If you drive from the airport in San Jose, California, down Interstate 180 South, chances are you’ll spot a sign for a seedy strip joint called the Pink Poodle. The story of Microsoft’s cloud computing platform starts in 2006 with an eclectic set of people and this most unlikely of locations. Before I tell that story, we’ll examine what cloud computing actually is, where it came from, and why it matters to you.
Imagine if tap water didn’t exist. Every household would need to dig a well. Doing so would be a pain. Wells are expensive to build, and expensive to maintain. You wouldn’t be able get a large quantity of water quickly if you needed it—at least not without upgrading your pump. And if you no longer needed the well, there would be no store to return it to, and no way to recoup your capital investment. If you vacated the house, or the proper plumbing were installed in your house, you would have invested in a well you don’t need.
Tap water fixes all of that. Someone else spends the money and builds the right plumbing and infrastructure. They manage it, and ensure that the water is clean and always available. You pay only for what you use. You can always get more if you want it.
That, in a nutshell, is what cloud computing is all about. It is data center resources delivered like tap water. It is always on, and you pay only for what you use.
This chapter takes a detailed look at the concepts behind cloud computing, and shows you how Windows Azure utilizes cloud computing.
Microsoft describes Windows Azure as an “operating system for the cloud.” But what exactly is the “cloud” and, more importantly, what exactly is cloud computing?
At its core, cloud computing is the realization of the long-held dream of utility computing. The “cloud” is a metaphor for the Internet, derived from a common representation in computer network drawings showing the Internet as a cloud. Utility computing is a concept that entails having access to computing resources, and paying for the use of those resources on a metered basis, similar to paying for common utilities such as water, electricity, and telephone service.
Before diving into particulars, let’s first take a look at where cloud computing came from. The history of cloud computing includes utilization of the concept in a variety of environments, including the following:
Time-sharing systems
Mainframe computing systems
Transactional computing systems
Grid computing systems
Cloud computing has its origins in the 1960s. Time-sharing systems were the first to offer a shared resource to the programmer. Before time-sharing systems, programmers typed in code using punch cards or tape, and submitted the cards or tape to a machine that executed jobs synchronously, one after another. This was massively inefficient, since the computer was subjected to a lot of idle time.
Bob Bemer, an IBM computer scientist, proposed the idea of time sharing as part of an article in Automatic Control Magazine. Time sharing took advantage of the time the processor spent waiting for I/O, and allocated these slices of time to other users. Since multiple users were dealt with at the same time, these systems were required to maintain the state of each user and each program, and to switch between them quickly. Though today’s machines accomplish this effortlessly, it took some time before computers had the speed and size in core memory to support this new approach.
The first real project to implement a time-sharing system was begun by John McCarthy on an IBM 704 mainframe. The system that this led to, the Compatible Time Sharing System (CTSS), had the rudimentary elements of several technologies that today are taken for granted: text formatting, interuser messaging, as well as a rudimentary shell and scripting ability.
Note
John McCarthy later became famous as the father of LISP and modern artificial intelligence. CTSS led to Multics, which inspired Unix.
Tymshare was an innovative company in this space. Started in 1964, Tymshare sold computer time and software packages to users. It had two SDS/XDS 940 mainframes that could be accessed via dial-up connections. In the late 1960s, Tymshare started using remote sites with minicomputers (known as nodes) running its own software called the Supervisor. In this, Tymshare created the ancestor of modern networked systems.
Note
The product created by Tymshare, Tymnet, still exists today. After a series of takeovers and mergers, Tymshare is now owned by Verizon.
These efforts marked the beginning of the central idea of cloud computing: sharing a single computing resource that is intelligently allocated among users.
At its peak, there were dozens of vendors (including IBM and General Electric). Organizations opened time-sharing accounts to get access to computing resources on a pay-per-usage model, and for overflow situations when they didn’t have enough internal capacity to meet demand. These vendors competed in uptime, price, and the platform they ran on. They started offering applications and database management systems (DBMSs) on a pay-for-play model, as well. They eventually went out of fashion with the rise of the personal computer.
Though nearly outdated today, mainframe computing innovated several of the ideas you see in cloud computing. These large, monolithic systems were characterized by high computation speed, redundancy built into their internal systems, and generally delivering high reliability and availability. Mainframe systems were also early innovators of a technology that has resurged over the past few years: virtualization.
IBM dominates the mainframe market. One of its most famous model series was the IBM System/360 (S/360). This project, infamous for its appearance in the book The Mythical Man Month: Essays on Software Engineering by Fred Brooks (Addison-Wesley), also brought virtualization to the mainstream.
The CP/CMS operating system on the S/360 could create multiple independent virtual machines. This was possible because of hardware assistance from the S/260, which had two modes of instructions: the normal problem state and a special supervisor state. The supervisor state instructions would cause a hardware exception that the operating system could then handle. Its fundamental principles were similar to modern-day hardware assistance such as AMD-V (Pacifica) and Intel VT-X (Vanderpool).
Mainframe usage dwindled because several of the technologies once found only on mainframes started showing up on increasingly smaller computers. Mainframe computing and cloud computing are similar in the idea that you have a centralized resource (in the case of cloud computing, a data center) that is too expensive for most companies to buy and maintain, but is affordable to lease or rent resources from. Data centers represent investments that only a few companies can make, and smaller companies rent resources from the companies that can afford them.
