There are several limitations on mutable values, all stemming from
security-related CLR restrictions. This prevents you from
writing some code using mutable values. Example 4-3 tries to define an
inner-function incrementX, which
captures a mutable value x in its
closure (meaning it can access x, even
though it wasn’t passed in as a parameter). This leads to an error from
the F# compiler because mutable values can only be used in the same
function they are defined in.
> // ERROR: Cannot use mutable values except in the function they are defined
let invalidUseOfMutable() =
let mutable x = 0
let incrementX() = x <- x + 1
incrementX()
x;;
let incrementX() = x <- x + 1
-----------------------^^^^^^^^^^^
stdin(16,24): error FS0407: The mutable variable 'x' is used in an invalid way.
Mutable variables may not be captured by closures. Consider eliminating this use
of mutation or using a heap-allocated mutable reference cell via 'ref' and '!'.The full list of restrictions related to mutable values is as follows:
Mutable values cannot be returned from functions (a copy is made instead).
Mutable values cannot be captured in inner-functions (closures).
If you ever run into one of these issues, the simple workaround is
to store the mutable data on the heap using a ref cell.
Reference Cells
The ref type, sometimes
referred to as a ref
cell, allows you to store mutable data on the
heap, enabling you to bypass limitations with mutable
values that are stored on the stack. To retrieve the value of a ref cell, use the ! symbolic operator and
to set the value use the := operator.
ref is not only the
name of a type, but also the name of a function that produces ref values, which has the signature:
val ref: 'a -> 'a ref
The ref function takes a value
and returns a copy of it wrapped in a ref cell. Example 4-4 shows passing a list of
planets to the ref function and then
later altering the contents of the returned ref cell.
let planets =
ref [
"Mercury"; "Venus"; "Earth";
"Mars"; "Jupiter"; "Saturn";
"Uranus"; "Neptune"; "Pluto"
]
// Oops! Sorry Pluto...
// Filter all planets not equal to "Pluto"
// Get the value of the planets ref cell using (!),
// then assign the new value using (:=)
planets := !planets |> List.filter (fun p -> p <> "Pluto")Warning
C# programmers should take care when using ref types and Boolean values. !x is simply the value of x, not the Boolean not function applied to x:
> let x = ref true;; val x : bool ref > !x;; val it : bool = true
The F# library has two functions, decr and incr, to simplify
incrementing and decrementing int ref
types:
> let x = ref 0;;
val x : int ref = {contents = 0;}
> incr x;;
val it : unit = ()
> x;;
val it : int ref = {contents = 1;}
> decr x;;
val it : unit = ()
> x;;
val it : int ref = {contents = 0;}Mutable Records
Mutability can be applied to more than just single values;
record fields can be marked as mutable as well. This allows you
to use records with the imperative style. To make a record field
mutable, simply prefix the field name with the mutable keyword.
The following example creates a record with a mutable field
Miles, which can be modified as if it
were a mutable variable. Now you can update record fields without being
forced to clone the entire record:
> // Mutable record types
open System
type MutableCar = { Make : string; Model : string; mutable Miles : int }
let driveForASeason car =
let rng = new Random()
car.Miles <- car.Miles + rng.Next() % 10000;;
type MutableCar =
{Make: string;
Model: string;
mutable Miles: int;}
val driveForASeason : MutableCar -> unit
> // Mutate record fields
let kitt = { Make = "Pontiac"; Model = "Trans Am"; Miles = 0 }
driveForASeason kitt
driveForASeason kitt
driveForASeason kitt
driveForASeason kitt;;
val kitt : MutableCar = {Make = "Pontiac";
Model = "Trans Am";
Miles = 4660;}Arrays
Until now, when you’ve needed to join multiple pieces of data together, you’ve used lists. Lists are extremely efficient at adding and removing elements from the beginning of a list, but they aren’t ideal for every situation. For example, random access of list elements is very slow. In addition, if you needed to change the last element of a list, you would need to clone the entire list. (The performance characteristics of lists will be covered more in-depth in Chapter 7.)
When you know ahead of time how many items you will need in your collection and would like to be able to update any given item, arrays are the ideal type to use.
Arrays in .NET are a contiguous block of memory containing zero or more elements, each of which can be modified individually (unlike lists, which are immutable).
