Chapter 1. Why Semantics?
Natural language is amazing. Without any effort you can ask a stranger how to find the nearest coffee shop; you can share your knowledge of music and martini making with your community of friends; you can go to the library, pick up a book, and learn from an author who lived hundreds of years ago. It is hard to imagine a better API for knowledge.
As a simple example, think about the following two sentences. Both are of the form “subject-verb-object,” one of the simplest possible grammatical structures:
Colin enjoys mushrooms.
Mushrooms scare Jamie.
Each of these sentences represents a piece of information. The words “Jamie” and “Colin” refer to specific people, the word “mushroom” refers to a class of organisms, and the words “enjoys” and “scare” tell you the relationship between the person and the organism. Because you know from previous experience what the verbs “enjoy” and “scare” mean, and you’ve probably seen a mushroom before, you’re able to understand the two sentences. And now that you’ve read them, you’re equipped with new knowledge of the world. This is an example of semantics: symbols can refer to things or concepts, and sequences of symbols convey meaning. You can now use the meaning that you derived from the two sentences to answer simple questions such as “Who likes mushrooms?”
Semantics is the process of communicating enough meaning to result in an action. A sequence of symbols can be used to communicate meaning, and this communication can then affect behavior. For example, as you read this page, you are integrating the ideas expressed in these words with all that you already know. If the semantics of our writing in this book is clear, it should help you create new software, solve hard problems, and do great things.
But this book isn’t about natural language; rather, it’s about using semantics to represent, combine, and share knowledge between communities of machines, and how to write systems that act on that knowledge.
If you have ever written a program that used even a single variable, then you have programmed with semantics. As a programmer, you knew that this variable represented a value, and you built your program to respond to changes in the variable. Hopefully you also provided some comments in the code that explained what the variable represented and where it was used so other programmers could understand your code more easily. This relationship between the value of the variable, the meaning of the value, and the action of the program is important, but it’s also implicit in the design of the system.
With a little work you can make the semantic relationships in your data explicit, and program in a way that allows the behavior of your systems to change based on the meaning of the data. With the semantics made explicit, other programs, even those not written by you, can seamlessly use your data. Similarly, when you write programs that understand semantic data, your programs can operate on datasets that you didn’t anticipate when you designed your system.
Data Integration Across the Web
For applications that run on a single machine, documenting the semantics of variables in comments and documentation is adequate. The only people who need to understand the meaning of a variable are the programmers reading the source code. However, when applications participate in larger networks, the meanings of the messages they exchange need to be explicit.
Before the World Wide Web, when a user wanted to use an Internet application, he would install a tool capable of handling specific types of network messages on his machine. If a user wanted to locate users on other networks, he would install an application capable of utilizing the FINGER protocol. If a user wanted to exchange email across a network, he would install an application capable of utilizing the SMTP protocol. Each tool understood the message formats and protocols specific to its task and knew how best to display the information to the user.
Application developers would agree on the format of the messages and the behavior of applications through the circulation of RFC (Request For Comments) documents. These RFCs were written in English and made the semantics of the data contained in the messages explicit, frequently walking the reader through sample data exchanges to eliminate ambiguity. Over time, the developer community would refine the semantics of the messages to improve the capabilities of the applications. RFCs would be amended to reflect the new semantics, and application developers would update applications to make use of the new messages. Eventually users would update the applications on their machines and benefit from these new capabilities.
The emergence of the Web represented a radical change in how most people used the Internet. The Web shielded users from having to think about the applications handling the Internet messages. All you had to do was install a web browser on your machine, and any application on the Web was at your command. For developers, the Web provided a single, simple abstraction for delivering applications and made it possible for an application running in a fixed location and maintained by a stable set of developers to service all Internet users.
Underlying the Web is a set of messages that developers of web infrastructure have agreed to treat in a standard manner. It is well understood that when a web server speaking HTTP receives a GET request, it should send back data corresponding to the path portion of the request message. The semantics of these messages have been thoroughly defined by standards committees and documented in RFCs and W3C recommendations. This standardized infrastructure allows web application developers to operate behind a facade that separates them from the details of how application data is transmitted between machines, and focus on how their applications appear to users. Web application developers no longer need to coordinate with other developers about message formats or how applications should behave in the presence of certain data.
While this facade has facilitated an explosion in applications available to users, the decoupling of data transmission from applications has caused data to become compartmentalized into stovepipe systems, hidden behind web interfaces. The web facade has, in effect, prevented much of the data fueling web applications from being shared and integrated into other Internet applications.