Transactional systems are the underpinning of most modern services. The technology behind transactional systems is instrumental in modern cloud services. Transactional systems allow processing to be split into individual, indivisible operations called transactions. Each transaction is atomic—it either succeeds as a whole or fails as a whole. Transactions are a fundamental part of every modern database system.
The history of transactional processing systems has been intertwined with that of database systems. The 1960s, 1970s, and 1980s were a hotbed for database system research. By the late 1960s, database systems were coming into the mainstream. The COBOL committee formed a task group to define a standard database language. Relational theory was formalized in the 1970s starting with E.F. Codd’s seminal paper, and this led to SQL being standardized in the 1980s. In 1983, Oracle launched version 3 of its nascent database product, the first version of its database system to support a rudimentary form of transactions.
While database systems were emerging, several significant innovations were happening in the transaction processing space. One of the first few systems with transaction processing capabilities was IBM’s Information Management System (IMS).
Note
IMS has a fascinating history. After President John F. Kennedy’s push for a mission to the moon, North America Rockwell won the bid to launch the first spacecraft to the moon. The company needed an automated system to manage large bills of materials for the construction, and contracted with IBM for this system in 1966. IBM put together a small team, and legendary IBM engineer Vern Watts joined the effort. The system that IBM designed was eventually renamed IMS.
IMS was a joint hierarchical database and information management system with transaction processing capabilities. It had several of the features now taken for granted in modern systems: Atomicity, Consistency, Isolation, Durability (ACID) support; device independence; and so on. Somewhat surprisingly, IMS has stayed strong over the ages, and is still in widespread use.
IBM also contributed another important project to transaction processing: System R. System R was the first SQL implementation that provided good transaction processing performance. System R performed breakthrough work in several important areas: query optimization, locking systems, transaction isolation, storing the system catalog in a relational form inside the database itself, and so on.
Tandem Computers was an early manufacturer of transaction processing systems. Tandem systems used redundant processors and designs to provide failover. Tandem’s flagship product, the NonStop series of systems, was marketed for its high uptime.
Note
Tandem was also famous for its informal culture and for nurturing several employees who would go on to become famous in their own right. The most famous of these was Jim Gray, who, among several other achievements, literally wrote the book on transaction processing.
Tandem’s systems ran a custom operating system called Guardian. This operating system was the first to incorporate several techniques that are present in most modern distributed systems. The machine consisted of several processors, many of which executed in lock-step, and communicated over high-speed data buses (which also had redundancy built in). Process pairs were used to failover operations if execution on one processor halted for any reason. After a series of takeovers, Tandem is now a part of Hewlett-Packard. Tandem’s NonStop line of products is still used, with support for modern technologies such as Java.
The fundamental design behind these systems—that is, fault tolerance, failover, two-phase commit, resource managers, Paxos (a fault-tolerance protocol for distributed systems), redundancy, the lessons culled from trying to implement distributed transactions—forms the bedrock of modern cloud computing systems, and has shaped their design to a large extent.
The term grid computing originated in the 1990s, and referred to making computers accessible in a manner similar to a power grid. This sounds a lot like cloud computing, and reflects the overlap between the two, with some companies even using the terms interchangeably. One of the better definitions of the difference between the two has been offered by Rick Wolski of the Eucalyptus project. He notes that grid computing is about users making few, but very large, requests. Only a few of these allocations can be serviced at any given time, and others must be queued. Cloud computing, on the other hand, is about lots of small allocation requests, with allocations happening in real time.
Note
If you want to read more about Wolski’s distinction between grid computing and cloud computing, see http://blog.rightscale.com/2008/07/07/cloud-computing-vs-grid-computing/.
The most famous grid computing project is SETI@home. At SETI, employees search for extraterrestrial intelligence. The SETI@home project splits data collected from telescopes into small chunks that are then downloaded into volunteer machines. The software installed on these machines scans through the radio telescope data looking for telltale signs of alien life. The project has logged some astonishing numbers—more than 5 million participants and more than 2 million years of aggregate computing time logged.
Several frameworks and products have evolved around grid computing. The Globus toolkit is an open source toolkit for grid computing built by the Globus Alliance. It allows you to build a computing grid based on commodity hardware, and then submit jobs to be processed on the grid. It has several pluggable job schedulers, both open source and proprietary. Globus is used extensively by the scientific community. CERN will be using Globus to process data from tests of the Large Hadron Collider in Geneva.