Arrays can be constructed using array comprehensions, which are
identical to list comprehensions (discussed in Chapter 2), or manually via a list of values separated by semicolons and enclosed between [| |]:
> // Using the array comprehension syntax let perfectSquares =[| for i in 1 .. 7 -> i * i |];; val perfectSquares : int array > perfectSquares;; val it : int array = [|1; 4; 9; 16; 25; 36; 49|] > // Manually declared let perfectSquares2 =[|1; 4; 9; 16; 25; 36; 49; 64; 81|];; val perfectSquares2 : int array
Indexing an Array
To retrieve an element from the array, you can use an
indexer, .[], which is
a zero-based index into the array:
> // Indexing an array
printfn
"The first three perfect squares are %d, %d, and %d"
perfectSquares.[0]
perfectSquares.[1]
perfectSquares.[2];;
The first three perfect squares are 1, 4, and 9
val it : unit = ()Example 4-5 uses array indexers to change individual characters of a character array to implement a primitive form of encryption known as ROT13. ROT13 works by simply taking each letter and rotating it 13 places forward in the alphabet. This is achieved in the example by converting each letter to an integer, adding 13, and then converting it back to a character.
open System
// Encrypt a letter using ROT13
let rot13Encrypt (letter : char) =
// Move the letter forward 13 places in the alphabet (looping around)
// Otherwise ignore.
if Char.IsLetter(letter) then
let newLetter =
(int letter)
|> (fun letterIdx -> letterIdx - (int 'A'))
|> (fun letterIdx -> (letterIdx + 13) % 26)
|> (fun letterIdx -> letterIdx + (int 'A'))
|> char
newLetter
else
letter
// Loop through each array element, encrypting each letter
let encryptText (text : char[]) =
for idx = 0 to text.Length - 1 do
let letter = text.[idx]
text.[idx] <- rot13Encrypt letter
let text =
Array.ofSeq "THE QUICK BROWN FOX JUMPED OVER THE LAZY DOG"
printfn "Origional = %s" <| new String(text)
encryptText(text)
printfn "Encrypted = %s" <| new String(text)
// A unique trait of ROT13 is that to decrypt, simply encrypt again
encryptText(text)
printfn "Decrypted = %s" <| new String(text)The output of our simple program is:
Origional = THE QUICK FOX JUMPED OVER THE LAZY DOG Encrypted = GUR DHVPX SBK WHZCRQ BIRE GUR YNML QBT Decrypted = THE QUICK FOX JUMPED OVER THE LAZY DOG
Warning
Unlike C# and VB.NET, indexers in F# require using the dot notation. You can think of an indexer, then, as just another method or property:
// Incorrect x[0] // Correct x.[0]
Attempting to access an element in the array with an index either
less than zero or greater than or
equal to the number of elements in the array will raise an IndexOutOfRangeException exception.
(Exceptions will be covered later in this chapter.) Fortunately, arrays
have a Length property, which will
return the number of items in the array. Because array indexes are
zero-based, you need to subtract 1 from Length to get the index of the last element in
the array:
> let alphabet = [| 'a' .. 'z' |];;
val alphabet : char array
> // First letter
alphabet.[0];;
val it : char = 'a'
> // Last leter
alphabet.[alphabet.Length - 1];;
val it : char = 'z'
> // Some non-existant letter
alphabet.[10000];;
System.IndexOutOfRangeException: Index was outside the bounds of the array.
at <StartupCode$FSI_0012>.$FSI_0012._main()
stopped due to errorArray Slices
When you’re analyzing data stored in arrays, it is sometimes convenient to just work with a subset of the data. In F#, there is a special syntax for taking a slice of an array, where you specify optional lower and upper bounds for the subset of data. The syntax for taking a slice is:
array.[lowerBound..upperBound]
If no lower bound is specified, 0 is used. If no upper bound is specified, the
length of the array -1 is used. If
neither a lower nor upper bound is specified, you can us an * to copy the entire
array.
