Chapter 4. CRUD Web Services
IN THE PRECEDING CHAPTER, we saw how GET and POST
can be used to tunnel information to remote services through URIs and how
POST can be used to transfer XML
documents between services. However, as more interesting distributed
system scenarios emerge, we rapidly reach the limit of what we can
accomplish with those verbs. We need to expand our vocabulary in order to
support more advanced interactions.
In this chapter, weâll introduce two new HTTP verbs to our
repertoire: PUT and DELETE. Alongside GET and POST,
they form the set of verbs required to fully support the Create, Read,
Update, Delete (CRUD) pattern for manipulating resources across the
network.
Note
From here onward, we consider the network and HTTP as an integral part of our distributed application, not just as a means of transporting bytes over the wire.
Through CRUD, weâll take our first steps along the path to enlightenment using HTTP as an application protocol instead of a transport protocol, and see how the Web is really a big framework for building distributed systems.
Modeling Orders As Resources
In Restbucks, orders are core business entities, and as such, their life cycles are of real interest to us from a CRUD perspective. For the ordering parts of the Restbucks business process, we want to create, read, update, and delete order resources like so:
Orders are created when a customer makes a purchase.
Orders are frequently read, particularly when their preparation status is inquired.
Under certain conditions, it may be possible for orders to be updated (e.g., in cases where customers change their minds or add specialties to their drinks).
Finally, if an order is still pending, a customer may be allowed to cancel it (or delete it).
Within the ordering service, these actions (which collectively constitute a protocol) move orders through specific life-cycle phases, as shown in Figure 4-1.
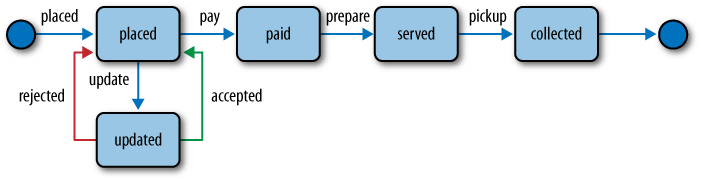
Each operation on an order can be mapped onto one of the HTTP
verbs. For example, we use POST for
creating a new order, GET for
retrieving its details, PUT for
updating it, and DELETE for, well,
deleting it. When mixed with appropriate status codes and some
commonsense patterns, HTTP can provide a good platform for CRUD domains,
resulting in really simple architectures, as shown in Figure 4-2.
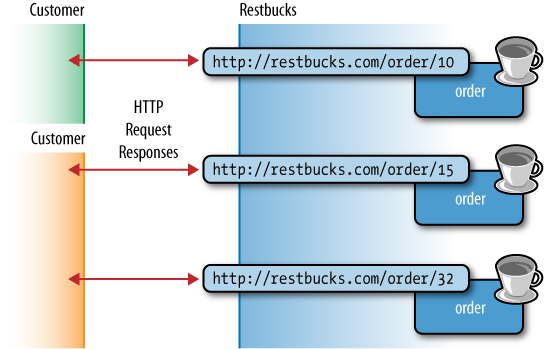
While Figure 4-2 exemplifies a very simple architectural style, it actually marks a significant rite of passage toward embracing the Webâs architecture. In particular, it highlights the use of URIs to identify and address orders at Restbucks, and in turn it supports HTTP-based interactions between the customers and their orders.
Since CRUD services embrace both HTTP and URIs, they are considered to be at level two in Richardsonâs maturity model. Figure 4-3 shows how CRUD services embrace URIs to identify resources such as coffee orders and HTTP to govern the interactions with those resources.
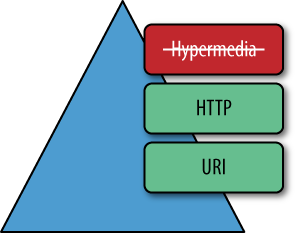
Level two is a significant milestone in our understanding. Many successful distributed systems have been built using level two services. For example, Amazonâs S3 product is a classic level two service that has enabled the delivery of many successful systems built to consume its functionality over the Web. And like the consumers of Amazon S3, weâd like to build systems around level two services too!
Building CRUD Services
When youâre building a service, it helps to think in terms of the behaviors that the service will implement. In turn, this leads us to think in terms of the contract that the service will expose to its consumers. Unlike other distributed system approaches, the contract that CRUD services such as Restbucks exposes to customers is straightforward, as it involves only a single concrete URI, a single URI template, and four HTTP verbs. In fact, itâs so compact that we can provide an overview in just a few lines, as shown in Table 4-1.
The contract in Table 4-1 provides an understanding of the overall life cycle of an order. Using that contract, we can design a protocol to allow consumers to create, read, update, and delete orders. Better still, we can implement it in code and host it as a service.
Note
What constitutes a good format for your resource representations may vary depending on your problem domain. For Restbucks, weâve chosen XML, though the Web is able to work with any reasonable format, such as JSON or YAML.
Creating a Resource with POST
We first saw HTTP POST in
Chapter 3, when we used it as an
all-purpose transfer mechanism for moving Plain Old XML (POX)
documents between clients and servers. In that example, however, the
semantics of POST were very loose,
conveying only that the client wished to âtransfer a documentâ to the
server with the hope that the server would somehow process it and
perhaps create a response document to complete the
interaction.
As the Restbucks coffee ordering service evolves into a CRUD
service, weâre going to strengthen the semantics of POST and use it as a request to create an
order resource within the service. To achieve this, the payload of the
POST request will contain a
representation of the new order to create, encoded as an XML document.
Figure 4-4 illustrates how this
works in practice.
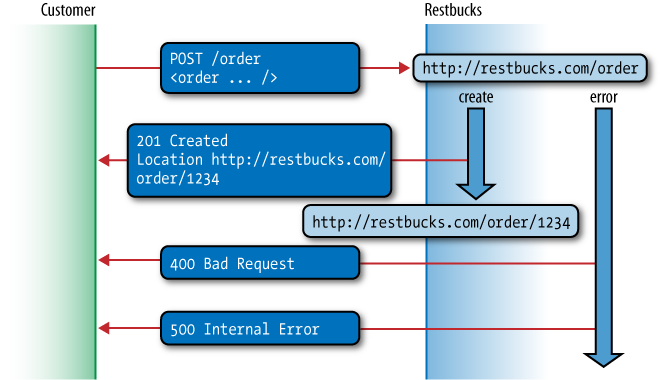
In our solution, creating an order at Restbucks requires that we
POST an order representation in XML
to the service.[28] The create request consists of the POST verb, the ordering service path
(relative to the Restbucks serviceâs URI), and the HTTP version. In
addition, requests usually include a Host header that identifies the receiving
host of the server being contacted and an optional port number.
Finally, the media type (XML in this case) and length (in bytes) of
the payload is provided to help the service process the request. Example 4-1 shows a network-level
view of a POST request that should
result in a newly created order.
Once the service receives the request, its payload is examined and, if understood, dispatched to create a new order resource.
Note
The receiving service may choose to be strict or lax with respect to the syntactic structure of the order representation. If it is strict, it may force compliance with an order schema. If the receiving service chooses to be lax (e.g., by extracting the information it needs through XPath expressions), its processing logic needs to be permissive with respect to the representation formats that might be used.
Robust services obey Postelâs Law,[29] which states, âbe conservative in what you do; be liberal in what you accept from others.â That is, a good service implementation is very strict about the resource representations it generates, but is permissive about any representations it receives.
