November 2010
Intermediate to advanced
624 pages
18h 14m
English
C is a purely procedural compiled language. All functionality is encapsulated into functions, and C programs are structured such that they are collections of functions grouped into files (roughly the equivalent of Python’s modules). Each file may also include some global variables and various preprocessor directives. In a C source file global variables can be designated as static, which effectively hides them from functions outside of the current file.
A C source code file is compiled into an object file, which in turn is linked with other object files (either part of the immediate program or perhaps system library object files) to produce a final executable object. I should point out that the terms “object file,” “library object,” and “executable object” have nothing to do with object-oriented programming. These are historical terms from the days of mainframes and refrigerator-size minicomputers.
In the procedural paradigm a program’s functions are the primary focus and are distinct from the data they operate on, whereas in object-oriented programming the data and the methods unique to that data are encapsulated into an object. Figure 4-1 attempts to illustrate this graphically.
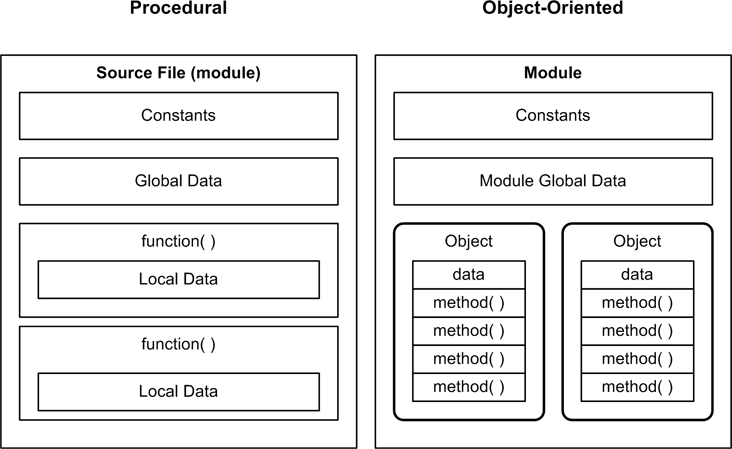
Figure 4-1. Procedural versus OO functional organization
Unlike Python programs, C programs are compiled directly into a binary form (machine language) that is executed by the CPU. There ...
Read now
Unlock full access