Example 4-6 shows the various ways for taking a slice of an array, but we will break it down line by line shortly.
open System let daysOfWeek = Enum.GetNames( typeof<DayOfWeek> ) // Standard array slice, elements 2 through 4 daysOfWeek.[2..4]// Just specify lower bound, elements 4 to the end daysOfWeek.[4..]// Just specify an upper bound, elements 0 to 2 daysOfWeek.[..2]// Specify no bounds, get all elements (copies the array) daysOfWeek.[*]
The first way we sliced an array was specifying both an upper and lower bound; this returned all array elements within that range:
> // Standard array slice, elements 2 through 4
daysOfWeek.[2..4];;
val it : string [] = [|"Tuesday"; "Wednesday"; "Thursday"|]Next we specified just a lower or just an upper bound. This returns each element from the lower bound to the end of the array, or from the beginning of the array to the upper bound:
> // Just specify lower bound, elements 4 to the end daysOfWeek.[4..];; val it : string [] = [|"Thursday"; "Friday"; "Saturday"|] > // Just specify an upper bound, elements 0 to 2 daysOfWeek.[..2];; val it : string [] = [|"Sunday"; "Monday"; "Tuesday"|]
And finally we just copied the entire array using *. Note that for every slice operation a new
array is returned, so there will never be problems with aliasing:
> // Specify no bounds, get all elements (copies the array)
daysOfWeek.[*];;Creating Arrays
Array comprehensions and manually specifying each element
aren’t the only ways to construct arrays. You can also use the Array.init function; Array.init takes a function used to generate
each array element based on its index. To create an uninitialized array,
use the Array.zeroCreate function.
With that function, each element is initialized to its default value:
zero or null.
Example 4-7 shows how
to use Array.init and Array.zeroCreate to construct arrays.
> // Initialize an array of sin-wave elements let divisions = 4.0 let twoPi = 2.0 * Math.PI;; val divisions : float = 4.0 val twoPi : float = 6.283185307 > Array.init (int divisions) (fun i -> float i * twoPi / divisions);; val it : float array = [|0.0; 1.570796327; 3.141592654; 4.71238898|] > // Construct empty arrays let emptyIntArray : int array =Array.zeroCreate 3let emptyStringArray : string array =Array.zeroCreate 3;; val emptyIntArray : int array = [|0; 0; 0|] val emptyStringArray : string array = [|null; null; null|]
Pattern Matching
Pattern matching against arrays is just as easy as using
lists. And just like pattern matching against lists, when matching
against arrays, you can capture element values, as well as match against
the structure of the array. Example 4-8 shows matching an array
value against null or an array with
0, 1, or 2 elements.
> // Describe an array
let describeArray arr =
match arr with
| null -> "The array is null"
| [| |] -> "The array is empty"
| [| x |] -> sprintf "The array has one element, %A" x
| [| x; y |] -> sprintf "The array has two elements, %A and %A" x y
| a -> sprintf "The array had %d elements, %A" a.Length a;;
val describeArray : 'a array -> string
> describeArray [| 1 .. 4 |];;
val it : string = "The array had 4 elements, [|1; 2; 3; 4|]"
> describeArray [| ("tuple", 1, 2, 3) |];;
val it : string = "The array has one element, ("tuple", 1, 2, 3)"Array Equality
Arrays in F# are compared using structural equality. Two arrays are considered equal if they have the same rank, length, and elements. (Rank is the dimensionality of the array, something we will cover in the next section.)
> [| 1 .. 5 |] = [| 1; 2; 3; 4; 5 |];; val it : bool = true > [| 1 .. 3 |] = [| |];; val it : bool = false
Note
This is different from the behavior of equality on
arrays in C#. In F#, the = operator
contains special logic for comparing arrays so the default referential
equality is not used. For more information on object equality in .NET,
refer to Chapter 5.
Array Module Functions
Just like the List and
Seq modules, there is an Array module detailed in Table 4-1 that contains nearly
identical functions for manipulating arrays.
Function | Description |
| Returns the length of an
array. Arrays already have a |
| Creates a new array with the given number of elements; each element is initialized by the result of the provided function. |
| Creates an array with the given length where each entry is the type’s default value. |
| Tests if any element in the array satisfies the given function. |
partition
Array.partition divides the
given array into two new arrays. The first array contains only
elements where the provided function returns true; the second array contains elements
where the provided function returns false:
> // Simple Boolean function
let isGreaterThanTen x =
if x > 10
then true
else false;;
val isGreaterThanTen : int -> bool
> // Partitioning arrays
[| 5; 5; 6; 20; 1; 3; 7; 11 |]
|> Array.partition isGreaterThanTen;;
val it : int array * int array = ([|20; 11|], [|5; 5; 6; 1; 3; 7|])tryFind and tryFindIndex
Array.tryFind returns
Some of the first element for which
the given function returns true.