Applications that combine data in new ways and allow users to make connections and understand relationships that were previously hidden are very powerful and compelling. These applications can be as simple as plotting crime statistics on a map or as informative as showing which cuisines are available within walking distance of a film that you want to watch. But currently the process to build these applications is highly specialized and idiosyncratic, with each application using hand-tuned and ad-hoc techniques for harvesting and integrating information due to the hidden nature of data on the Web.
This book introduces repeatable approaches to these data integration problems through the use of simple mechanisms that explicitly expose the semantics of data. These mechanisms provide standardized ways for data to be published and combined, allowing developers to focus on building data-rich applications rather than getting stuck on problems of obtaining and integrating data.
Traditional Data-Modeling Methods
There are many ways to model data, some of them very well researched and mature. In this book we explore new ways to model data, but we’re certainly not trying to convince you that the old ways are wrong. There are many ways to think about data, and it is important to have a wide range of tools available so you can pick the best one for the task at hand.
In this section, we’ll look at common methods that you’ve likely encountered and consider their strengths and weaknesses when it comes to integrating data across the Web and in the face of quickly changing requirements.
Tabular Data
The simplest kind of dataset, and one that almost everyone is familiar with, is tabular data. Tabular data is any data kept in a table, such as an Excel spreadsheet or an HTML table. Tabular data has the advantage of being very simple to read and manipulate. Consider the restaurant data shown in Table 1-1.
| Restaurant | Address | Cuisine | Price | Open |
| Deli Llama | Peachtree Rd | Deli | $ | Mon, Tue, Wed, Thu, Fri |
| Peking Inn | Lake St | Chinese | $$$ | Thu, Fri, Sat |
| Thai Tanic | Branch Dr | Thai | $$ | Tue, Wed, Thu, Fri, Sat, Sun |
| Lord of the Fries | Flower Ave | Fast Food | $$ | Tue, Wed, Thu, Fri, Sat, Sun |
| Marquis de Salade | Main St | French | $$$ | Thu, Fri, Sat |
| Wok This Way | Second St | Chinese | $ | Mon, Tue, Wed, Thu, Fri, Sat, Sun |
| Luna Sea | Autumn Dr | Seafood | $$$ | Tue, Thu, Fri, Sat |
| Pita Pan | Thunder Rd | Middle Eastern | $$ | Mon, Tue, Wed, Thu, Fri, Sat, Sun |
| Award Weiners | Dorfold Mews | Fast Food | $ | Mon, Tue, Wed, Thu, Fri, Sat |
| Lettuce Eat | Rustic Parkway | Deli | $$ | Mon, Tue, Wed, Thu, Fri |
Data kept in a table is generally easy to display, sort, print, and edit. In fact, you might not even think of data in an Excel spreadsheet as “modeled” at all, but the placement of the data in rows and columns gives each piece a particular meaning. Unlike the modeling methods we’ll see later, there’s not really much variation in the ways you might look at tabular data. It’s often said that most “databases” used in business settings are simply spreadsheets.
It’s interesting to note that there are semantics in a data table or spreadsheet: the row and column in which you choose to put the data—for example, a restaurant’s cuisine—explains what the name means to a person reading the data. The fact that Chinese is in the row Peking Inn and in the column Cuisine tells us immediately that “Peking Inn serves Chinese food.” You know this because you understand what restaurants and cuisines are and because you’ve previously learned how to read a table. This may seem like a trivial point, but it’s important to keep in mind as we explore different ways to think about data.
Data stored this way has obvious limitations. Consider the last column, Open. You can see that we’ve crammed a list of days of the week into a single column. This is fine if all we’re planning to do is read the table, but it breaks down if we want to add more information such as the open hours or nightly specials. In theory, it’s possible to add this information in parentheses after the days, as shown in Table 1-2.
| Restaurant | Address | Cuisine | Price | Open |
| Deli Llama | Peachtree Rd | Deli | $ | Mon (11a–4p), Tue (11–4), Wed (11–4), Thu (11–7), Fri (11–8) |
| Peking Inn | Lake St | Chinese | $$$ | Thu (5p–10p), Fri (5–11), Sat (5–11) |
However, we can’t use this data in a spreadsheet program to find the restaurants that will be open late on Friday night. Sorting on the columns simply doesn’t capture the deeper meaning of the text we’ve entered. The program doesn’t understand that we’ve used individual fields in the Open column to store multiple distinct information values.