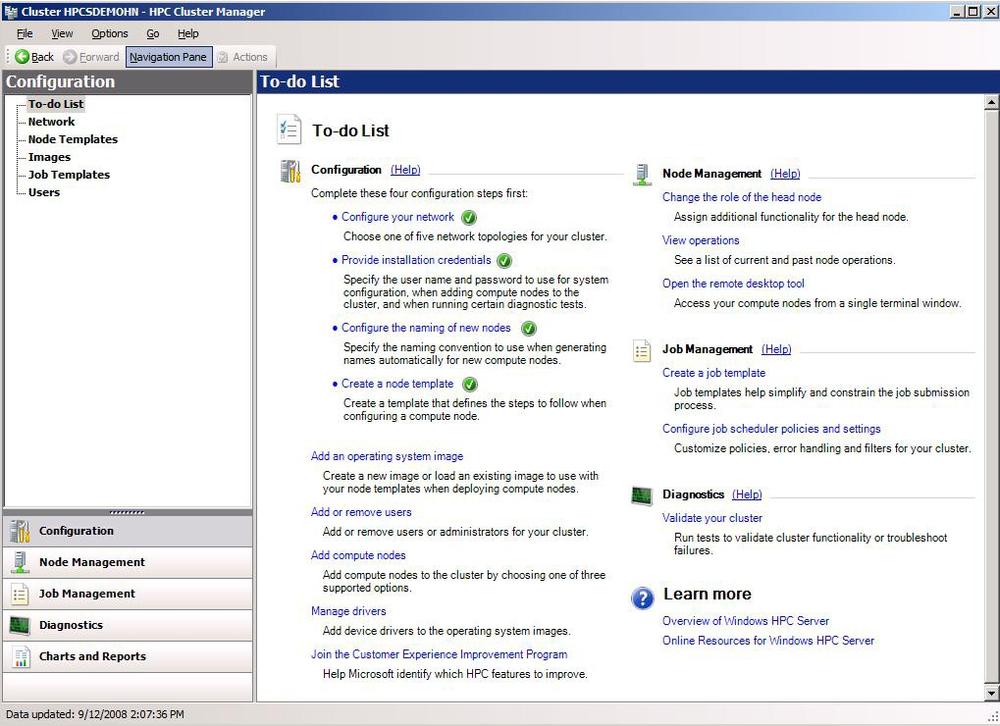
Microsoft jumped into this space with the launch of Windows High Performance Computing (HPC) Server in September 2008. Windows HPC Server provides a cluster environment, management and monitoring tools, and a job scheduler, among several other features. Figure 1-1 shows the Windows HPC management interface. Most importantly, it integrates with Windows Deployment Services, and it can deploy operating system images to set up the cluster. Later in this chapter, you’ll learn about how the Windows Azure fabric controller works, and you’ll see similar elements in its design.
The cloud allows you to run workloads similar to a grid. When you have data that must be processed you spin up the required number of machines, split the data across the machines in any number of ways, and aggregate the results together. Throughout this book, you’ll see several technologies that have roots in modern grid and distributed computing.
A modern cloud computing platform (of which, as you will see later in this chapter, Windows Azure is one) typically incorporates the following characteristics:
- The illusion of infinite resources
Cloud computing platforms provide the illusion of infinite computing and storage resources. (Note that this description includes the word illusion because there will always be some limits, albeit large, that you must keep in mind.) As a user, you are not required to do the kind of capacity planning and provisioning that may be necessary to deploy your own individual storage and computing infrastructure. You can depend on the companies you are dealing with to own several large data centers spread around the world, and you can tap into those resources on an as-needed basis.
- Scale on demand
All cloud platforms allow you to add resources on demand, rather than going through a lengthy sales-and-provisioning process. Instead of having to wait weeks for someone to deliver new servers to your data center, you typically must wait only minutes to get new resources assigned. This is a really good thing in terms of the cost and time required to provision resources, but it also means your application must be designed to scale along with the underlying hardware provided by your cloud computing supplier.
- Pay-for-play
Cloud computing platforms typically don’t require any upfront investment, reservation, or major setup fees. You pay only for the software and hardware you use. This, along with the scaling capacity of cloud platforms, means you won’t incur huge capital expenditure (capex) costs upfront. All cloud platforms let you move away from capex spending and into operating expenditure (opex) spending. In layman’s terms, this converts a fixed cost for estimated usage upfront to a variable cost where you pay only for what you use.
- High availability and an SLA
If you choose to depend on someone else to run your business, you must be assured that you won’t be subjected to frequent outages. Most cloud providers have a Service Level Agreement (SLA) that guarantees a level of uptime, and includes a refund mechanism if the SLA isn’t met. Windows Azure provides an SLA for both its storage and its hosting pieces.
- Geographically distributed data centers
When serving customers around the globe, it is critical to have data centers in multiple geographic locations. Reasons for this requirement include legal/regulatory concerns, geopolitical considerations, load balancing, network latency, edge caching, and so on.
In short, cloud computing is like water or electricity. It is always on when you need it, and you pay only for what you use.
Note
In reality, cloud computing providers today have some way to go before they meet the “several 9s” (99.99% and beyond uptime) availability provided by utility companies (gas, water, electricity) or telecom companies.
Cloud computing platforms can be differentiated by the kind of services they offer. You might hear these referred to as one of the following:
- Infrastructure-as-a-Service (IaaS)
This refers to services that provide lower levels of the stack. They typically provide basic hardware as a service—things such as virtual machines, load-balancer settings, and network attached storage. Amazon Web Services (AWS) and GoGrid fall into this category
- Platform-as-a-service (PaaS)
Providers such as Windows Azure and Google App Engine (GAE) provide a platform that users write to. In this case, the term platform refers to something that abstracts away the lower levels of the stack. This application runs in a specialized environment. This environment is sometimes restricted—running as a low-privilege process, with restrictions on writing to the local disk and so on. Platform providers also provide abstractions around services (such as email, distributed caches, structured storage), and provide bindings for various languages. In the case of GAE, users write code in a subset of Python, which executes inside a custom hosting environment in Google’s data centers.