Otherwise, it returns None.
Array.tryFindIndex works just like
Array.tryFind, except rather than
returning the element, it returns its index in the array:
> // Simple Boolean function
let rec isPowerOfTwo x =
if x = 2 then
true
elif x % 2 = 1 (* is odd *) then
false
else isPowerOfTwo (x / 2);;
val isPowerOfTwo : int -> bool
> [| 1; 7; 13; 64; 32 |]
|> Array.tryFind isPowerOfTwo;;
val it : int option = Some 64
> [| 1; 7; 13; 64; 32 |]
|> Array.tryFindIndex isPowerOfTwo;;
val it : int option = Some 3Note
Array.tryFind and
Array.tryFindIndex illustrate why
the Option type is so
powerful. In C#, functions similar to tryFindIndex will return −1 to indicate failure (opposed to
None). However, if you are trying
to implement tryFind, −1 could indicate either a failure to find
an array element or finding an element with value −1.
Aggregate operators
The Array module also
contains the aggregate operators of the List module, namely: fold, foldBack, map, and iter. In addition, there are also
index-aware versions of these methods. Example 4-9 demonstrates the
iteri function, which behaves just
like iter except that in addition
to the array element, the element’s index is provided as well.
> let vowels = [| 'a'; 'e'; 'i'; 'o'; 'u' |];;
val vowels : char array = [|'a'; 'e'; 'i'; 'o'; 'u'|]
> Array.iteri (fun idx chr -> printfn "vowel.[%d] = %c" idx chr) vowels
vowel.[0] = a
vowel.[1] = e
vowel.[2] = i
vowel.[3] = o
vowel.[4] = u
val it : unit = ()Multidimensional Arrays
Arrays are helpful for storing data in a linear fashion, but what if you need to represent data as a two-, three-, or higher-dimensional grid? You can create multidimensional arrays, which enable you to treat data as a block indexed by several values.
Multidimensional arrays come in two flavors: rectangular and jagged; the difference is illustrated in Figure 4-2. Rectangular arrays are in a solid block, while jagged arrays are essentially arrays of arrays.
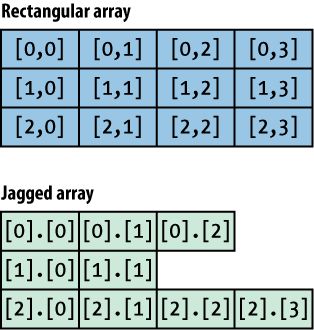
Which type of multidimensional array to use depends on the situation. Using jagged arrays allows you to save memory if each row doesn’t need to be the same length; however, rectangular arrays are more efficient for random access because the elements are stored in a contiguous block of memory. (And therefore can benefit from your processor’s cache.)
Rectangular arrays
Rectangular arrays are rectangular blocks of
n by m elements
in memory. Rectangular arrays are indicated by rectangular brackets
with a comma separating them for each new dimension. Also, just like
single-dimensional arrays, there are the Array2D and Array3D modules for creating and
initializing rectangular arrays:
> // Creating a 3x3 array
let identityMatrix : float[,] = Array2D.zeroCreate 3 3
identityMatrix.[0,0] <- 1.0
identityMatrix.[1,1] <- 1.0
identityMatrix.[2,2] <- 1.0;;
val identityMatrix : float [,] = <1.0; 0.0; 0.0]
[0.0; 1.0; 0.0]
[0.0; 0.0; 1.0>2D rectangular arrays can also take slices, using the same syntax but providing a slice for each dimension:
> // All rows for columns with index 1 through 2
identityMatrix.[*, 1..2];;
val it : float [,] = <0.0; 0.0]
[1.0; 0.0]
[0.0; 1.0>Jagged arrays
Jagged arrays are simply single-dimensional arrays of single-dimensional arrays. Each row in the main array is a different array, each needing to be initialized separately:
> // Create a jagged array
let jaggedArray : int[][] = Array.zeroCreate 3
jaggedArray.[0] <- Array.init 1 (fun x -> x)
jaggedArray.[1] <- Array.init 2 (fun x -> x)
jaggedArray.[2] <- Array.init 3 (fun x -> x);;
val jaggedArray : int [] [] = [|[|0|]; [|0; 1|]; [|0; 1; 2|]|]Mutable Collection Types
Often you will need to store data, but you won’t know how many items you will have ahead of time. For example, you might be loading records from a database. If you use an array, you run the risk of wasting memory by allocating too many elements, or even worse, not enough.