The problems with spreadsheets are compounded when we have multiple spreadsheets that make reference to the same data. For instance, if we have a spreadsheet of our friends’ reviews of the restaurants listed earlier, there would be no easy way to search across both documents to find restaurants near our homes that our friends recommend. Although Excel experts can often use macros and lookup tables to get the spreadsheet to approximate this desired behavior, the models are rigid, limited, and usually not changeable by other users.
The need for a more sophisticated way to model data becomes obvious very quickly.
Relational Data
It’s almost impossible for a programmer to be unfamiliar with relational databases, which are used in all kinds of applications in every industry. Products like Oracle DB, MySQL, and PostgreSQL are very mature and are the result of years of research and optimization. Relational databases are very fast and powerful tools for storing large sets of data where the data model is well understood and the usage patterns are fairly predictable.
Essentially, a relational database allows multiple tables to be joined in a standardized way. To store our restaurant data, we might define a schema like the one shown in Figure 1-1. This allows our restaurant data to be represented in a more useful and flexible way, as shown in Figure 1-2.
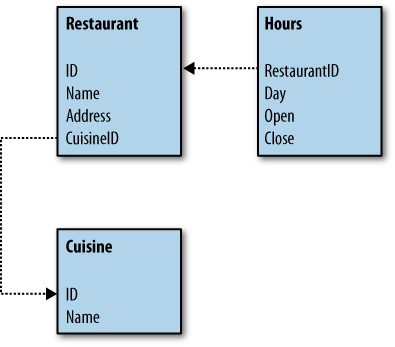
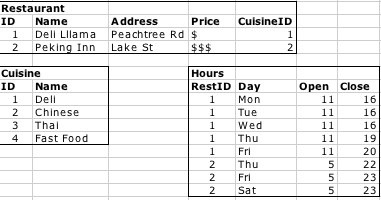
Now, instead of sorting or filtering on a single column, we can do more sophisticated queries. A query to find all the restaurants that will be open at 10 p.m. on a Friday can be expressed using SQL like this:
SELECT Restaurant.Name, Cuisine.Name, Hours.Open, Hours.Close FROM Restaurant, Cuisine, Hours WHERE Restaurant.CuisineID=Cuisine.ID AND Restaurant.ID=Hours.RestaurantID AND Hours.Day="Fri" AND Hours.Open<22 AND Hours.Close>22
which gives a result like this:
Restaurant.Name | Cuisine.Name | Hours.Open | Hours.Close | ---------------------------------------------------------------------------- Peking Inn | Chinese | 17 | 23 |
Notice that in our relational data model, the semantics of the data have been made more explicit. The meanings of the values are actually described by the schema: someone looking at the tables can immediately see that there are several types of entities modeled—a type called “restaurant” and a type called “days”—and that they have specific relationships between them. Furthermore, even though the database doesn’t really know what a “restaurant” is, it can respond to requests to see all the restaurants with given properties. Each datum is labeled with what it means by virtue of the table and column that it’s in.
Evolving and Refactoring Schemas
The previous section mentioned that relational databases are great for datasets where the data model is understood up front and there is some understanding of how the data will be used. Many applications, such as product catalogs or contact lists, lend themselves well to relational schemas, since there are generally a fixed set of fields and a set of fairly typical usage patterns.
However, as we’ve been discussing, data integration across the Web is characterized by rapidly changing types of data, and programmers can never quite know what will be available and how people might want to use it. As a simple example, let’s assume we have our restaurant database up and running, and then we receive a new database of bars with additional information not in our restaurant schema, as shown in Table 1-3.
| Bar | Address | DJ | Specialty drink |
| The Bitter End | 14th Ave | No | Beer |
| Peking Inn | Lake St | No | Scorpion Bowl |
| Hammer Time | Wildcat Dr | Yes | Hennessey |
| Marquis de Salade | Main St | Yes | Martini |
Of course, many restaurants also have bars, and as it gets later in the evening, they may stop serving food entirely and only serve drinks. The table of bars in this case shows that, in addition to being a French restaurant, Marquis de Salade is also a bar with a DJ. The table also shows specialty drinks, which gives us additional information about Marquis. As of right now, these databases are separate, but it’s certainly possible that someone might want to query across them—for example, to find a place to get a French meal and stay later for martinis.
So how do we update our database so that it supports the new bar data? Well, we could just link the tables with another table, which has the upside of not forcing us to change the existing structure. Figure 1-3 shows a database structure with an additional table, RB_Link, that links the existing tables, telling you when a restaurant and a bar are actually the same place.