If the POST request succeeds,
the server creates an order resource. It then generates an HTTP
response with a status code of 201
Created, a Location
header containing the newly created orderâs URI, and confirmation of
the new orderâs state in the response body, as we can see in Example 4-2.
HTTP/1.1 201 Created Content-Length: 267 Content-Type: application/xml Date: Wed, 19 Nov 2008 21:45:03 GMT Location: http://restbucks.com/order/1234 <order xmlns="http://schemas.restbucks.com/order"> <location>takeAway</location> <items> <item> <name>latte</name> <quantity>1</quantity> <milk>whole</milk> <size>small</size> </item> </items> <status>pending</status> </order>
The Location header that
identifies the URI of the newly created order resource is important.
Once the client has the URI of its order resource, it can then
interact with it via HTTP using GET,
PUT, and DELETE.
While a 201 Created response
is the normal outcome when creating orders, things may not always go according to
plan. As with any computing systemâespecially distributed
systemsâthings can and do go wrong. As service providers, we have to
be able to deal with problems and convey helpful information back to
the consumer in a structured manner so that the consumer can make
forward (or backward) progress. Similarly, as consumers of the
ordering service, we have to be ready to act on those problematic
responses.
Fortunately, HTTP offers a choice of response codes, allowing services to inform their consumers about a range of different error conditions that may arise during processing. The Restbucks ordering service has elected to support two error responses when a request to create a coffee order fails:
400 Bad Request, when the client sends a malformed request to the service500 Internal Server Error, for those rare cases where the server faults and cannot recover internally
With each of these responses, the server is giving the consumer information about what has gone wrong so that a decision can be made on how (or whether) to make further progress. It is the consumerâs job to figure out what to do next.
Note
500 Internal Server Error
as a catchall error response from the ordering service isnât very
descriptive. In reality, busy baristas might respond with 503 Service Unavailable and a Retry-After header indicating that the
server is temporarily too busy to process the request. Weâll see
event status codes and how they help in building robust distributed
applications in later chapters.
When the ordering service responds with a 400 status, it means the client has sent an
order that the server doesnât understand. In this case, the client
shouldnât try to resubmit the same order because it will result in the
same 400 response. For example, the
malformed request in Example 4-3
doesnât contain the drink that the consumer wants, and so cannot be a
meaningful coffee order irrespective of how strict or lax the server
implementation is in its interpretation. Since the <name> element is missing, the service
canât interpret what kind of drink the consumer wanted to order, and
so an order resource cannot be created. As a result, the service must
respond with an error.
POST /order HTTP/1.1
Host: restbucks.com
Content-Type: application/xml
Content-Length: 216
<order xmlns="http://schemas.restbucks.com/order">
<location>takeAway</location>
<items>
<item>
<quantity>1</quantity>
<milk>whole</milk>
<size>small</size>
</item>
</items>
</order>On receiving the malformed request, the server responds with a
400 status code, and includes a
description of why it rejected the request,[30] as we see in Example 4-4.
HTTP/1.1 400 Bad Request
Content-Length: 250
Content-Type: application/xml
Date: Wed, 19 Nov 2008 21:48:11 GMT
<order xmlns="http://schemas.restbucks.com/order">
<location>takeAway</location>
<items>
<item>
<!-- Missing drink type -->
<quantity>1</quantity>
<milk>whole</milk>
<size>small</size>
</item>
</items>
</order>To address this problem, the consumer must reconsider the content of the request and ensure that it meets the criteria expected by the ordering service before resubmitting it. If the service implementers were being particularly helpful, they might provide a textual or machine-processable description of why the interaction failed to help the consumer correct its request, or even just a link to the serviceâs documentation. The ordering service wonât create an order in this case, and so retrying with a corrected order is the right thing for the consumer to do.
In the case of a 500
response, the consumer may have no clear understanding about what
happened to the service or whether the request to create an order
succeeded, and so making forward progress can be tricky. In this case,
the consumerâs only real hope is to try again by repeating the
POST request to lodge an
order.
Note
In the general case, consumers can try to recompute
application state by GET ting the
current representations of any resources whose URIs they happen to know. Since
GET doesnât have side effects
(that consumers can be held accountable for), itâs safe to call
repeatedly until a sufficiently coherent picture of the system state
emerges and forward or backward progress can be made. However, at
this stage in our ordering protocol, the consumer knows nothing
other than the entry point URI for the coffee ordering service,
http://restbucks.com/order, and can only
retry.
On the server side, if the ordering service is in a recoverable state, or may eventually be, its implementation should be prepared to clean up any state created by the failed interaction. That way, the server keeps its own internal order state consistent whether the client retries or not.
Implementing create with POST
Now that we have a reasonable strategy for handling order creation, letâs see how to put it into practice with a short code sample (see Example 4-5).
protected void doPost(HttpServletRequest request, HttpServletResponse response) {
try {
Order order = extractOrderFromRequest(request);
if(order == null) {
response.setStatus(HttpServletResponse.SC_BAD_REQUEST);
} else {
String internalOrderId = saveOrder(order);
response.setHeader("Location", computeLocationHeader(request,
internalOrderId));
response.setStatus(HttpServletResponse.SC_CREATED);
} catch(Exception ex) {
response.setStatus(HttpServletResponse.SC_INTERNAL_SERVER_ERROR);
}
}The Java code in Example 4-5 captures the
pattern weâre following for processing a POST request on the service side. We
extract an order from the POST
request content and save it into a database. If that operation
fails, weâll conclude that the request from the consumer wasnât
valid and weâll respond with a 400 Bad
Request response, using the value SC_BAD_REQUEST. If the order is
successfully created, weâll embed that orderâs URI in a Location header and respond with a
201 status (using the SC_CREATED value) to the consumer. If
anything goes wrong, and an Exception is thrown, the service returns a
500 response using the SC_INTERNAL_SERVER_ERROR value.
Reading Resource State with GET
Weâve already seen how GET
can be used to invoke remote methods via URI tunneling, and weâve also
seen it being used to recover from 500 response codes during order creation.
From here onward, weâll be using GET explicitly for retrieving state
informationâresource representationsâfrom services. In our case, we
are going to use GET to retrieve
coffee orders from Restbucks that weâve previously created with
POST.
Using GET to implement the
âRâ in CRUD is straightforward. We know that after a successful
POST, the service creates a coffee
order at a URI of its choosing and sends that URI back to the consumer
in the HTTP responseâs Location
header. In turn, that URI allows consumers to retrieve the current
state of coffee order resources, as we see in Figure 4-5.
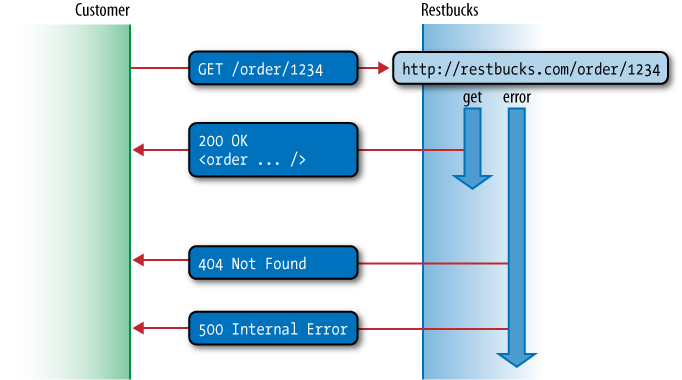
Performing GET on an orderâs
URI is very simple. At the HTTP level, it looks like Example 4-6.
If the GET request is
successful, the service will respond with a 200 OK status code and a representation of
the state of the resource, as shown in Example 4-7.
