Chapter 1. Web Service Evolution
What are web services? While this might seem a simple question, this book demonstrates that the query has many answers. Much of this is because the typical conversation about web services suffers from the blending of several distinct concepts. Most software developers focus on the technical underpinnings that make communication possible (such as SOAP and XML-RPC). Others add to the web services category developer infrastructure, such as WSDL, the Web Services Description Language. Some even include a wide host of other pieces, including a mind-numbing array of standards (some real, some theoretical).
Because of this confusion, we must define what is meant by the term web services. Here’s a good start:
Web Services: A vague term that refers to distributed or virtual applications or processes that use the Internet to link activities or software components. A travel Web site that takes a reservation from a customer, and then sends a message to a hotel application, accessed via the Web, to determine if a room is available, books it, and tells the customer he or she has a reservation is an example of a Web Services application.
| -Business Process Trends |
| http://www.bptrends.com/resources_glossary. |
| cfm?letterFilter=W&displayMode=all |
This is a great start, but it still needs to be clarified a bit.
This book doesn’t engage in an intellectual debate as to the “correctness”
of web services on a theological level. Instead, it focuses on the
practical, real world usage of web services. For this book’s purposes, web
services are the latest evolution in distributed computing, allowing for
structured communication via Internet protocols. As you’ll see, this
includes everything from sending HTTP GET commands to retrieving an XML document
through the use of SOAP and various vendor SDKs.
Client/Server Origins
Most developers are familiar with the basic concept of client/server computing: a central server handles requests from one or more clients. It’s the foundation of the Web as described by HTTP and HTML: a web server sends pages to a browser client.
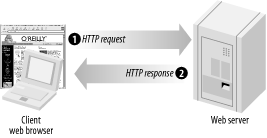
As shown in Figure 1-1, you can see that the client browser initiates the request, which is then processed and responded to by the web server.
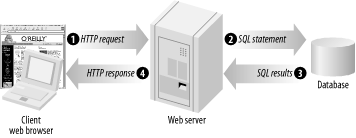
Before the Web really took off, the term client/server was used to describe something slightly different—a central database server that was accessed by custom clients (often written in Visual Basic, C, Pascal, or other languages). Nobody really wanted to run around, constantly installing and reinstalling these custom clients every time there was a bug to be fixed, so people quickly started hooking up smarter, more sophisticated web servers to databases. In order to distinguish these smarter web servers from “dumb” web servers (that served mainly static files), the term application server become popular (in some circles, you’ll hear the term web container used as well, usually when the server does a lot more than just handle web data).
As you can see in Figure 1-2, the notion of a client and a server becomes more complex in these systems, often called three-tier systems . The browser is clearly acting as a client of the application server, but the application server is a client of the database. In effect, the application server is acting both as a client of the database and a server for the client browser.
Consider the system shown in Figure 1-3: note the number of connections, and the number of different roles (client and server) being played by the different systems. These more complex systems are referred to as n-tier systems , because they can have any number of tiers.
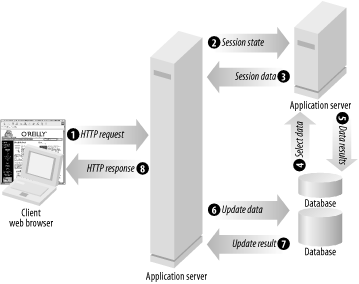
As a mental exercise, consider the following:
How do you debug this system?
Each network connection implies a certain latency and bandwidth overhead. How many connections are appropriate? What happens to the rest of the system if one machine “starves” another by using all its bandwidth or available connections?
How are these connections secured?
What happens if one or more systems crash or otherwise become unavailable?
How do you roll out new applications?
These are tricky problems. When you’re working with web services, you’ll want to keep these potential pitfalls in mind.
The Undefined Web
The concept of a browser talking to a web server is perhaps the most popular client/server system devised (email is the other major one). It didn’t take very long before the popularity of this model lead to some interesting questions about the proper relationship between the client and the server.
Scraping Data
A couple of web sites, desperate for content, realized that they could scrape the HTML of other sites and display some or all of that information in a different format. For example, let’s say that you ran a small web site devoted to the glories of Davis, CA. As shown in Figure 1-4, you set up a site that grabs the weather report from another site (steps 2 and 3) and then grabs the stock quote for the public corporation that runs the local gas station (steps 4 and 5). The user can visit your site and get your information as well as the data from the other two sites as well; throw a banner ad at the top of the page, and you’ll soon be rich!
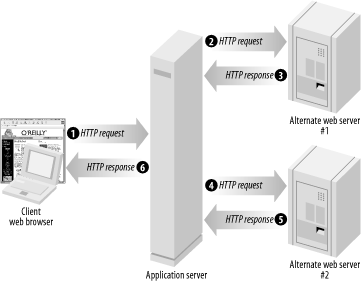
The problem with scraping (dubious ethics aside) is that HTML is extremely fragile. The only promise given with HTML is that a browser can render properly formatted HTML in a human-readable format, and even that’s a bit of a reach sometimes. A very minor formatting change can break your HTML parser, and the operator of the site doesn’t care (or is actively trying to foil your attempts to steal content).