Mutable collection types allow you to dynamically add and remove elements over time. While mutable collection types can be problematic when doing parallel and asynchronous programming, they are very simple to work with.
List<'T>
The List type in the
System.Collections.Generic
namespace—not to be confused with the F# list type—is a wrapper on top of an array that
allows you to dynamically adjust the size of the array when adding and
removing elements. Because List is
built on top of standard arrays, retrieving and adding values is
typically very fast. But once the internal array is filled up a new,
larger one will need to be created and the List’s contents copied over.
Example 4-10 shows basic usage of a
List. Again, we’re denying poor Pluto
the title of planet.
> // Create a List<_> of planetsopen System.Collections.Genericlet planets =new List<string>();; val planets : Collections.Generic.List<string> > // Add individual planets planets.Add("Mercury") planets.Add("Venus") planets.Add("Earth") planets.Add("Mars");; > planets.Count;; val it : int = 4 > // Add a collection of values at once planets.AddRange( [| "Jupiter"; "Saturn"; "Uranus"; "Neptune"; "Pluto" |] );; val it : unit = () > planets.Count;; val it : int = 9 > // Sorry bro planets.Remove("Pluto");; val it : bool = true > planets.Count;; val it : int = 8
Table 4-2 shows common
methods on the List type.
Function and type | Description |
| Adds an element to the end of the list. |
| Removes all elements from the list. |
| Returns whether or not the item can be found in the list. |
| Property for the number of items in the list. |
| Returns a zero-based
index of the given item in the list. If it is not present,
returns |
| Inserts the given item at the specified index into the list. |
| Removes the given item if present from the list. |
| Removes the item at the specified index. |
Dictionary<'K,'V>
The Dictionary type in
the System.Collections.Generic
namespace that contains key-value pairs. Typically, you would use a
dictionary when you want to store data and require a friendly way to
look it up, rather than an index, such as using a name to look up
someone’s phone number.
Example 4-11 shows using a dictionary to
map element symbols to a custom Atom
type. It uses a language feature called units of
measure to annotate the weight of each atom in atomic mass
units. We will cover the units of measure feature in Chapter 7.
// Atomic Mass Units
[<Measure>]
type amu
type Atom = { Name : string; Weight : float<amu> }
open System.Collections.Generic
let periodicTable = new Dictionary<string, Atom>()
periodicTable.Add( "H", { Name = "Hydrogen"; Weight = 1.0079<amu> })
periodicTable.Add("He", { Name = "Helium"; Weight = 4.0026<amu> })
periodicTable.Add("Li", { Name = "Lithium"; Weight = 6.9410<amu> })
periodicTable.Add("Be", { Name = "Beryllium"; Weight = 9.0122<amu> })
periodicTable.Add( "B", { Name = "Boron "; Weight = 10.811<amu> })
// ...
// Lookup an element
let printElement name =
if periodicTable.ContainsKey(name) then
let atom = periodicTable.[name]
printfn
"Atom with symbol with '%s' has weight %A."
atom.Name atom.Weight
else
printfn "Error. No atom with name '%s' found." name
// Alternate syntax to get a value. Return a tuple of 'success * result'
let printElement2 name =
let (found, atom) = periodicTable.TryGetValue(name)
if found then
printfn
"Atom with symbol with '%s' has weight %A."
atom.Name atom.Weight
else
printfn "Error. No atom with name '%s' found." NameTable 4-3 shows common
methods on the Dictionary<'k,'v> type.