HTTP/1.1 200 OK
Content-Length: 241
Content-Type: application/xml
Date: Wed, 19 Nov 2008 21:48:10 GMT
<order xmlns="http://schemas.restbucks.com/order">
<location>takeAway</location>
<items>
<item>
<name>latte</name>
<quantity>1</quantity>
<milk>whole</milk>
<size>small</size>
</item>
</items>
<status>paid</status>
</order>The response from the server consists of a representation of the
order created by the original POST
request, plus some additional information such as the status, and a
collection of useful metadata in the headers. The first line includes
a 200 OK status code and a short
textual description of the outcome of the response informing us that
our GET operation was successful.
Two headers follow, which consumers use as hints to help parse the
representation in the payload. The Content-Type header informs us that the
payload is an XML document, while Content-Length declares the length of the
representation in bytes. Finally, the representation is found in the
body of the response, which is encoded in XML in accordance with the
Content-Type header.
A client can GET a
representation many times over without the requests causing the
resource to change. Of course, the resource may still change between
requests for other reasons. For example, the status of a coffee order
could change from âpendingâ to âservedâ as the barista makes progress.
However, the consumerâs GET
requests should not cause any of those state changes, lest they
violate the widely shared understanding that GET is safe.
Since Restbucks is a good web citizen, itâs safe to GET a representation of an order at any
point. However, clients should be prepared to receive different
representations over time since resource stateâthat is, the
orderâchanges on the server side as the barista prepares the coffee.
To illustrate the point, imagine issuing the GET request from Example 4-6 again a few minutes later.
This time around, the response is different because the orderâs status
has changed from paid to served (in the <status> element), since the barista
has finished preparing the drink, as we can see in Example 4-8.
HTTP/1.1 200 OK
Content-Length: 265
Content-Type: application/xml
Date: Wed, 19 Nov 2008 21:58:21 GMT
<order xmlns="http://schemas.restbucks.com/order">
<location>takeAway</location>
<items>
<item>
<name>latte</name>
<quantity>1</quantity>
<milk>whole</milk>
<size>small</size>
</item>
</items>
<status>served</status>
</order>In our CRUD ordering service, weâre only going to consider two
failure cases for GET. The first is
where the client requests an order that doesnât exist, and the second
is where the server fails in an unspecified manner. For these
situations, we borrow inspiration from the Web and use the 404 and 500 status codes to signify that an order
hasnât been found or that the server failed, respectively. For
example, the request in Example 4-9 identifies an
order that does not (yet) exist, so the service responds with the 404 Not
Found status code shown in Example 4-10.
GET /order/123456789012345667890 HTTP/1.1
Host: restbucks.comHTTP/1.1 404 Not Found Date: Sat, 20 Dec 2008 19:01:33 GMT
The 404 Not Found status code
in Example 4-10 informs
the consumer that the specified order is unknown to the
service.[31] On receipt of a 404
response, the client can do very little to recover. Effectively, its
view of application state is in violent disagreement with that of the
ordering service. Under these circumstances, Restbucks consumers
should rely on out-of-band mechanisms (such as pleading with the
barista!) to solve the problem, or try to rediscover the URI of their
order.
If the consumer receives a 500 Internal
Server Error status code as in Example 4-11, there may be a
way forward without having to immediately resort to out-of-band
tactics. For instance, if the server-side error is transient, the
consumer can simply retry the request later.
HTTP/1.1 500 Internal Server Error Date: Sat, 20 Dec 2008 19:24:34 GMT
This is a very simple but powerful recovery scenario whose
semantics are guaranteed by the behavior of GET. Since GET requests donât change service state,
itâs safe for consumers to GET
representations as often as they need. In failure cases, consumers
simply back off for a while and retry the GET request until they give up (and accept
handing over control to some out-of-band mechanism) or wait until the
service comes back online and processing continues.
Implementing read with GET
The code in Example 4-12 shows how
retrieving an order via GET can
be implemented using JAX-RS [32] in Java.
@Path("/order") public class OrderingService { @GET @Produces("application/xml") @Path("/{orderId}") public String getOrder(@PathParam("orderId") String orderId) { Order order = OrderDatabase.getOrder(orderId); if (order == null) { throw new WebApplicationException(Response.Status.NOT_FOUND); } else { try { return xstream.toXML(order); } catch (Exception e) { } } // Remainder of implementation omitted for brevity }
In Example 4-12, the root path
where our service will be hosted is declared using the @Path annotation, which in turn yields the
/order part of the URI. The
getOrder(â¦) method is annotated
with @GET, @Produces, and
@Path annotations that provide
the following behaviors:
@GETdeclares that thegetOrder(â¦)method responds to HTTPGETrequests.@Producesdeclares the media type that the method generates as its return value. In turn, this is mapped onto the HTTPContent-Typeheader in the response. Since the ordering service uses XML for order resource representations, we useapplication/xmlhere.@Pathdeclares the final part of the URI where the method is registered, using the URI template/{orderId}. By combining this with the root path declared at the class level, the service is registered at the URI/order/{orderId}.
The orderId parameter to
the getOrder(â¦) method is
automatically bound by JAX-RS using the @PathParam annotation on the methodâs
orderId parameter to match the
@Path annotation attached to the
method. Once this is all configured, the JAX-RS implementation
extracts the order identifier from URIs such as http://restbucks.com/order/1234 and makes it
available as the String parameter
called orderId in the getOrder(â¦) method.
Inside the getOrder(â¦)
method, we try to retrieve order information from the database keyed
by the orderId parameter. If we
find a record matching the orderId, we encode it as an XML document
using XStream[33] and return the document. This relinquishes control
back to JAX-RS, which in turn packages the XML-encoded order into an
HTTP response and returns it to the consumer. If we canât find the
order in the database, the implementation throws a WebApplicationException with the parameter
NOT_FOUND, which results in a
404 Not Found response code being
returned to the consumer. If something unpredicted goes wrong, such
as the loss of database connectivity, we throw a WebApplicationException but with a
500 Internal Server Error status
code indicated by the INTERNAL_SERVER_ERROR code. Either way,
JAX-RS takes care of all the plumbing for us, including the creation
of a well-formed HTTP response.
Note
Itâs interesting that the JAX-RS implementation for GET in Example 4-10 deals with a
substantial amount of plumbing code on our behalf when compared to
the bare servlet implementation in Example 4-3. However, itâs also
important to note that we donât have to use frameworks such as
JAX-RS to build CRUD services, since servlets (and other HTTP
libraries) can work just as well.
Updating a Resource with PUT
For the uninitiated, HTTP can be a strange protocol, not least
because it offers two ways of transmitting information from client to
server with the POST
and PUT verbs.
In their landmark book,[34] Richardson and Ruby established a convention for
determining when to use PUT and
when to use POST to resolve the
ambiguity:
Use
POSTto create a resource identified by a service-generated URI.Use
POSTto append a resource to a collection identified by a service-generated URI.Use
PUTto create or overwrite a resource identified by a URI computed by the client.
This convention has become widely accepted, and the Restbucks
ordering service embraces it by generating URIs for orders when
theyâre created by POST ing to the
well-known entry point: http://restbucks.com/order. Conversely, when updating orders via PUT, consumers specify the URIs. Figure 4-6 shows how using different verbs
disambiguates the two different cases and simplifies the
protocol.