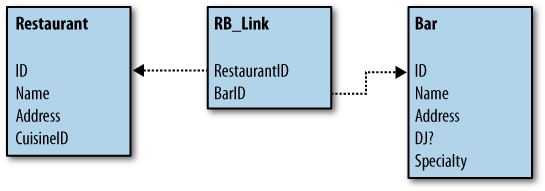
This works, and certainly makes our query possible, but it introduces a problem: there are now two names and addresses in our database for establishments that are both bars and restaurants, and just a link telling us that they’re the same place. If you want to query by address, you need to look at both tables. Also, the type of food served is attached to the restaurant type, but not to its bar type. Adding and updating data is much more complicated.
Perhaps a more accurate way to model this would be to have a Venue table with bar and restaurant types separated out, like the one shown in Figure 1-4.
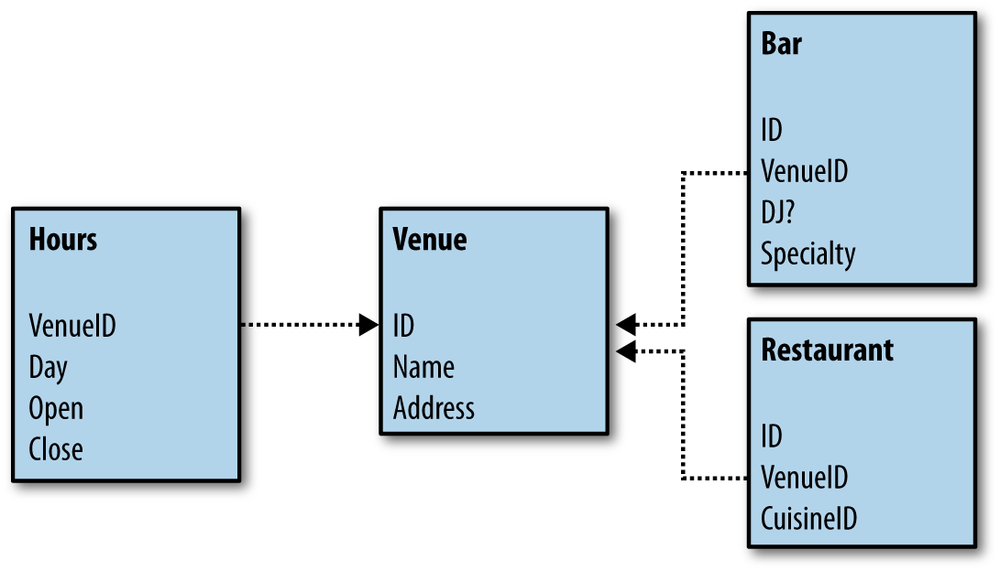
This seems to solve our issues, but remember that all the existing data is still in our old data model and needs to be transformed to the new data model. This process is called schema migration and is often a huge headache. Not only does the data have to be migrated, but all the queries and dependent code that was written assuming a certain table structure have to be changed as well. If we have built a restaurant website on top of our old schema, then we need to figure out how to update all of our existing code, queries, and the database without imposing significant downtime on the website. A whole discipline of software engineering has emerged to deal with these issues, using techniques like stored database procedures and object-relational mapping (ORM) layers to try to decouple the underlying schema from the business-logic layer and lowering the cost of schema changes. These techniques are useful, but they impose their own complexities and problems as well.
It’s easy to imagine that, as our restaurant application matures, these venues could also have all kinds of other uses such as a live music hall or a rental space for events. When dealing with data integration across the entire Web, or even in smaller environments that are constantly facing new datasets, migrating the schema each time a new type of data is encountered is simply not tractable. Too often, people have to resort to manual lookups, overly convoluted linked spreadsheets, or just setting the data aside until they can decide what to do with it.
Very Complicated Schemas
In addition to having to migrate as the data evolves, another problem one runs into with relational databases is that the schemas can get incredibly complicated when dealing with many different kinds of data. For example, Figure 1-5 shows a small section of the schema for a Customer Relationship Management (CRM) product.
A CRM system is used to store information about customer leads and relationships with current customers. This is obviously a big application, but to put things in perspective, it is a very small piece of what is required to run a business. An ERP (Enterprise Resource Planning) application, such as SAP, can cover many more of the data needs of a large business. However, the schemas for ERP applications are so inaccessible that there is a whole industry of consulting companies that exclusively deal with them.