Function and type | Description |
| Adds a new key-value pair to the dictionary. |
| Removes all items from the dictionary. |
| Checks if the given key is present in the dictionary. |
| Checks if the given value is present in the dictionary. |
| Returns the number of items in the dictionary. |
| Removes a key-value pair from the dictionary with the given key. |
HashSet<'T>
A HashSet, also defined
in the System.Collections.Generic
namespace, is an efficient collection for storing an unordered set of
items. Let’s say you were writing an application to crawl web pages. You
would need to keep track of which pages you have visited before so you
didn’t get stuck in an infinite loop; however, if you stored the page
URLs you had already visited in a List, it would be very slow to loop through
each element to check whether a page had been visited before. A HashSet stores a collection of unique values
based on their hash code, so checking if an element
exists in the set can be done rather quickly.
Hash codes will be better explained in the next chapter; for now
you can just think of them as a way to uniquely identify an object. They
are the reason why looking up elements in a HashSet and a Dictionary is fast.
Example 4-12 shows using a HashSet to check whether a movie has won the
Oscar for Best Picture.
Open System.Collections.Generic let bestPicture =new HashSet<string>()bestPicture.Add("No Country for Old Men") bestPicture.Add("The Departed") bestPicture.Add("Crash") bestPicture.Add("Million Dollar Baby") // ... // Check if it was a best picture ifbestPicture.Contains("Manos: The Hands of Fate") then printfn "Sweet..." // ...
Table 4-4 shows
common methods on the HashSet<'T> type.
Function and type | Description |
| Adds a new item to the
|
| Removes all items from
the |
| Returns the number of
items in the |
| Modifies the |
| Returns whether the
|
| Returns whether the
|
| Removes the given item
from the |
| Modifies the |
Looping Constructs
F# has the traditional sorts of looping constructs seen in imperative languages. These allow you to repeat the same function or piece of code a set number of times or until a condition is met.
While Loops
while expressions loop
until a Boolean predicate evaluates to false. (For this reason, while loops cannot be used in a purely
functional style, otherwise, the loop would never terminate because you
could never update the predicate.)
Note that the while loop
predicate must evaluate to bool and
the body of the loop must evaluate to unit. The following code shows how to use a
while loop to count up from
zero:
> // While loop let mutable i = 0whilei < 5doi <- i + 1 printfn "i = %d" i;; i = 1 i = 2 i = 3 i = 4 i = 5 val mutable i : int = 5
The predicate for the while loop is checked before the loop starts,
so if the initial value of the predicate is false, the loop will never execute.
For Loops
When you need to iterate a fixed number of times, you can
use a for expression, of which there
are two flavors in F#: simple and enumerable.
Simple for loops
Simple for loops introduce a
new integer value and count up to a fixed value. The loop won’t
iterate if the counter is greater than the maximum value:
> // For loopfori=1to5doprintfn "%d" i;; 1 2 3 4 5 val it : unit = ()
To count down, use the downto keyword. The
loop won’t iterate if the counter is less than the minimum
value:
> // Counting downfori=5downto1doprintfn "%d" i;; 5 4 3 2 1 val it : unit = ()
Numerical for loops are only
supported with integers as the counter, so if you need to loop more
than System.Int32.MaxValue times,
you will need to use enumerable for
loops.
Enumerable for loop
The more common type of for loop is one that iterates through a
sequence of values. Enumerable for
loops work with any seq type, such
as array or list:
> // Enumerable loopforiin[1 .. 5]doprintfn "%d" i;; 1 2 3 4 5 val it : unit = ()
What makes enumerable for loops more powerful than a foreach loop in C# is that enumerable
for loops can take advantage of
pattern matching. The element that follows the for keyword is actually a pattern-match
rule, so if it is a new identifier like i, it simply captures the pattern-match
value. But more complex pattern-match rules can be used
instead.
In Example 4-13, a
discriminated union is introduced with two union cases, Cat and Dog. The for loop iterates through a list but
executes only when the element in the list is an instance of the
Dog union case.
> // Pet type
type Pet =
| Cat of string * int // Name, Lives
| Dog of string // Name
;;
type Pet =
| Cat of string * int
| Dog of string
> let famousPets = [ Dog("Lassie"); Cat("Felix", 9); Dog("Rin Tin Tin") ];;
val famousPets : Pet list = [Dog "Lassie"; Cat ("Felix",9); Dog "Rin Tin Tin"]
> // Print famous dogs
for Dog(name) in famousPets do
printfn "%s was a famous dog." name;;
Lassie was a famous dog.