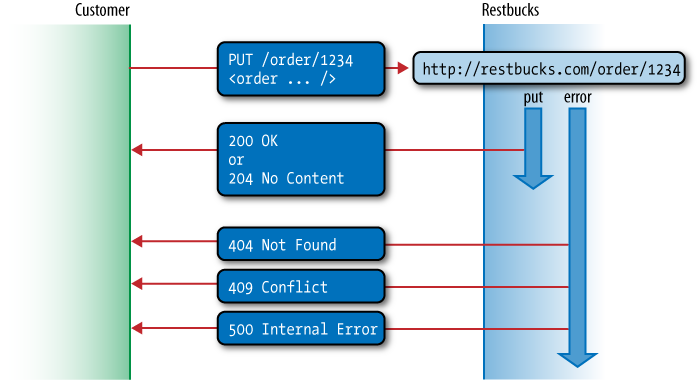
In Figure 4-6, consumers know
the URI of the order they want to update from the Location header received in the response to
an earlier POST (create) request.
Using that URI, a consumer can PUT
an updated order representation to the ordering service. In accordance
with the HTTP specification, a successful PUT request wonât create a new resource, but will instead update the state of the identified resource to reflect the data in the request representation.
Example 4-13 shows how a request for an
update looks on the wire. While the HTTP headers should look familiar,
in this case the HTTP body contains an XML representation of the
original order with the contents of the <milk> element for the cappuccino
changed to be skim rather than
whole.
PUT /order/1234 HTTP/1.1
Host: restbucks.com
Content-Type: application/xml
Content-Length: 246
<order xmlns="http://schemas.restbucks.com/order">
<location>takeAway</location>
<items>
<item>
<milk>skim</milk>
<name>cappuccino</name>
<quantity>1</quantity>
<size>large</size>
</item>
</items>
</order>Note
PUT expects the entire
resource representation to be supplied to the server, rather than
just changes to the resource state. Another relatively unknown HTTP
verb, PATCH, has been suggested
for use in situationsâtypically involving large resource
representationsâwhere only changes are provided. Weâll use PUT for now, but weâll also cover the use
of PATCH in the next
chapter.
When the PUT request is
accepted and processed by the service, the consumer will receive
either a 200 OK response as in
Example 4-14, or a
204 No Content response as in Example 4-15.
Whether 200 is used in
preference to 204 is largely an
aesthetic choice. However, 200
with a response body is more descriptive and actively
confirms the server-side state, while 204 is more efficient since it returns no
representation and indicates that the server has accepted the request
representation verbatim.
HTTP/1.1 200 OK
Content-Length: 275
Content-Type: application/xml
Date: Sun, 30 Nov 2008 21:47:34 GMT
<order xmlns="http://schemas.restbucks.com/order">
<location>takeAway</location>
<items>
<item>
<milk>skim</milk>
<name>cappuccino</name>
<quantity>1</quantity>
<size>large</size>
</item>
</items>
<status>preparing</status>
</order>HTTP/1.1 204 No Content Date: Sun, 30 Nov 2008 21:47:34 GMT
On receiving a 200 or
204 response, the consumer can be
satisfied that the order has been updated. However, things can and do
go wrong in distributed systems, so we should be prepared to deal with
those eventualities.
The most difficult of the three failure response codes from
Figure 4-6 is where a request has
failed because of incompatible state. An example of this kind of
failure is where the consumer tries to change its order after drinks
have already been served by the barista. To signal conflicting state
back to the client, the service responds with a 409 Conflict
status code, as shown in Example 4-16.
HTTP/1.1 409 Conflict
Date: Sun, 21 Dec 2008 16:43:07 GMT
Content-Length:271
<order xmlns="http://schemas.restbucks.com/order">
<location>takeAway</location>
<items>
<item>
<milk>whole</milk>
<name>cappuccino</name>
<quantity>1</quantity>
<size>large</size>
</item>
</items>
<status>served</status>
</order>In keeping with the HTTP specification, the response body
includes enough information for the client to understand and
potentially fix the problem, if at all possible. To that end, Example 4-16 shows that the
ordering service returns a representation of the current state of the
order resource from the service. In the payload, we can see that the
<status> element contains the
value served, which indicates that
the order cannot be altered. To make progress, the consumer will have
to interpret the status code and payload to determine what might have
gone wrong.
Note
We might reasonably expect that either 405 Method Not Allowed or 409 Conflict would be a valid choice for a
response code in situations where PUTting an update to a resource isnât
supported. In this instance, we chose 409 since PUT may be valid for some updates that
donât violate business rules. For example, it might still be
permitted to change the order from drink-in to take-away during the
orderâs life cycle since itâs just a matter of changing cups.
As with errors when processing POST and GET, a 500 response code is equally straightforward
when using PUTâsimply wait and
retry. Since PUT is
idempotentâbecause service-side state is replaced
wholesale by consumer-side stateâthe consumer can safely
repeat the operation as many times as necessary. However, PUT can only be safely used for absolute
updates; it cannot be used for relative updates such as âadd an extra
shot to the cappuccino in order 1234.â That would violate its
semantics.
Note
PUT is one of the
HTTP verbs that has idempotent semantics (along with
GET and DELETE in this
chapter). The ordering service must therefore guarantee that
PUTting the same order many times
has the same side effects as PUTting it exactly once. This greatly
simplifies dealing with intermittent problems and crash recovery by
allowing the operation to be repeated in the event of
failure.
If the service recovers, it simply applies any changes from any
of the PUT requests to its
underlying data store. Once a PUT
request is received and processed by the ordering service, the
consumer will receive a 200 OK
response.
Implementing update with PUT
Now that we understand the update process, implementation is
straightforward, especially with a little help from a framework.
Example 4-17 shows an
implementation of the update operation using the HTTP-centric
features of Microsoftâs WCF. The service contractâthe set of
operations that will be exposedâis captured by the IOrderingService interface. In turn, the
IOrderingService is adorned by a
[ServiceContract] attribute that
binds the interface to WCF so that the underlying framework can
expose implementing classes as services.[35] For our purposes, the most interesting aspect of this
code is the [WebInvoke]
attribute, which, when used in tandem with an [OperationContract] attribute, declares
that the associated method is accessible via HTTP.
[ServiceContract]
public interface IOrderingService
{
[OperationContract]
[WebInvoke(Method = "PUT", UriTemplate = "/order/{orderId}")]
void UpdateOrder(string orderId, Order order);
// Remainder of service contract omitted for brevity
}The [WebInvoke] attribute
takes much of the drudgery out of plumbing together URIs, entity
body payloads, and the methods that process representations.
Compared to lower-level frameworks, the WCF approach removes much
boilerplate plumbing code.
In Example 4-17, the [WebInvoke] attribute is parameterized so
that it responds only to the PUT
verb, at URIs that match the URI template /order/{orderId}. The value supplied in
{orderId} is bound at runtime by
WCF to the string parameter
orderId, which is then used to
process the update.
When invoked, the representation in the HTTP body is
deserialized from XML and dispatched to the implementing method as
an instance of the Order type. To
achieve this, we declare the mapping between the on-the-wire XML and
the local Order object by
decorating the Order type
with [DataContract]
and [DataMember] attributes, as
shown in Example 4-18.
These declarations help the WCF serializer to marshal objects to and
from XML. Once the WCF serializer completes the deserialization
work, all we need to implement is the update business logic, as
shown in Example 4-19.