Note
In Windows Azure, you typically write applications in .NET, but you can also call native code, write code using other languages and runtimes such as Python/PHP/Ruby/Java, and, in general, run most code that can run on Windows.
- Software-as-a-Service (SaaS)
The canonical example of this model is Salesforce.com. Here, specific provided applications can be accessed from anywhere. Instead of hosting applications such as Customer Relationship Management (CRM), Enterprise Resource Planning (ERP), and Human Resources (HR) on-site, companies can outsource these applications. These are higher-level services that we won’t address in much detail this book.
In reality, cloud services overlap these categories, and it is difficult to pin any one of them down into a single category.
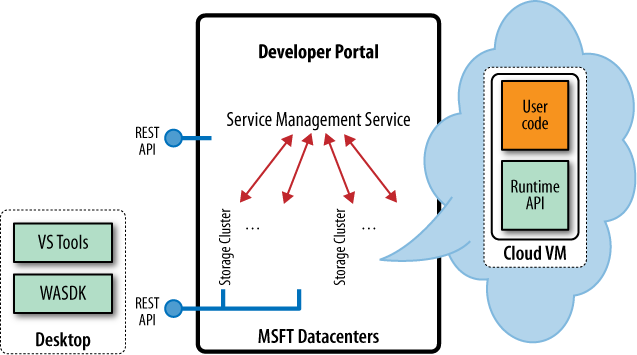
The Windows Azure Platform stack consists of a few distinct pieces, one of which (Windows Azure) is examined in detail throughout this book. However, before beginning to examine Windows Azure, you should know what the other pieces do, and how they fit in.
The Windows Azure Platform is a group of cloud technologies to be used by applications running in Microsoft’s data centers, on-premises and on various devices. The first question people have when seeing its architecture is “Do I need to run my application on Windows Azure to take advantage of the services on top?” The answer is “no.” You can access Azure AppFabric services and SQL Azure, as well as the other pieces from your own data center or the box under your desk, if you choose to.
This is not represented by a typical technology stack diagram—the pieces on the top don’t necessarily run on the pieces on the bottom, and you’ll find that the technology powering these pieces is quite different. For example, the authentication mechanism used in SQL Azure is different from the one used in Windows Azure. A diagram showing the Windows Azure platform merely shows Microsoft’s vision in the cloud space. Some of these products are nascent, and you’ll see them converge over time.
Now, let’s take a look at some of the major pieces.
Azure AppFabric services provide typical infrastructure services required by both on-premises and cloud applications. These services act at a higher level of the “stack” than Windows Azure (which you’ll learn about shortly). Most of these services can be accessed through a public HTTP REST API, and hence can be used by applications running on Windows Azure, as well as your applications running outside Microsoft’s data centers. However, because of networking latencies, accessing these services from Windows Azure might be faster because they are often hosted in the same data centers. Since this is a distinct piece from the rest of the Windows Azure platform, we will not cover it in this book.
Following are the components of the Windows Azure AppFabric platform:
- Service Bus
Hooking up services that live in different networks is tricky. There are several issues to work through: firewalls, network hardware, and so on. The Service Bus component of Windows Azure AppFabric is meant to deal with this problem. It allows applications to expose Windows Communication Foundation (WCF) endpoints that can be accessed from “outside” (that is, from another application not running inside the same location). Applications can expose service endpoints as public HTTP URLs that can be accessed from anywhere. The platform takes care of such challenges as network address translation, reliably getting data across, and so on.
- Access Control
This service lets you use federated authentication for your service based on a claims-based, RESTful model. It also integrates with Active Directory Federation Services, letting you integrate with enterprise/on-premises applications.
In essence, SQL Azure is SQL Server hosted in the cloud. It provides relational database features, but does it on a platform that is scalable, highly available, and load-balanced. Most importantly, unlike SQL Server, it is provided on a pay-as-you-go model, so there are no capital fees upfront (such as for hardware and licensing).
As you’ll see shortly, there are several similarities between SQL Azure and the table services provided by Windows Azure. They both are scalable, reliable services hosted in Microsoft data centers. They both support a pay-for-usage model. The fundamental differences come down to what each system was designed to do.
Windows Azure tables were designed to provide low-cost, highly scalable storage. They don’t have any relational database features—you won’t find foreign keys or joins or even SQL. SQL Azure, on the other hand, was designed to provide these features. We will examine these differences in more detail later in this book in the discussions about storage.
Windows Azure is Microsoft’s platform for running applications in the cloud. You get on-demand computing and storage to host, scale, and manage web applications through Microsoft data centers. Unlike other versions of Windows, Windows Azure doesn’t run on any one machine—it is distributed across thousands of machines. There will never be a DVD of Windows Azure that you can pop in and install on your machine.
Before looking at the individual features and components that make up Windows Azure, let’s examine how Microsoft got to this point, and some of the thinking behind the product.