Rin Tin Tin was a famous dog.
val it : unit = ()There are no break or
continue keywords in F#. If you
want to exit prematurely in the middle of a for loop, you will need to create a mutable
value and convert the for loop to a
while loop.
Exceptions
Every programmer knows things don’t always happen as planned. I’ve been careful in examples so far to avoid showing you code where things fail. But dealing with the unexpected is a crucial aspect of any program, and fortunately the .NET platform supports a powerful mechanism for handling the unexpected.
An exception is a failure in a .NET program that causes an abnormal branch in control flow. If an exception occurs, the function immediately exits, as well as its calling function, and so on until the exception is caught by an exception handler. If the exception is never caught, the program terminates.
The simplest way to report an error in an F# program is to use the
failwith function. This
function takes a string as a parameter, and when called, throws an
instance of System.Exception. An
alternate version calls failwithf that
takes a format string similar to printf
and sprintf:
> // Using failwithf
let divide x y =
if y = 0 then failwithf "Cannot divide %d by zero!" x
x / y;;
val divide : int -> int -> int
> divide 10 0;;
System.Exception: Cannot divide 10 by zero!
at FSI_0003.divide(Int32 x, Int32 y)
at <StartupCode$FSI_0004>.$FSI_0004._main()
stopped due to errorIn the previous example FSI indicated an exception was thrown,
displaying the two most important properties on an exception type: the
exception message and stack trace. Each exception has a Message property, which
is a programmer-friendly description of the problem. The Stacktrace property is a
string printout of all the functions waiting on a return value before the
exception occurred, and is invaluable for tracking down the origin of an
exception. Because the stack unwinds immediately
after an exception is thrown, the exception could be caught far away from
where the exception originated.
While a descriptive message helps programmers debug the exception,
it is a best practice in .NET to use a specific exception type. To throw a
more specific exception, you use the raise function. This
takes a custom exception type (any type derived from System.Exception) and throws the exception just
like failwith:
> // Raising a DivideByZeroException
let divide2 x y =
if y = 0 then raise <| new System.DivideByZeroException()
x / y;;
val divide2 : int -> int -> int
> divide2 10 0;;
System.DivideByZeroException: Attempted to divide by zero.
at FSI_0005.divide2(Int32 x, Int32 y)
at <StartupCode$FSI_0007>.$FSI_0007._main()
stopped due to errorWarning
It is tempting to throw exceptions whenever your program reaches an unexpected state; however, throwing exceptions incurs a significant performance hit. Whenever possible, situations that would throw an exception should be obviated.
Handling Exceptions
To handle an exception you catch it using a try-catch expression.
Any exceptions raised while executing code within a try-catch expression will be handled by a
with block, which is a
pattern match against the exception type.
Because the exception handler to execute is determined by pattern
matching, you can combine exception handlers using Or or use a wildcard
to catch any exception. If an exception is thrown within a try-catch expression and an appropriate
exception handler cannot be found, the exception will continue bubbling
up until caught or the program terminates.
try-catch expressions
return a value, just like a pattern match or if expression. So naturally the last
expression in the try block must have
the same type as each rule in the with pattern match.
Example 4-14 shows some code that
runs through a minefield of potential problems. Each possible exception
will be caught with an appropriate exception handler. In the example,
the :? dynamic type test operator is
used to match against the exception type; this operator will be covered
in more detail in the next chapter.
open System.IO
[<EntryPoint>]
let main (args : string[]) =
let exitCode =
try
let filePath = args.[0]
printfn "Trying to gather information about file:"
printfn "%s" filePath
// Does the drive exist?
let matchingDrive =
Directory.GetLogicalDrives()
|> Array.tryFind (fun drivePath -> drivePath.[0] = filePath.[0])
if matchingDrive = None then
raise <| new DriveNotFoundException(filePath)
// Does the folder exist?
let directory = Path.GetPathRoot(filePath)
if not <| Directory.Exists(directory) then
raise <| new DirectoryNotFoundException(filePath)
// Does the file exist?