[DataContract(Namespace = "http://schemas.restbucks.com/order", Name = "order")]
public class Order
{
[DataMember(Name = "location")]
public Location ConsumeLocation
{
get { return location; }
set { location = value; }
}
[DataMember(Name = "items")]
public List<Item> Items
{
get { return items; }
set { items = value; }
}
[DataMember(Name = "status")]
public Status OrderStatus
{
get { return status; }
set { status = value; }
}
// Remainder of implementation omitted for brevity
}public void UpdateOrder(string orderId, Order order)
{
try
{
if (OrderDatabase.Database.Exists(orderId))
{
bool conflict = OrderDatabase.Database.Save(order);
if (!conflict)
{
WebOperationContext.Current.OutgoingResponse.StatusCode =
HttpStatusCode.NoContent;
}
else
{
WebOperationContext.Current.OutgoingResponse.StatusCode =
HttpStatusCode.Conflict;
}
}
else
{
WebOperationContext.Current.OutgoingResponse.StatusCode =
HttpStatusCode.NotFound;
}
}
catch (Exception)
{
WebOperationContext.Current.OutgoingResponse.StatusCode =
HttpStatusCode.InternalServerError;
}
}The code in Example 4-19 first checks
whether the order exists in the database. If the order is found, it
is simply updated and a 204 No
Content status code is returned to the consumer by setting
the WebOperationContext.Current.OutgoingResponse.StatusCode
property.
If thereâs a conflict while trying to update the order, a
409 Conflict response and a
representation highlighting the inconsistency will be returned to
the consumer.
Note
Itâs worth noting that the only identifier we have for the
order comes from the URI itself, extracted by WCF via the {orderId} template. Thereâs no order ID
embedded in the payload, since it would be superfluous. Following
this DRY (Donât Repeat Yourself) pattern, we avoid potential
inconsistencies between the domain model and the resources the
service exposes, and keep the URI as the authoritative identifier,
as it should be.
If we canât find the entry in the database, weâll set a
404 Not Found response to
indicate the order resource isnât hosted by the service. Finally, if
something unexpected happens, weâll catch any Exception and set a 500 Internal Server Error status code on
the response to flag that the consumer should take some alternative
(recovery) action.
Removing a Resource with DELETE
When a consumer decides that a resource is no longer useful, it
can send an HTTP DELETE request to
the resourceâs URI. The service hosting that resource will interpret
the request as an indication that the client has become disinterested
in it and may decide that the resource should be removedâthe decision
depends on the requirements of the service and the service
implementation.
Note
Deleting a resource doesnât always mean the resource is physically deleted; there are a range of outcomes. A service may leave the resource accessible to other applications, make it inaccessible from the Web and maintain its state internally, or even delete it outright.
Figure 4-7 highlights the
use of DELETE in the Restbucks
ordering service where DELETE is
used to cancel an order, if that order is in a state where it can
still be canceled. For example, sending DELETE to an orderâs URI prior to
preparation should be successful and the client should expect a
204 No Content response from the
service as a confirmation.
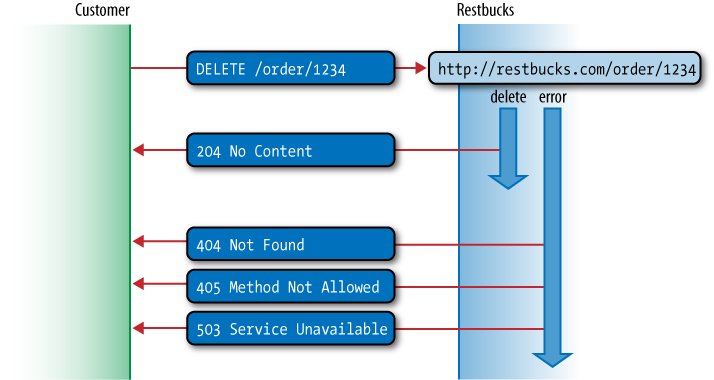
Conversely, if the order has already been prepared, which means
it canât be deleted, a 405 Method Not
Allowed response would be used. If the service is
unavailable to respond to our DELETE request for some other reason, the
client can expect a 503 Service
Unavailable response and might try the request again
later.
On the wire, DELETE requests
are simple, consisting only of the verb, resource URI, protocol
version, and HOST (and optional
PORT) header(s), as shown in Example 4-20.
Assuming the ordering service is able to satisfy the DELETE request, it will respond
affirmatively with a 204 No Content
response, as shown in Example 4-21.
HTTP/1.1 204 No Content Date: Tue, 16 Dec 2008 17:40:11 GMT
Note
Some services may elect to return the final state of the
deleted resource on the HTTP response. In those cases, 204 isnât appropriate, and a 200 OK response along with Content-Type and Content-Length headers and a resource
representation in the body is used.
Failure cases tend to be intricate with DELETE requests, since they might have
significant side effects! One such failure case is shown in Example 4-22, where the client has
specified a URI that the server cannot map to an order, causing the
ordering service to generate a 404 Not
Found response.
HTTP/1.1 404 Not Found Content-Length: 0 Date: Tue, 16 Dec 2008 17:42:12 GMT
Although this is a simple response to understandâwe see it all too often on the human Web, after allâitâs troubling from a programmatic perspective because it means the consumer has stale information about order resource state compared to the service.
We might take one of several different recovery strategies when
we get a 404 Not Found response.
Ordinarily, we might prefer a human to resolve the problem through
some out-of-band mechanism. However, in some situations, it may be
practical for the consumer to recompute application state by
retrieving representations of the resources it knows about and attempt
to make forward progress once itâs synchronized with the
service.
Restbucks archives all orders after they have been served for
audit purposes. Once archived, the order becomes immutable, and any
attempts to DELETE an archived
order will result in a 405 Method Not
Allowed response from the ordering service, as shown in
Example 4-23.
HTTP/1.1 405 Method Not Allowed Allow: GET Date: Tue, 23 Dec 2008 16:23:49 GMT
The response in Example 4-23
informs the client that while the order resource still exists, the
client is not allowed to DELETE it.
In fact, the Allow header is used
to convey that GET is the only
acceptable verb at this point in time and that requests using any
other verb will be met with a 405 Method Not
Allowed response.
Note
The Allow header can be
used to convey a comma-separated list of verbs that can be applied
to a given resource at an instant.
An implementation for DELETE
using the HttpListener from the
.NET Framework is shown in Example 4-24. Like the servlet
implementation in Example 4-5, this example
shows that itâs possible to develop services with just an HTTP
library, and that we donât always have to use sophisticated
frameworks.
static void DeleteResource(HttpListenerContext context)
{
string orderId = ExtractOrderId(context.Request.Url.AbsolutePath);
var order = OrderDatabase.Retrieve(orderId);
if (order == null)
{
context.Response.StatusCode = HttpStatusCode.NotFound;
}
else if (order.CanDelete)
{
OrderDatabase.archive(orderId);
context.Response.StatusCode = HttpStatusCode.NoContent;
}
else
{
context.Response.StatusCode = HttpStatusCode.MethodNotAllowed;
}
context.Response.Close();
}In Example 4-24, an
HTTPListenerContext instance
provides access to the underlying HTTP request and response messages.
Using the request URI, we extract an order identifier and then
determine whether it corresponds to a valid order. If no order is
found, we immediately set the HTTP response to 404
and call Close() on the response
object to return control to the web server, which in turn returns a
well-formed 404 Not Found response
message to the consumer.
If we can find the resource, we check whether weâre allowed to
delete it. If we are, we logically remove the associated order before
returning a 204 No Content response
to the client. Otherwise, we set the response code to 405 and let the client know they canât
delete that resource.