The seeds for Windows Azure were sown in a 2005 memo from Ray Ozzie, Microsoft’s then-new Chief Software Architect, who had just taken over from Bill Gates. In that memo, Ozzie described the transformation of software from the kind you installed on your system via a CD to the kind you accessed through a web browser. It was a call to action for Microsoft to embrace the services world. Among other things, Ozzie called for a services platform. Several teams at Microsoft had been running successful services, but these lessons hadn’t been transformed into actual bits that internal teams or external customers could use.
Note
If you want to read the Ozzie memo, you can find it at http://www.scripting.com/disruption/ozzie/TheInternetServicesDisruptio.htm.
In 2006, Amitabh Srivastava, a long-time veteran at Microsoft, was in charge of fixing the engineering processes in Windows. As Windows Vista drew close to launch, Srivastava met Ozzie and agreed to lead a new project to explore a services platform. Srivastava quickly convinced some key people to join him. Arguably, the most important of these was Dave Cutler, the father of Windows NT and Virtual Memory System (VMS). Cutler is a legendary figure in computing, and a near-mythical figure at Microsoft, known for his coding and design skills as well as his fearsome personality. Convincing Cutler to come out of semiretirement to join the new team was a jolt in the arm.
During this period, the nascent team made several trips to all of Microsoft’s major online services to see how they ran things, and to get a feel for what problems they faced. It was during one such trip to California to see Hotmail that Cutler suggested (in jest) that they name their new project “Pink Poodle” after a strip joint they spotted on the drive from the San Jose airport. A variant of this name, “Red Dog,” was suggested by another team member, and was quickly adopted as the codename for the project they were working on.
After looking at several internal and external teams, they found similar problems across them all. They found that everyone was spending a lot of time managing the machines/virtual machines they owned, and that these machines were inefficiently utilized in the first place. They found that there was little sharing of resources, and that there was no shared platform or standard toolset that worked for everyone. They also found several good tools, code, and ideas that they could reuse.
The growing team started building out the various components that made up Red Dog: a new hypervisor (software that manages and runs virtual machines), a “fabric” controller (a distributed system to manage machines and applications), a distributed storage system, and, like every other Microsoft platform, compelling developer tools. They realized that they were exploring solutions that would solve problems for everyone outside Microsoft, as well as inside, and switched to shaping this into a product that Microsoft’s customers could use. Working in a startup-like fashion, they did things that weren’t normally done at Microsoft, and broke some rules along the way (such as turning a nearby building into a small data center, and stealing power from the buildings around it).
Note
You can read more about this adventure at http://www.wired.com/techbiz/people/magazine/16-12/ff_ozzie?currentPage=1.
Red Dog, now renamed Windows Azure, was officially unveiled along with the rest of the Azure stack during the Professional Developers Conference in Los Angeles on October 27, 2008.
As shown in Figure 1-2, when you use Windows Azure you get the following key features:
- Service hosting
You can build services that are then hosted by Windows Azure. Services here refers to any generic server-side application—be it a website, a computation service to crunch massive amounts of data, or any generic server-side application. Note that, in the current release of Windows Azure, there are limits to what kind of code is allowed and not allowed. For example, code that requires administrative privileges on the machine is not allowed.
- Service management
In a traditional environment, you must deal with diverse operational tasks—everything from dealing with application updates, to monitoring the application, to replacing failed hardware. In a traditional environment, there are a variety of tools to help you do this. In the Microsoft ecosystem outside of Azure, you might use the capabilities built into Windows Server and products such as Systems Center. In the non-Microsoft world, you might be using tools such as Capistrano for deployment and projects such as Ganglia for monitoring. Windows Azure’s fabric controller brings this “in-house” and deals with this automatically for you. It monitors your services, deals with hardware and software failures, and handles operating system and application upgrades seamlessly.
- Storage
Windows Azure provides scalable storage in which you can store data. Three key services are provided: binary large object (blob) storage (for storing raw data), semistructured tables, and a queue service. All services have an HTTP API on top of them that you can use to access the services from any language, and from outside Microsoft’s data centers as well. The data stored in these services is also replicated multiple times to protect from internal hardware or software failure. Storage (like computation) is based on a consumption model where you pay only for what you use.
- Windows Server
If you’re wondering whether your code is going to look different because it is running in the cloud, or whether you’re going to have to learn a new framework, the answer is “no.” You’ll still be writing code that runs on Windows Server. The .NET Framework (3.5 SP1, as of this writing) is installed by default on all machines, and your typical ASP.NET code will work. If you choose to, you can use FastCGI support to run any framework that supports FastCGI (such as PHP, Ruby on Rails, Python, and so on). If you have existing native code or binaries, you can run that as well.
- Development tools
Like every major Microsoft platform, Windows Azure has a bunch of tools to make developing on it easier. Windows Azure has an API that you can use for logging and error reporting, as well as mechanisms to read and update service configuration files. There’s also an SDK that enables you to deploy your applications to a cloud simulator, as well as Visual Studio extensions.
At the bottom of the Windows Azure stack, you’ll find a lot of machines in Microsoft data centers. These are state-of-the-art data centers with efficient power usage, beefy bandwidth, and cooling systems. Even the most efficient facilities still possess a lot of room for overhead and waste when it comes to utilization of resources. Since the biggest source of data center cost is power, this is typically measured in performance/watts/dollars. What causes that number to go up?