if not <| File.Exists(filePath) then
raise <| new FileNotFoundException(filePath)
let fileInfo = new FileInfo(filePath)
printfn "Created = %s" <| fileInfo.CreationTime.ToString()
printfn "Access = %s" <| fileInfo.LastAccessTime.ToString()
printfn "Size = %d" fileInfo.Length
0
with
// Combine patterns using Or
| :? DriveNotFoundException
| :? DirectoryNotFoundException
-> printfn "Unhandled Drive or Directory not found exception"
1
| :? FileNotFoundException as ex
-> printfn "Unhandled FileNotFoundException: %s" ex.Message
3
| :? IOException as ex
-> printfn "Unhandled IOException: %s" ex.Message
4
// Use a wild card match (result will be of type System.Exception)
| _ as ex
-> printfn "Unhandled Exception: %s" ex.Message
5
// Return the exit code
printfn "Exiting with code %d" exitCode
exitCodeBecause not catching an exception might prevent unmanaged
resources from being freed, such as file handles not being closed or
flushing buffers, there is a second way to catch process exceptions:
try-finally
expressions. In a try-finally
expression, the code in the finally
block is executed whether or not an exception is thrown, giving you an
opportunity to do required cleanup work.
Example 4-15 demonstrates a
try-finally expression in
action.
> // Try-finally expressions
let tryFinallyTest() =
try
printfn "Before exception..."
failwith "ERROR!"
printfn "After exception raised..."
finally
printfn "Finally block executing..."
let test() =
try
tryFinallyTest()
with
| ex -> printfn "Exception caught with message: %s" ex.Message;;
val tryFinallyTest : unit -> unit
val test : unit -> unit
> test();;
Before exception...
Finally block executing...
Exception caught with message: ERROR!
val it : unit = ()Reraising Exceptions
Sometimes, despite your best efforts to take corrective action, you just can’t fix the problem. In those situations, you can reraise the exception, which will allow the original exception to continue bubbling up from within an exception handler.
Example 4-16 demonstrates reraising an
exception by using the reraise
function.
Defining Exceptions
Throwing specialized exceptions is key for consumers of your code to only catch the exceptions they know how to handle. Other exceptions will then continue to bubble up until an appropriate exception handler is found.
You can define your own custom exceptions by creating types that inherit from
System.Exception, which you will see in
Chapter 5. However, in F#, there is
an easier way to define exceptions using a lightweight exception syntax.
Declaring exceptions in this way allows you to define them with the same
syntax as discriminated unions.
Example 4-17 shows
creating several new exception types, some of which are associated
with data. The advantage of these lightweight exceptions is that when
they are caught, it is easier to extract the relevant data from them
because you can use the same syntax for pattern matching against
discriminated unions. Also, there is no need for a dynamic type test
operator :?, which we saw in previous
examples.
open System open System.Collections.Genericexception NoMagicWandexception NoFullMoon of int * intexception BadMojo of stringlet castHex (ingredients : HashSet<string>) = try let currentWand = Environment.MagicWand if currentWand = null thenraise NoMagicWandif not <| ingredients.Contains("Toad Wart") thenraise <| BadMojo("Need Toad Wart to cast the hex!")if not <| isFullMoon(DateTime.Today) thenraise <| NoFullMoon(DateTime.Today.Month, DateTime.Today.Day)// Begin the incantation... let mana = ingredients |> Seq.map (fun i -> i.GetHashCode()) |> Seq.fold (+) 0 sprintf "%x" mana with |NoMagicWand-> "Error: A magic wand is required to hex!" |NoFullMoon(month, day)-> "Error: Hexes can only be cast during a full moon." |BadMojo(msg)-> sprintf "Error: Hex failed due to bad mojo [%s]" msg
In Chapter 3, we looked at the functional style of programming, which provides some interesting ways to write code, but doesn’t quite stand on its own. The purely functional style doesn’t integrate well with the existing .NET framework class libraries and sometimes requires complicated solutions for simple problems.
In this chapter, you learned how to update values, which enables you to write new types of programs. Now you can use efficient collections to store program results, loop as necessary, and should any problems occur, throw exceptions.
Now you can make a choice as to how to approach problems, and you can begin to see the value of multiparadigm computing. Some problems can be solved by simply building up a mutable data structure, while others can be built up through combining simple functions to transform immutable data. You have options with F#.
In the next chapter, we will look at object-oriented programming. This third paradigm of F# doesn’t necessarily add much more computational power, but it does provide a way for programmers to organize and abstract code. In much the same way that pure functions can be composed, so can objects.
Get Programming F# now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