Safety and Idempotency
We saw in Chapter 3 that GET is special since it has the properties
of being both safe and idempotent. PUT and DELETE are both idempotent, but neither is
safe, while POST is neither safe
nor idempotent. Only GET returns
the same result with repeated invocations and has no side effects for
which the consumer is responsible.
With GET, failed requests can
be repeated without changing the overall behavior of an application.
For example, if any part of a distributed application crashes in the
midst of a GET operation, or the
network goes down before a response to a GET is received, the client can just reissue
the same request without changing the semantics of its interaction
with the server.
In broad terms, the same applies to both PUT and DELETE requests. Making an absolute update
to a resourceâs state or deleting it outright has the same outcome
whether the operation is attempted once or many times. Should PUT or DELETE fail because of a transient network
or server error (e.g., a 503
response), the operation can be safely repeated.
However, since both PUT and
DELETE introduce side effects
(because they are not safe), it may not always be possible to simply
repeat an operation if the server refuses it at first. For instance,
we have already seen how a 409
response is generated when the consumer and serviceâs view of resource
state is inconsistentâmerely replaying the interaction is unlikely to
help. However, HTTP offers other useful features to help us when state
changes abound.
Aligning Resource State
In a distributed application, itâs often the case that several consumers might interact with a single resource, with each consumer oblivious to changes made by the others. As well as these consumer-driven changes, internal service behaviors can also lead to a resourceâs state changing without consumers knowing. In both cases, a consumerâs understanding of resource state can become misaligned with the serviceâs resource state. Without some way of realigning expectations, changes requested by a consumer based on an out-of-date understanding of resource state can have undesired effects, from repeating computationally expensive requests to overwriting and losing another consumerâs changes.
HTTP provides a simple but powerful mechanism for aligning resource state expectations (and preventing race
conditions) in the form of entity tags and
conditional request headers. An entity tag value,
or ETag, is an opaque string token
that a server associates with a resource to uniquely identify the state
of the resource over its lifetime. When the resource changesâthat is,
when one or more of its headers, or its entity body, changesâthe entity
tag changes accordingly, highlighting that state has been
modified.
ETag s are used to compare
entities from the same resource. By supplying an entity tag value in a
conditional request headerâeither an If-Match or an If-None-Match request headerâa consumer can
require the server to test a precondition related to the current
resource state before applying the method supplied in the
request.
Note
ETags are also used for cache
control purposes, as weâll see in Chapter 6.
To illustrate how ETags can be
used to align resource state in a multiconsumer scenario, imagine a
situation in which a party of two consumers places an order for a single
coffee. Shortly after placing the order, the first consumer decides it
wants whole milk instead of skim milk. Around the same time, the second
consumer decides it, too, would like a coffee. Neither consumer consults
the other before trying to amend the order.
To begin, both consumers GET
the current state of the order independently of each other. Example 4-25 shows one of the consumerâs
requests.
The serviceâs response contains an ETag header whose value is a hash of the
returned representation (Example 4-26).
HTTP/1.1 200 OK
Content-Type: application/xml
Content-Length: 275
ETag: "72232bd0daafa12f7e2d1561c81cd082"
<order xmlns="http://schemas.restbucks.com/order">
<location>takeAway</location>
<items>
<item>
<milk>skim</milk>
<name>cappuccino</name>
<quantity>1</quantity>
<size>large</size>
</item>
</items>
<status>pending</preparing>
</order>Note
The service computes the entity tag and supplies it as a quoted
string in the ETag header prior to
returning a response. Entity tag values can be based on anything that
uniquely identifies an entity: a version number associated with a
resource in persistent storage, one or more file
attributes, or a checksum of the entity headers and body, for example.
Some methods of generating entity tag values are more computationally
expensive than others. ETags are
often computed by applying a hash function to the resourceâs state,
but if hashes are too computationally expensive, any other scheme that
produces unique values can be used. Whichever method is used, we
recommend attaching ETag headers to
responses wherever possible.
When a consumer receives a response containing an ETag, it can (and should) use the value in any
subsequent requests it directs to the same resource. Such requests are
called conditional requests. By supplying the
received entity tag as the value of an If-Match or If-None-Match conditional header, the consumer
can instruct the service to process its request only if the precondition
in the conditional header holds true.
Of course, consumers arenât obliged to retransmit ETags theyâve received, and so services canât
expect to receive them just because theyâve been generated. However,
consumers that donât take advantage of ETags are disadvantaged in two ways. First,
consumers will encounter increased response times as services have to
perform more computation on their behalf. Second, consumers will
discover their state has become out of sync with service state through
status codes such as 409 Conflict at
inconvenient and (because theyâre not using ETags) unexpected times. Both of these
failings are easily rectified by diligent use of ETags.
An If-Match request header
instructs the service to apply the consumerâs request only if the
resource to which the request is directed hasnât
changed since the consumer last retrieved a representation of
it. The service determines whether the resource has changed by comparing
the resourceâs current entity tag value with the value supplied in the
If-Match header. If the values are
equal, the resource hasnât changed. The service then applies the method
supplied in the request and returns a 2xx response. If the entity tag values donât
match, the server concludes that the resource has changed since the
consumer last accessed it, and responds with 412 Precondition Failed.
Note
Services are strict about processing the If-Match header. A service canât (and
shouldnât) do clever merges of resource state where one coffee is removed and another,
independent coffee in the same order is changed to decaf. If two parts
of a resource are independently updatable, they should be separately
addressable resources. For example, if fine-grained control over an
order is useful, each cup of coffee could be modeled as a separate
resource.
Continuing with our example, the first consumer does a conditional PUT to
update the order from skim to whole milk. As Example 4-27 shows, the
conditional PUT includes an If-Match header containing the ETag value from the previous GET.
PUT /order/1234 HTTP/1.1
Host: restbucks.com
If-Match: "72232bd0daafa12f7e2d1561c81cd082"
<order xmlns="http://schemas.restbucks.com/order">
<location>takeAway</location>
<items>
<item>
<milk>whole</milk>
<name>cappuccino</name>
<quantity>1</quantity>
<size>large</size>
</item>
</items>
<status>pending</preparing>
</order>Because the order hadnât been modified since the first consumer
last saw it, the PUT succeeds, as
shown in Example 4-28.
HTTP/1.1 204 No Content ETag: "6e87391fdb5ab218c9f445d61ee781c1"
Notice that while the response doesnât include an entity body, it
does include an updated ETag header.
This new entity tag value reflects the new state of the order resource
held on the server (the result of the successful PUT).
Oblivious to the change that has just taken place, the second
consumer attempts to add its order, as shown in Example 4-29. This request
again uses a conditional PUT, but
with an entity tag value that is now out of date (as a result of the
first consumerâs modification).
PUT /order/1234 HTTP/1.1 Host: restbucks.com If-Match: "72232bd0daafa12f7e2d1561c81cd082" <order xmlns="http://schemas.restbucks.com/order"> <location>takeAway</location> <items> <item> <milk>skim</milk> <name>cappuccino</name> <quantity>2</quantity> <size>large</size> </item> </items> <status>pending</status> </order>
The service determines that the second consumer is trying to modify the order based on an out-of-date understanding of resource state, and so rejects the request, as shown in Example 4-30.
When a consumer receives a 412
Precondition Failed status code, the correct thing to do is to
GET a fresh representation of the
current state of the resource, and then use the ETag header value supplied in this response to
retry the original request, which is what the second consumer does in
this case. Having done a fresh GET,
the consumer sees that the original order had been modified. The second
consumer is now in a position to PUT
a revised order that reflects both its and the first consumerâs
wishes.