The complexity is barely manageable in well-understood industry domains like CRM and ERP, but it becomes even worse in rapidly evolving fields such as biotechnology and international development. Instead of a few long lists of well-characterized data, we instead have hundreds or thousands of datasets, all of which talk about very different things. Trying to normalize these to a single schema is a labor-intensive and painful process.

Getting It Right the First Time
This brings us to the question of whether it’s possible to define a schema so that it’s flexible enough to handle a wide variety of ever-changing types of data, while still maintaining a certain level of readability. Maybe the schema could be designed to be open to new venue purposes and offer custom fields for them, something like Figure 1-6. The schema has lost the concepts of bars and restaurants entirely, now containing just a list of venues and custom properties for them.
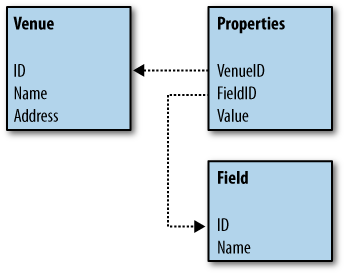
This is not usually recommended, as it gets rid of a lot of the normalization that was possible before and will likely degrade the performance of the database. However, it allows us to express the data in a way that allows for new venue purposes to come along, an example of which is shown in Figure 1-7. Notice how the Properties table contains all the custom information for each of the venues.
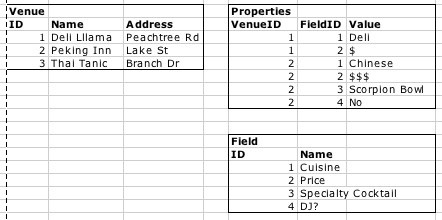
This means that the application can be extended to include, for example, concert venues. Maybe we’re visiting a city and looking for a place to stay close to cheap food and cool concert venues. We could create new fields in the Field table, and then add custom properties to any of the existing venues. Figure 1-8 shows an example where we’ve added the information that Thai Tanic has live jazz music. There are two extra fields, “Live Music?” and “Music Genre”, and two more rows in the Properties table.
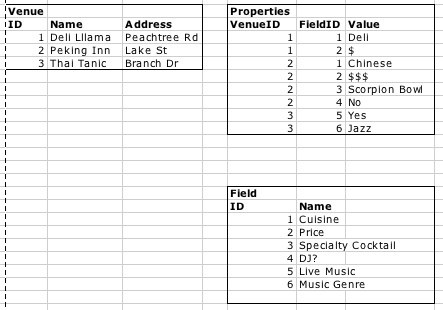
This type of key/value schema extension is nothing new, and many people stumble into this kind of representation when they have sparse relationships to represent. In fact, many “customizable” data applications such as Saleforce.com represent data this way internally. However, because this type of representation turns the database tables “on their sides,” database performance frequently suffers, and therefore it is generally not considered a good idea (i.e., best practice). We’ve also lost a lot of the normalization we were able to do before, because we’ve flattened everything to key/value pairs.
Semantic Relationships
Even though it might not be considered a best practice, let’s continue with this progression and see what happens. Why not move all the relationships expressed in standard table rows into this parameterized key/value format? From this perspective, the venue name and address are just properties of the venue, so let’s move the columns in the Venue table into key/value rows in the Properties table. Figure 1-9 shows what this might look like.
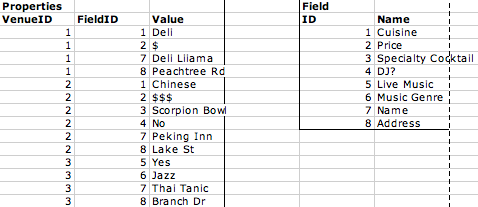
That’s interesting, but the relationship between the Properties table and the Field table is still only known through the knowledge trapped in the logic of our join query. Let’s make that knowledge explicit by preforming the join and displaying the result set in the same parameterized way (Table 1-4).
| Properties | ||
| VenueID | Field | Value |
| 1 | Cuisine | Deli |
| 1 | Price | $ |
| 1 | Name | Deli Llama |
| 1 | Address | Peachtree Rd |
| 2 | Cuisine | Chinese |
| 2 | Price | $$$ |
| 2 | Specialty Cocktail | Scorpion Bowl |
| 2 | DJ? | No |
| 2 | Name | Peking Inn |
| 2 | Address | Lake St |
| 3 | Live Music? | Yes |
| 3 | Music Genre | Jazz |
| 3 | Name | Thai Tanic |
| 3 | Address | Branch Dr |
Now each datum is described alongside the property that defines it. In doing this, we’ve taken the semantic relationships that previously were inferred from the table and column and made them data in the table. This is the essence of semantic data modeling: flexible schemas where the relationships are described by the data itself. In the remainder of this book, you’ll see how you can move all of the semantics into the data. We’ll show you how to represent data in this manner, and we’ll introduce tools especially designed for storing, visualizing, and querying semantic data.