Note
As of this writing, Windows Azure is hosted in six locations spread across the United States, Europe, and Asia.
If you run services on the “bare metal” (directly on a physical machine), you soon run into a number of challenges as far as utilization is concerned. If a service is using a machine and is experiencing low traffic while another service is experiencing high traffic, there is no easy way to move hardware from one service to the other. This is a big reason you see services from large organizations experience outages under heavy traffic, even though they have excess capacity in other areas in their data centers—they don’t have a mechanism to shift workloads easily. The other big challenge with running on the bare metal is that you are limited to running one service per box. You cannot host multiple services, since it is difficult to offer guarantees for resources and security.
As an answer to these problems, the industry has been shifting to a virtualized model. In essence, hardware virtualization lets you partition a single physical machine into many virtual machines. If you use VMware Fusion, Parallels Desktop, Sun’s VirtualBox, or Microsoft Virtual PC, you’re already using virtualization, albeit the desktop flavor. The hypervisor is a piece of software that runs in the lower parts of the system and lets the host hardware be shared by multiple guest operating systems. As far as the guest operating systems and the software running on them are concerned, there is no discernible difference. There are several popular server virtualization products on the market, including VMware’s product, Xen (which Amazon uses in its cloud services), and Microsoft’s Windows Hyper-V.
Windows Azure has its own hypervisor built from scratch and optimized for cloud services. In practice this means that, since Microsoft controls the specific hardware in its data centers, this hypervisor can make use of specific hardware enhancements that a generic hypervisor targeted at a wide range of hardware (and a heterogeneous environment) cannot. This hypervisor is efficient, has a small footprint, and is tightly integrated with the kernel of the operating system running on top of it. This leads to performance close to what you’d see from running on the bare metal.
Note
In case you are wondering whether you can use this hypervisor in your data center, you’ll be happy to hear that several innovations from this will be incorporated into future editions of Hyper-V.
Each hypervisor manages several virtual operating systems. All of these run a Windows Server 2008–compatible operating system. In reality, you won’t see any difference between running on normal Windows Server 2008 and these machines—the only differences are some optimizations for the specific hypervisor they’re running on. This Windows Server 2008 image has the .NET Framework (3.5 SP1, as of this writing) installed on it.
Running on a hypervisor provides Windows Azure with a lot of freedom. For example, no lengthy operating system installation is required. To run your application, Windows Azure can just copy over an image of the operating system, a Virtual Hard Disk (VHD) containing your application-specific binaries. You simply boot the machine from the image using a new boot-from-VHD feature. If you have, say, a new operating system patch, no problem. Windows Azure just patches the image, copies it to the target machine, and boots. Voilà! You have a patched machine in a matter of minutes, if not seconds.
You can write applications just as you did before, and in almost all cases, you can simply ignore the fact that you’re not running on native hardware.
Imagine that you’re describing your service architecture to a colleague. You probably walk up to the whiteboard and draw some boxes to refer to your individual machines, and sketch in some arrows. In the real world, you spend a lot of time implementing this diagram. You first set up some machines on which you install your bits. You deploy the various pieces of software to the right machines. You set up various networking settings: firewalls, virtual LANs, load balancers, and so on. You also set up monitoring systems to be alerted when a node goes down.
In a nutshell, Azure’s fabric controller (see Figure 1-3) automates all of this for you. Azure’s fabric controller is a piece of highly available, distributed software that runs across all of Windows Azure’s nodes, and monitors the state of every node. You tell it what you want by specifying your service model (effectively, a declarative version of the whiteboard diagram used to describe your architecture to a colleague), and the fabric controller automates the details. It finds the right hardware, sets up your bits, and applies the right network settings. It also monitors your application and the hardware so that, in case of a crash, your application can be restarted on either the same node or a different node.
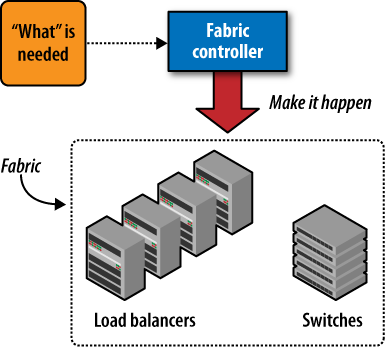
In short, the fabric controller performs the following key tasks:
- Hardware management
The fabric controller manages the low-level hardware in the data center. It provisions and monitors, and takes corrective actions when things go wrong. The hardware it manages ranges from nodes to TOR/L2 switches, load balancers, routers, and other network elements. When the fabric controller detects a problem, it tries to perform corrective actions. If that isn’t possible, it takes the hardware out of the pool and gets a human operator to investigate it.
- Service modeling
The fabric controller maps declarative service specifications (the written down, logical version of the whiteboard diagrams mentioned at the beginning of this section) and maps them to physical hardware. This is the key task performed by the fabric controller. If you grok this, you grok the fabric controller. The service model outlines the topology of the service, and specifies the various roles and how they’re connected, right down to the last precise granular detail. The fabric controller can then maintain this model. For example, if you specify that you have three frontend nodes talking to a backend node through a specific port, the fabric controller can ensure that the topology always holds up. In case of a failure, it deploys the right binaries on a new node, and brings the service model back to its correct state. Later in this book, you’ll learn in detail how the fabric controller works, and how your application can take advantage of this.