Our example used the If-Match
header to prevent the second consumer from overwriting the first
consumerâs changes. Besides If-Match,
consumers can also use If-None-Match.
An If-None-Match header instructs the
service to process the request only if the associated resource
has changed since the consumer last accessed it.
The primary use of If-None-Match is
to save valuable computing resources on the service side. For example,
it may be far cheaper for a service to compare ETag values than to perform computation to
generate a representation.
Note
If-None-Match is mainly used
with conditional GETs, whereas
If-Match is typically used with the
other request methods, where race conditions between multiple
consumers can lead to unpredictable side effects unless properly
coordinated.
Both If-Match and If-None-Match allow the use of a wildcard
character, *, instead of a normal
entity tag value. An If-None-Match
conditional request that takes a wildcard entity tag value
instructs the service to apply the request method only if the resource doesnât currently exist. Wildcard If-None-Match requests help to prevent race
conditions in situations where multiple consumers compete to PUT a new resource to a well-known URI. In
contrast, an If-Match conditional
request containing a wildcard value instructs the service to apply the
request only if the resource does exist. Wildcard If-Match requests are useful in situations
where the consumer wishes to modify an existing resource using a
PUT, but only if the resource hasnât
already been deleted.
Note
As well as ETag and its
associated If-Match and If-None-Match headers, HTTP supports a timestamp-based Last-Modified header and its two associated
conditional headers: If-Modified-Since and If-Unmodified-Since. These timestamp-based
conditional headers act in exactly the same way as the If-Match and If-None-Match headers, but the conditional
mechanism they implement is accurate only to the nearest secondâthe
limit of the timestamp format used by HTTP. Because timestamps are often cheaper than hashes, If-Modified-Since and If-Unmodified-Since may be preferable in
solutions where resources donât change more often than once per
second.
In practice, we tend to use timestamps as cheap ETag header values, rather than as Last-Modified values. By using ETags from the outset, we ensure that the
upgrade path to finer-grained ETags
is entirely at the discretion of the service. The service can switch
from using timestamps to using hashes without upsetting
clients.
Consuming CRUD Services
Services are one side of distributed systems, but to perform useful work they need consumers to drive them through their protocols. Fortunately, many frameworks and libraries support CRUD Web Services, and itâs worthwhile to understand a little about what they offer.
A Java-Based Consumer
In the Java world, we might use the Apache Commons HTTP client[36] to implement the Create part of the protocol by POSTing an order to the ordering service, as
shown in Example 4-31.
public String placeOrder(Order order, String restbucksOrderingServiceUri)
throws BadRequestException, ServerFailureException,
HttpException, IOException {
PostMethod post = new PostMethod(restbucksOrderingServiceUri);
// Use an existing XStream instance to generate XML for the order to transmit
RequestEntity entity = new ByteArrayRequestEntity(
xstream.toXML(order).getBytes());
post.setRequestEntity(entity);
HttpClient client = new HttpClient();
try {
int response = client.executeMethod(post);
if(response == 201) {
return post.getResponseHeader("Location").getValue();
} else if(response == 400) {
// If we get a 400 response, the caller's gone wrong
throw new BadRequestException();
} else if(response == 500 || response == 503) {
// If we get a 5xx response, the caller may retry
throw new ServerFailureException(post.getResponseHeader("Retry-After"));
}
// Otherwise abandon the interaction
throw new HttpException("Failed to create order. Status code: " + response);
} finally {
post.releaseConnection();
}
}The implementation in Example 4-31 shows the construction
of a POST operation on the ordering
service, using a PostMethod object.
All we need to do is to populate the HTTP request with the necessary
coffee order information by setting the request entity to contain the
bytes of an XML representation of the order. To keep things simple for
ourselves, we use the XStream library to encode the order resource
representation in XML.
Having populated the HTTP request, we instantiate an HttpClient and execute the PostMethod, which POSTs the order to the Restbucks ordering
service. Once the method returns, we examine the response code for a
201 Created status and return the
contents of the Location header,
which will contain the URI of the newly created order. We can use this
URI in subsequent interactions with Restbucks. If we donât get a
201 response, we fail by throwing
an HTTPException, and assume that
order creation has failed.
A .NET Consumer
On the .NET platform, we can opt for the frameworkâs built-in
XML and HTTP libraries. The code in Example 4-32 represents how a
client can send an order update to the Restbucks ordering service via
HTTP PUT.
public void UpdateOrder(Order order, string orderUri)
{
HttpWebRequest request = WebRequest.Create(orderUri) as HttpWebRequest;
request.Method = "PUT";
request.ContentType = "application/xml";
XmlSerializer xmlSerializer = new XmlSerializer(typeof(Order));
xmlSerializer.Serialize(request.GetRequestStream(), order);
request.GetRequestStream().Close();
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
if (response.StatusCode != HttpStatusCode.OK)
{
// Compensation logic omitted for brevity
}
}In Example 4-32,
we use an HTTPWebRequest instance
to handle the HTTP aspects of the interaction. First we set the HTTP
verb PUT via the Method property and subsequently set the
Content-Type header to application/xml through the ContentType property. We then write an
XML-serialized representation of the order object that was given as an argument
to the UpdateOrder() method. The
XmlSerializer transforms the local
object instance into an XML document, and the Serialize() method writes the XML to the
requestâs stream. Once weâre done populating the request stream, we
simply call Close(). Under the
covers, the framework sets other headers such as Content-Length and Host for us, so we donât have to worry about
them.
To send the request we call the GetResponse() method on the request object, which has the effect of
transmitting an HTTP PUT to the URI
supplied as an argument to the updateOrder() method. The response from the
ordering service is returned as an HttpWebResponse and its StatusCode property triggers any further
processing.
One final job that we need to undertake is to mark up the
Order type so that the XmlSerializer knows how to transform
Order instances to and from XML
representations. The code snippet in Example 4-33 shows the .NET attributes that
we need to apply for our client-side plumbing to be complete.
Consuming Services Automatically with WADL
Although the patterns for writing clients in .NET and Java are easy to understand and implement, we can save ourselves effortâand, in some cases, generate code automaticallyâusing service metadata. Up to this point, much of the work weâve done in building our ordering service and its consumers has been plumbing code. But for some kinds of services,[37] a static description can be used to advertise the addresses and representation formats of the resources the service hosts. This is the premise of the Web Application Description Language, or WADL.
A WADL contract is an XML document that describes a set of resources with URI templates, permitted operations, and request-response representations. As youâd expect, WADL also supports the HTTP fault model and supports the description of multiple formats for resource representations. Example 4-34 shows a WADL description of the Restbucks ordering service.
