Astute readers such as yourself may be wondering whether the title of this book, Safe C++, presumes that the C++ programming language is somehow unsafe. Good catch! That is indeed the presumption. The C++ language allows programmers to make all kinds of mistakes, such as accessing memory beyond the bounds of an allocated array, or reading memory that was never initialized, or allocating memory and forgetting to deallocate it. In short, there are a great many ways to shoot yourself in the foot while programming in C++, and everything will proceed happily along until the program abruptly crashes, or produces an unreasonable result, or does something that in computer literature is referred to as âunpredictable behavior.â So yes, in this sense, the C++ language is inherently unsafe.
This book discusses some of the most common mistakes made by us, the programmers, in C++ code, and offers recipes for avoiding them. The C++ community has developed many good programming practices over the years. In writing this book I have collected a number of these, slightly modified some, and added a few, and I hope that this collection of rules formulated as one bug-hunting strategy is larger than the sum of its parts.
The undeniable truth is that any program significantly more complex than âHello, Worldâ will contain some number of errors, also affectionately called âbugs.â The Great Question of Programming is how we can reduce the number of bugs without slowing the process of programming to a halt. To start with, we need to answer the following question: just who is supposed to catch these bugs?
There are four participants in the life of the software program (Figure 1):
The programmer
The compiler (such as g++ under Unix/Linux, Microsoft Visual Studio under Windows, and XCode under Mac OS X)
The runtime code of the application
The user of the program
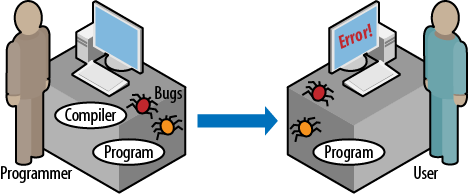
Of course, we donât want the user to see the bugs or even know about their existence, so we are left with participants 1 through 3. Like the user, programmer is human, and humans can get tired, sleepy, hungry, distracted by colleagues asking questions or by phone calls from family members or a mechanic working on their car, and so on. In short, humans make mistakes, the programmer is human, and therefore the programmer makes mistakes, a.k.a. bugs. In comparison, participants 2 and 3âthe compiler and the executable codeâhave some advantages: they do not get tired, sleepy, depressed, or burned out, and do not attend meetings or take vacations or lunch breaks. They just execute instructions and usually are very good at doing it.
Considering our resources we have to deal withâthe programmer on the one hand, and the compiler and program on the otherâwe can adopt one of two strategies to reduce the number of bugs:
Choice Number 1: Convince the programmer not to make mistakes. Look him in the eyes, threaten to subtract $10 from his bonus for each bug, or otherwise stress him out in the hopes to improve his productivity. For example, tell him something like this: âEvery time you allocate memory, do not forget to de-allocate it! Or else!â
Choice Number 2: Organize the whole process of programming and testing based on a realistic assumption that even with the best intentions and most laserlike focus, the programmer will put some bugs in the code. So rather than saying to the programmer, âEvery time you do A, do not forget to do B,â formulate some rules that will allow most bugs to be caught by the compiler and the runtime code before they have a chance to reach the user running the application, as illustrated in Figure 2.
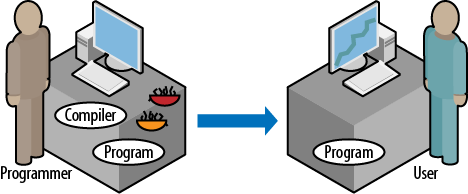
When we write C++ code, we should pursue three goals:
The program should perform the task for which it was written; for example, calculating monthly bank statements, playing music, or editing videos.
The program should be human-readable; that is, the source code should be written not only for a compiler but also for a human being.
The program should be self-diagnosing; that is, look for the bugs it contains.
These three goals are listed in decreasing order of how often they are pursued in the real programming world. The first goal is obvious to everybody; the second, to some people, and the third is the subject of this book: instead of hunting for bugs yourself, have a compiler and your executable code do it for you. They can do the dirty work, and you can free up your brain energy so you can think about the algorithms, the designâin short, the fun part.
If you have never programmed in C++, this book is not for you. It is not intended as a C++ primer. This book assumes that you are already familiar with C++ syntax and have no trouble understanding such concepts as the constructor, copy-constructor, assignment operator, destructor, operator overloading, virtual functions, exceptions, etc. It is intended for a C++ programmer with a level of proficiency ranging from near beginner to intermediate.
In Part I, we discuss the following three questions: in Chapter 1, we will examine the title question. Hint: itâs all in the family.
In Chapter 2, we will discuss why it is better to catch bugs at compile time, if at all possible. The rest of this chapter describes how to do this.
In Chapter 3, we discuss what to do when a bug is discovered at run-time. And here we demonstrate that in order to catch errors, we will do everything we can to make writing sanity checks (i.e., a piece of code written for specific purpose of diagnosing errors) easy. Actually, the work is already done for you: Appendix A contains the code of the macros which do writing a sanity check a snap, while delivering maximum information about what happened, where, and why, without requiring much work from a programmer. In Part II we go through different types of errors, one at a time, and formulate rules that would make each of these errors (a.k.a. bugs) either impossible, or at least easy to catch. In Part III we apply all the rules and code of the Safe C++ library introduced in Part II and discuss the testing strategy that shows how to catch bugs in the most efficient manner.