- Operating system management
The fabric controller takes care of patching the operating systems that run on these nodes, and does so in a manner that lets your service stay up.
- Service life cycle
The fabric controller also automates various parts of the service life cycle—things such as updates and configuration changes. You can partition your application into sections (update domains and fault domains), and the fabric controller updates only one domain at a time, ensuring that your service stays up. If you’re pushing new configuration changes, it brings down one section of your machines and updates them, then moves on to the next set, and so on, ensuring that your service stays up throughout.
If you think of Windows Azure as being similar to an operating system, the storage services are analogous to its filesystem. Normal storage solutions don’t always work very well in a highly scalable, scale-out (rather than scale-up) cloud environment. This is what pushed Google to develop systems such as BigTable and Google File System, and Amazon to develop Dynamo and to later offer S3 and SimpleDb.
Windows Azure offers three key data services: blobs, tables, and queues. All of these services are highly scalable, distributed, and reliable. In each case, multiple copies of the data are made, and several processes are in place to ensure that you don’t lose your data.
All of the services detailed here are available over HTTP through a simple REST API, and can be accessed from outside Microsoft’s data centers as well. Like everything else in Azure, you pay only for what you use and what you store.
Note
Unlike some other distributed storage systems, none of Windows Azure’s storage services are eventually consistent. This means that when you do a write, it is instantly visible to all subsequent readers. Eventually, consistency is typically used to boost performance, but is more difficult to code against than consistent APIs (since you cannot rely on reading what you just wrote). Azure’s storage services allow for optimistic concurrency support to give you increased performance if you don’t care about having the exact right data (for example, logs, analytics, and so on).
The blob storage service provides a simple interface for storing named files along with metadata. Files can be up to 1 TB in size, and there is almost no limit to the number you can store or the total storage available to you. You can also chop uploads into smaller sections, which makes uploading large files much easier.
Here is some sample Python code to give you a taste of how you’d access a blob using the API. This uses the unofficial library from http://github.com/sriramk/winazurestorage/. (We will explore the official .NET client in detail later in this book.)
blobs = BlobStorage(HOST,ACCOUNT,SECRET_KEY)
blobs.create_container("testcontainer", False)
blobs.put_blob("testcontainer","test","Hello World!" )The queue service provides reliable storage and delivery of messages for your application. You’ll typically use it to hook up the various components of your application, and not have to build your own messaging system. You can send an unlimited number of messages, and you are guaranteed reliable delivery. You can also control the lifetime of the message. You can decide exactly when you’re finished processing the message and remove it from the queue. Since this service is available over the public HTTP API, you can use it for applications running on your own premises as well.
The table storage service is arguably the most interesting of all the storage services. Almost every application needs some form of structured storage. Traditionally, this is through a relational database management system (RDBMS) such as Oracle, SQL Server, MySQL, and the like. Google was the first company to build a large, distributed, structured storage system that focused on scale-out, low cost, and high performance: BigTable. In doing this, Google was also willing to give up some relational capabilities—SQL support, foreign keys, joins, and everything that goes with it—and denormalize its data. Systems such as Facebook’s Cassandra and Amazon’s SimpleDb follow the same principles.
The Windows Azure table storage service provides the same kind
of capability. You can create massively scalable tables (billions of
rows, and it scales along with traffic). The data in these tables is
replicated to ensure that no data is lost in the case of hardware
failure. Data is stored in the form of entities,
each of which has a set of properties. This is
similar to (but not the same as) a database table and column. You
control how the data is partitioned using PartitionKeys and RowKeys. By partitioning across as many
machines as possible, you help query performance.
You may be wondering what language you use to query this service. If you’re in the .NET world, you can write Language Integrated Query (LINQ) code, and your code will look similar to LINQ queries you’d write against other data stores. If you’re coding in Python or Ruby or some other non-.NET environment, you have an HTTP API where you can encode simple queries. If you’re familiar with ADO.NET Data Services (previously called Astoria), you’ll be happy to hear that this is just a normal ADO.NET Data Service API.
If you’re intimidated by all this, don’t be. Moving to a new storage system can be daunting, and you’ll find that there are several tools and familiar APIs to help you along the way. You also have the option to use familiar SQL Server support if you are willing to forego some of the features you get with the table storage service.
You may be surprised to see a section talking about the pitfalls of cloud computing in this chapter. To be sure, some problems exist with all cloud computing platforms today, and Windows Azure is no exception. This section helps you carefully determine whether you can live with these problems. More often than not, you can. If you find that cloud computing isn’t your cup of tea, there is nothing wrong with that; traditional hosting isn’t going away anytime soon.
Note that the following discussion applies to every cloud computing platform in existence today, and is by no means unique to Windows Azure.
Outages happen. As a user, you expect a service to always be running. But the truth is that the current state of cloud providers (or any sort of hosting providers, for that matter) doesn’t give the level of availability offered by a power utility or a telecom company. Can you live with outages? That depends on several factors, including some possible mitigation strategies:
Do you know how frequently your existing infrastructure has outages? In most cases, this is probably a much higher number than what you’ll see with cloud computing providers.