Now, let’s take this to the next logical step. Let’s say the weather and stock guys notice that you’re reading their data, and both call you and generously offer to trade you legitimate access to their data in exchange for links back to their site. You agree, and now you need to set this up. The immediate question becomes: what standards and specifications do you use to tie all this information together?
This is perhaps one of the most contentious and controversial aspects of web services. How do you decide the actual implementation details for how these systems are going to talk to each other?
Fragile Interdependence
One of the most significant problems when trying to figure out how to get two systems to talk to each other is sorting out what dependencies, assumptions, and standards to use. For example, we assume that we will be using TCP/IP and the other core technologies of the Internet, but we may not (for example) be comfortable assuming that our partners are willing to standardize on Java or .NET technologies. Instead of declaring required technologies by fiat, our first instinct is to wait and see what standards get locked down.
Preferably, the standards we choose have several solid implementations and have been in use for some time. This allows us to understand more of the pros and cons of any particular technology. HTML, for example, has been in use for some time, but different web browsers can have wildly different interpretations of a given HTML document. Many of the same problems you see with HTML can be seen with web services; for example, consider the seemingly simple questions of style and perspective reflected in the differences between the HTML pages shown in Examples Example 1-1 and Example 1-2 (both display the same text on screen).
<HTML>
<HEAD>
</HEAD>
<BODY>
<P ALIGN="CENTER"><B>This is my text!</B></P>
</BODY>
</HTML>Example 1-1 shows a very human-readable (yet not particularly elegant or sophisticated) version of an HTML page. Example 1-2 shows a page without any extraneous formatting or whitespace, with proper markers and the (admittedly gratuitous) use of CSS.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd"><html><head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
<style type="text/css"><!-- P { font-style: normal; font-weight: bold;
text-align: center; } --></style></head>
<body><p>This is my text! </p></body></html>Sometimes differences are merely a matter of style and not substance. For example, consider the differences in method naming standards between Java and Microsoft C/C++. Java developers typically prefer relatively verbose naming, with a strong object-as-noun, method-as-verb nomenclature, heavily influenced by the patterns put forth by the JavaBeans specification that you’ll find at:
| http://java.sun.com/docs/codeconv/html/CodeConvTOC.doc.html |
Microsoft developers are more likely to use Hungarian notation, which as even Microsoft notes, “make the variable names look a bit as though they’re written in some non-English language”; see the following for more information:
| http://msdn.microsoft.com/library/en-us/dnvsgen/html/HungaNotat.asp |
However,.NET is phasing this out; see the following:
| http://msdn.microsoft.com/library/default.asp?url=/library/en-us/cpgenref/html/cpconNaming-Guidelines.asp |
While style issues are relevant when you talk about web services—as you’ll see, a perfectly usable set of web service interfaces provided by a vendor can still feel very awkward if the interfaces are based on another style and mental model—the important thing is that services can still be accessed in a reliable, predictable manner. The goal when using web services is to get away from wildly undefined and fragile processes (such as scraping HTML) and instead move toward refined, manageable systems.
Planning for Interdependence
The pundits, purveyors, and snake oil salesmen of web services describe a world in which nearly every process is handled seamlessly by a variety of different web service technologies and options. Automated agents, interconnected by wired and wireless technologies, will use web services to solve global economic crises, find you the best deal on toasters, and restock your refrigerator with fresh milk before you’ve even noticed that the expiration date has passed.
This deeply interconnected world assumes that the underlying web services work very well. In particular, such broad-reaching automation leads to basic questions about responsibilities. For example, let’s say that an error leads to your refrigerator ordering 500 gallons of milk—or none at all. Where did the problem occur? This issue affects you both as a user and provider of web services.
To manage questions of reliability, you must determine what sort of uptime you provide (or demand) for your web services. How do you characterize the performance and security restrictions? What are the implications of a service failure?
It can be helpful to build a brief worksheet when working with web services that can be used as a check list. It can include:
Number of web service methods exposed or used
Frequency of access allowed (e.g., one method call per second at most for methods
a( ),b( ),c( ), and one call of methodd( )per minute)Expected performance of specific methods
Time expected to restore service (e.g., if there is a failure, how long until it’s fixed?)
Bandwidth and latency expectations
Scheduled downtime
Data management and backup responsibility
Logging
Security auditing
Here are some questions to ask yourself:
What are your internal plans for migration if the service fails?
What is the involvement of your legal representation in drafting or agreeing to your service agreement?
What tools or systems will you use to monitor your services? (If you promise to deliver or receive a given level of service, how will you really know?)
What is the expected level of tech support access? How are users expected to contact support? How long until a response is sent?
How will minor bug fixes and upgrades be handled? Will users of the web services be able to test their application against a test server before the changes are pushed to the production system?
How often will new functionality be added? What is the procedure for migrating web service users to new systems?
How long will session data be preserved? (In other words, if I begin a transaction, how long does the remote system maintain that state data before expiring it?)
What are the remedies (refunds or credits) if service fails?
Notice that there is no mention of the programming language used, the application server, the database, the server hardware—all critical to the internal development conversation, but (in theory, at least) not part of the overall web services conversation between two different organizations.
Because of the complexities of interdependence, when you’re working with web services, you need at least a basic understanding of the underlying networking principles, which are discussed in the next chapter.
Get Real World Web Services now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