<?xml version="1.0" encoding="utf-8"?>
<application
xmlns:xsd=http://www.w3.org/2001/XMLSchema
xmlns="http://research.sun.com/wadl/2006/10"
xmlns:ord="http://schemas.restbucks.com/order">
<grammars>
<include href="order.xsd"/>
</grammars>
<resources base="http://restbucks.com/">
<resource path="order">
<method name="POST">
<request>
<representation mediaType="application/xml" element="ord:order"/>
</request>
<response>
<representation status="201"/>
<fault mediaType="application/xml" element="ord:error" status="400"/>
<fault mediaType="application/xml" element="ord:error" status="500"/>
</response>
</method>
</resource>
<resource path="order/{orderId}">
<method name="GET">
<response>
<representation mediaType="application/xml" element="ord:order"/>
<fault mediaType="application/xml" element="ord:error" status="404"/>
<fault mediaType="application/xml" element="ord:error" status="500"/>
</response>
</method>
<method name="PUT">
<request>
<representation mediaType="application/xml" element="ord:order"/>
</request>
<response>
<representation status="200"/>
<fault mediaType="application/xml" element="ord:error" status="404"/>
<fault mediaType="application/xml" element="ord:error" status="409"/>
<fault mediaType="application/xml" element="ord:error" status="500"/>
</response>
</method>
<method name="DELETE">
<response>
<representation status="200"/>
<fault mediaType="application/xml" element="ord:error" status="404"/>
<fault mediaType="application/xml" element="ord:error" status="405"/>
<fault mediaType="application/xml" element="ord:error" status="500"/>
</response>
</method>
</resource>
</resources>
</application>The <application> element
is the root for the WADL metadata. It acts as the container for schemas that
describe the serviceâs resource representations in the <grammars> element and the resources
that are contained within the <resources> element. The <grammars> element typically refers to
XML Schema schemas (which we have defaulted to for Restbucks) that
describe the structure of the resource representations supported by the
service, though other schema types (e.g., RELAX NG) are supported too.
Consumers of the service can use this information to create local
representations of those resources such as orders and products.
In a WADL description, the <resources> element is where most of the
action happens. It provides a static view of the resources available for
consumption. It uses a templating scheme that allows consumers to infer
the URIs of the resources supported by a service. Calculating URIs can
be a little tricky since WADL relies on a hierarchy of resources, with
each URI based on the parent URIâs template plus its own. In Example 4-34, we have two logical
resources: http://restbucks.com/order
for POST and http://restbucks.com/order/{orderId} for the
other verbs. The resource URIs are computed by appending the path of the <resource> element to the path defined
in the base attribute of the <resources> element.
Note
In addition to dealing with URI templates and query strings, WADL also has a comprehensive mechanism for building URIs. WADL can deal with form encoding and handling a range of URI structures, including matrix URIs.[38]
The <method> element
allows WADL to bring together the request and response resource
representations and HTTP verbs to describe the set of permissible
interactions supported by the service. The Restbucks ordering service is
described in terms of two separate resource paths. We first define the
order resource (<resource path=âorderâ>), which only
allows POST requests (<method name=âPOSTâ>) and requires that
the payload of those requests be XML representations of an order. We
also describe the possible ways the Restbucks ordering service can reply
to a POST request (in the <response> element) depending on the
outcome of processing the submitted order. In this case, the possible
response code is 201, 400, or
500.
Using a URI template, a second set of resourcesâthe orders that
Restbucks has createdâis advertised by the element <resource path=âorder/{orderId}â>. Like
the POST method element, each
subsequent <method> element
describes the possible responses and faults that the ordering service
might return. Additionally, the PUT
<method> element declares that an XML order
representation must be present as the payload of any PUT requests.
While itâs helpful that we can read and write WADL by hand (at least in simple cases), the point of WADL is to help tooling automate as much service plumbing as possible. To illustrate how WADL can be consumed by an automation infrastructure, the authors of WADL have created the WADL2Java[39] tool.[40] WADL2Java allows us to create consumer-side Java that minimizes the code we have to write in order to interact with a service described in WADL. The Java code in Examples Example 4-35 and Example 4-36 shows the consumer-side API that Java programmers can use to interact with a WADL-decorated ordering service.
public class Endpoint {
public static class Orders {
public DataSource postAsIndex(DataSource input)
throws IOException, MalformedURLException {
// Implementation removed for brevity
}
}
public static class OrdersOrderId {
public OrdersOrderId(String orderid)
throws JAXBException {
// Implementation removed for brevity
}
// Getters and setters omitted for brevity
public DataSource getAsApplicationXml()
throws IOException, MalformedURLException {
// Implementation removed for brevity
}
public Order getAsOrder()
throws ErrorException, IOException, MalformedURLException, JAXBException {
// Implementation removed for brevity
}
public DataSource putAsIndex(DataSource input)
throws IOException, MalformedURLException {
// Implementation removed for brevity
}
public DataSource deleteAsIndex()
throws IOException, MalformedURLException {
// Implementation removed for brevity
}
}
}In Java, resources are locally represented by classes such as
Order, shown in Example 4-36, which allow us to
inspect and set values in the XML representations exchanged with the
ordering service.
@XmlAccessorType(XmlAccessType.FIELD)
@XmlType(name = "", propOrder = {
"location",
"items",
"status"
})
@XmlRootElement(name = "order")
public class Order {
@XmlElement(required = true)
protected String location;
@XmlElement(required = true)
protected Order.Items items;
@XmlElement(required = true)
protected String status;
// Getters and setters only, omitted for brevity
}WADL can be useful as a description language for CRUD services such as the ordering service. It can be used to automatically generate plumbing code with very little effort, compared to manually building clients. Since the client and server collaborate over the life cycle of a resource, its URI, and its representation format, it does not matter whether the plumbing is generated from a metadata description. Indeed, WADL descriptions may help expedite consumer-side maintenance when changes happen on the server side.
CRUD Is Good, but Itâs Not Great
Now that weâve completed our tour of CRUD services, itâs clear that using HTTP as a CRUD protocol can be a viable, robust, and easily implemented solution for some problem domains. In particular for systems that manipulate records, HTTP-based CRUD services are a straightforward way to extend reach over the network and expose those applications to a wider range of consumers.[41]
Since we can implement CRUD services using a small subset of HTTP, our integration needs may be completely satisfied with few CRUD-based services. Indeed, this is typically where most so-called RESTful services stop.[42] However, itâs not the end of our journey, because for all their strengths and virtue of simplicity, CRUD services are only suited to CRUD scenarios. More advanced requirements need richer interaction models and, importantly, will emphasize stronger decoupling than CRUD allows.
To decouple our services from clients and support general-purpose distributed systems, we need to move away from a shared, tightly coupled understanding of resource life cycles. On the human Web, this model has long been prevalent when using hyperlinks to knit together sequences of interactions that extend past CRUD operations. In the next chapter, weâre going to replicate the same hypermedia concept from the Web to create robust distributed systems.
[28] Weâve adopted the convention used in RESTful Web
Services (http://oreilly.com/catalog/9780596529260/) by
Leonard Richardson and Sam Ruby (OâReilly), where POST is used for creation and the server
determines the URI of the created resource.
[30] This is demanded of us by the HTTP specification.
[31] If we wanted to be more helpful to the consumer, our service could provide a helpful error message in the HTTP body.
[32] Oracle Corp. website. âJAX-RS (JSR 311): The Java API for RESTful Web Servicesâ; see http://jcp.org/en/jsr/detail?id=311.
[34] RESTful Web Services (http://oreilly.com/catalog/9780596529260/), published by OâReilly.
[35] WCF implements the same model for all kinds of remote behavior, including queues and WS-* Web Services. This lowest-common-denominator approach seeks to simplify programming distributed systems. Unfortunately, it often hides essential complexity, so use it with care!
[37] CRUD services are great candidates for describing with WADL. Hypermedia servicesâas we will see in the next chapterâuse different mechanisms to describe the protocols they support.
[40] Other tools also exist; for example, REST Describe at http://tomayac.de/rest-describe/latest/RestDescribe.html.
[41] Naively exposing systems that have not been built for network access is a bad idea. Systems have to be designed to accommodate network loads.
[42] Weâre being generous here, since most so-called RESTful services tend to stop at tunneling through HTTP!
Get REST in Practice now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