You can use multiple cloud computing providers as a backup strategy in case of an outage.
You can host core business functions on-premises and use the cloud for excess capacity. Or you can run a small on-premises infrastructure and fall back to that in case of an outage.
Outages aren’t caused only by software issues. DDoS attacks are another critical problem, and attacks from large botnets are still difficult to defend against, regardless of what kind of provider you’re hosted on.
Several users have custom hardware needs. Some users may need high-end GPUs for heavy graphics processing, while others need high-speed interconnects for high-performance computing and aren’t satisfied with gigabit Ethernet. High-end storage area networks (SANs) and special RAID configurations are popular requests. Cloud computing thrives on homogeneous data center environments running mostly commodity hardware. It is this aspect that drives the cost of these services down. In such an environment, it is difficult to have custom hardware. Having said that, it is only a matter of time before providers of cloud computing start rolling out some specialized hardware to satisfy the more common requests.
This is probably the biggest showstopper with cloud computing adoption today. With on-premises hardware, you have complete control over your hardware and processes—where the data center is located, who touches the hardware, what security processes are in place, and so on. With cloud computing, you must outsource these critical steps to a third party, and that can be hard to swallow for the following reasons:
You might need data in a specific physical location for legal and regulatory reasons. For example, several firms cannot store data for European customers outside Europe. Other firms cannot take data outside the United States. Some don’t want their data in specific countries for legal reasons, with China and the United States leading the list. With cloud computing, you must carefully inspect where your provider hosts the data centers.
There are several standards with which you may need to comply. The Health Insurance Portability and Accountability Act (HIPAA), the Sarbanes-Oxley Act (SOX), and Payment Card Industry (PCI) Data Security Standards are some of the popular ones. Most cloud computing providers are not compliant. Some are in the process of being audited, while some standards may never be supported. You must examine your cloud computing provider’s policy. With some standards, it may be possible to comply by encrypting data before placing it in the cloud. Health services use this approach today on Amazon S3 and Windows Azure storage to maintain compliance.
You must ensure that you’re following security best practices when inside the cloud—setting the right network settings, using Secure Sockets Layer (SSL) whenever possible, and so on. For the storage services, you must keep the keys safe, and regenerate them periodically.
At the end of the day, the cloud is not inherently less secure than your own infrastructure. It mostly comes down to a trust issue: do you trust the provider to maintain your business-critical data in a responsible manner?
The idea that you don’t have to do capacity planning in the cloud is a myth. You still must plan for usage, or you might wind up getting stuck with a huge bill. For example, when hit by a Slashdot effect, you may not want to scale your application beyond a particular point, and you may be willing to live with a degraded experience. Unfortunately, optimizing your applications to cost less on the cloud is a topic that is not well understood, primarily because of the nascent nature of this space—the years of understanding that have gone into planning traditional systems just haven’t been experienced with cloud computing.
With cloud computing, the decision to use up more capacity need not rest with the chief investment officer. It could rest with the developer, or someone quite low in the food chain. This raises a lot of unanswered questions regarding how companies should plan for usage.
Though there are no good answers today, one good book on the best practices in this space is The Art of Capacity Planning by John Allspaw from Flickr (O’Reilly).
All cloud computing providers have SLA-backed guarantees on the performance you can get. However, there are no good benchmarks or measurement tools today. You might find that your performance is what was promised most of the time, but once in a while, you might see some variance. Since you’re running on a shared infrastructure, this is unavoidable. The customer hosted on the switch next to yours might experience a sudden burst in traffic and have a knock-on effect. On the other hand, this is what you’ll experience in most collocation sites, too.
Note
A favorite anecdote in this regard is of a critical business service that was collocated in the same data center as a component from World of Warcraft (WoW). Whenever WoW did a major update, the data center’s bandwidth got swamped, and the business service started seeing outages. Now, that’s a problem that’s hard to plan for (and explain to your customers)!
There are two kinds of migrations that you should care about. One is from traditional on-premises systems to the cloud, and the other is from one cloud provider to another.
For migrating on-premises systems to the cloud, you’ll often find yourself needing to rewrite/modify parts of your application. Though platforms such as Windows Azure try to make it as seamless as possible to port applications, there are some inherent differences, and you’ll need to make at least some small changes.
Migrating from one cloud provider to another is much more complicated. There is a lack of standards, even de facto ones, in this space. Most APIs are incompatible, and you’ll have to hand-roll some custom scripts/code to migrate. In some cases, migration may not be possible at all.
All of this raises questions about lock-in. You must examine how you can get to your data. In the case of Windows Azure, you can always get to your data over HTTP and publicly documented protocols. If you decide to stop using Windows Azure one day, you can pull your data out of the system and put it elsewhere. The same goes for code.
Since these are early days for cloud computing, the tools and thinking around interoperability are early, too. Several efforts related to interoperability standards are spinning up to tackle this problem.
Very few technologies can claim to be the “Next Big Thing” because their advantages are so obvious. Cloud computing can legitimately claim to be one of them. However, the basic principles and technology behind the cloud have existed for decades. Like Yogi Berra said, “It is like déjà vu all over again.”
This chapter provided a lot of text with very little code. In Chapter 3, you’ll get to crank open the editor and do some coding!
Get Programming Windows Azure now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