Metadata Is Data
One of the challenges of using someone else’s relational data is understanding how the various tables relate to one another. This information—the data about the data representation—is often called metadata and represents knowledge about how the data can be used. This knowledge is generally represented explicitly in the data definition through foreign key relationships, or implicitly in the logic of the queries. Too frequently, data is archived, published, or shared without this critical metadata. While rediscovering these relationships can be an exciting exercise for the user, schemas need not become very large before metadata recovery becomes nearly impossible.
In our earlier example, parameterizing the venue data made the model extremely flexible. When we learn of a new characteristic for a venue, we simply need to add a new row to the table, even if we’ve never seen that characteristic before. Parameterizing the data also made it trivial to use. You need very little knowledge about the organization of the data to make use of it. Once you know that rows sharing identical VenueIDs relate to one another, you can learn everything there is to know about a venue by selecting all rows with the same VenueID. From this perspective, we can think of the parameterized venue data as “self-describing data.” The metadata of the relational schema, describing which columns go together to describe a single entity, has become part of the data itself.
Building for the Unexpected
By packing the data and metadata together in a single representation, we have not only made the schema future-proof, we have also isolated our applications from “knowing” too much about the form of the data. The only thing our application needs to know about the data is that a venue will have an ID in the first column, the properties of the venue appear in the second column, and the third column represents the value of each property. When we add a totally new property to a venue, the application can either choose to ignore the property or handle it in a standard manner.
Because our data is represented in a flexible model, it is easy for someone else to integrate information about espresso machine locations, allowing our application to cover not only restaurants and bars, but also coffee shops, book stores, and gas stations (at least in the greater Seattle area). A well-designed application should be able to seamlessly integrate new semantic data, and semantic datasets should be able to work with a wide variety of applications.
Many content and image creation tools now support XMP (Extensible Metadata Platform) data for tracking information about the author and licensing of creative content. The XMP standard, developed by Adobe Systems, provides a standard set of schemas and allows users to extend the data model in exactly the way we extended the venue data. By using a self-describing model, the tools used to inspect content for XMP data need not change, even if the types of content change significantly in the future. Since image creation tools are fundamentally for creative expression, it is essential that users not be limited to a fixed set of descriptive fields.
“Perpetual Beta”
It’s clear that the Web changed the economics of application development. The web facade greatly reduced coordination costs by cutting applications free from the complexity of managing low-level network data messages. With a single application capable of servicing all the users on the Internet, the software development deadlines imposed by manufacturing lead time and channel distribution are quaint memories for most of us. Applications are now free to improve on a continuous and independent basis. Development cycles that update application code on a monthly, weekly, or even daily basis are no longer considered unusual. The phrase “perpetual beta” reflects this sentiment that software is never “frozen” on the Web. As applications continually improve, continuous release processes allow users to instantaneously benefit.
Compressed release cycles are a part of staying competitive at large portal sites. For example, Yahoo! has a wide variety of media sites covering topics such as health, kids, travel, and movies. Content is continually changing as news breaks, editorial processes complete, and users annotate information. In an effort to reduce the time necessary to produce specialized websites and enable new types of personalization and search, Yahoo! has begun to add semantic metadata to their content using extensible schemas not unlike the examples developed here. As data and metadata become one, new applications can add their own annotations without modification to the underlying schema. This freedom to extend the existing metadata enables constantly evolving features without affecting legacy applications, and it allows one application to benefit from the information provided by another.
This shift to continually improving and evolving applications has been accompanied by a greater interest in what were previously considered “scripting” languages such as Python, Perl, and Ruby. The ease of getting something up and running with minimal upfront design and the ease of quick iterations to add new features gives these languages an advantage over heavier static languages that were designed for more traditional approaches to software engineering. However, most frameworks that use these languages still rely on relational databases for storage, and thus still require upfront data modeling and commitment to a schema that may not support the new data sources that future application features require.
So, while perpetual beta is a great benefits to users, rapid development cycles can be a challenge for data management. As new application features evolve, data schemas are frequently forced to evolve as well. As we will see throughout the remainder of this book, flexible semantic data structures and the application patterns that work with them are well designed for life in a world of perpetual beta.
Get Programming the Semantic Web now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