We also discuss how to make your program âdebuggable.â One of the goals when writing a program is to make it easy to debug, and we will show how our proposed use of error handling adds to our two friendsâcompiler and run-time codeâthe third one: a debugger, especially when it is working with the code written to be debugger-friendly.
And now we are ready to go hunting for actual bugs. In Part II, we go through some of the most common types of errors in C++ code one by one, and formulate a strategy for each, or simply a rule which makes this type of error either impossible or easily caught at run-time. Then we discuss the pros and cons of each particular rule, its pluses and minuses, and its limitations. I conclude each of these chapters with the short formulation of the rule, so that if you just want to skip the discussion and get to the bottom line, you know where to look. Chapter 17 summarizes all rules in one short place, and the Appendices contain all necessary C++ files used in the book.
At this point you might be asking yourself, âSo instead of saying, âWhen you do A, donât forget to do Bâ weâre instead saying, âWhen you do A, follow the rule Câ? How is this better? And are there more certain ways to get rid of these bugs?â Good questions. First of all, some of the problems, such as memory deallocation, could be solved on the level of language. And actually, this one is already done. It is called Java or C#. But for the purposes of this book, we assume that for some reason ranging from abundant legacy code to very strict performance requirements to an unnatural affection for our programming language, weâre going to stick with C++.
Given that, the answer to the question of why following these rules is better than the old âdonât forgetâ remonstrance is that in many cases the actual formulation of the rule is more like this:
The original: âWhen you allocate memory here, do not forget to check all the other 20 places where you need to deallocate it and also make sure that if you add another return statement to this function, you donât forget to add a cleanup there too.â
The new formulation: âWhen you allocate memory, immediately assign it to a smart pointer right here right now, then relax and forget about it.â
I think we can agree that the second way is simpler and more reliable. Itâs still not an iron-clad 100% guarantee that the programmer wonât forget to assign the memory to a smart pointer, but itâs easier to achieve and significantly more fool-proof than the original version.
It should be noted that this book does not cover multithreading. To be precise, multithreading is briefly mentioned in the discussion of memory leaks, but thatâs it. Multithreading is very complex and gives the programmer many opportunities to make very subtle, non-reproducible and difficult-to-find mistakes, but this is the subject of a much larger book.
I of course do not claim that the rules proposed in this book are the only correct ones. On the contrary, many programmers will passionately argue for some alternative practice, that may well be the right one for them. There are many ways to write good C++ code. But what I am claiming is the following:
If you follow the rules described in this book in letter and in spirit (you can even add your own rules), you will develop your code faster.
During the first minutes or hours of testing, you will catch most if not all of the errors youâve put in there; therefore, you can be much less stressed while writing it.
Finally, when you are done testing, you will be reasonably sure that your program does not contain bugs of a certain type. Thatâs because youâve added all these sanity checks and theyâve all passed!
And what about efficiency of the executable code? You might be concerned that all that looking for bugs wonât come for free. Not to worryâin Part III, The Joy of Bug Hunting: From Testing to Debugging to Production, weâll discuss how to make sure the production code will be as efficient as it can be.
The following typographical conventions are used in this book:
- Italic
Indicates new terms, URLs, email addresses, filenames, and file extensions.
Constant widthUsed for program listings, as well as within paragraphs to refer to program elements such as variable or function names, databases, data types, environment variables, statements, and keywords.
Constant width boldShows output produced by a program.
Tip
This icon signifies a tip, suggestion, or general note.
Caution
This icon indicates a warning or caution.
I believe strongly in the importance of a naming convention. You can use any convention you like, but here is what Iâve chosen for this book:
Class names are
MultipleWordsWithFirstLettersCapitalizedAndGluedTogether; for example:class MyClass {Function names (a.k.a. methods) in those classes
FollowTheSameConvention; example:MyClass(const MyClass& that); void DoSomething() const;
This is because in C++ the constructor must have the same name (and the destructor a similar name) as a class, and since they are function names in the class, we might as well make all functions look the same.
Variables have names that are
lowercase_and_glued_together_using_underscore.Data members in the class follow the same convention as variables, except they have an additional underscore at the end:
class MyClass { public: // some code private: int int_data_; };
The only exception to these rules is when we work with STL (i.e.,
Standard Template Library) classes such as std::vector. In this
case, we use the naming conventions of the
STL in order to minimize changes to your code if you decide to replace
std::vector with scpp::vector (all classes
defined in this book are in the namespace scpp). Classes such
as scpp::array and
scpp::matrix follow the
same convention as scpp::vector just because they
are containers similar to a vector.
One final remark before we start: all examples of the code in this book were compiled and tested on a Mac running Max OS X 10.6.8 (Snow Leopard) using the g++ compiler or XCode. I attempted to avoid anything platform-specific; however, your mileage may vary. I also made my best effort to ensure that the code of SafeC++ library provided in the Appendices is correct, and to the best of my knowledge it does not contain any bugs. Still, you use it at your own risk. All the C++ code and header files we discuss are available both at the end of this book in the Appendices, and on the website https://github.com/vladimir-kushnir/SafeCPlusPlus.
We have here outlined a road map. At the end of the road is better code with fewer bugs combined with higher programmer productivity and less headache, a shorter development cycle, and more proof that the code actually works correctly. Sounds good? Letâs jump in.
This book is here to help you get your job done. In general, you may use the code in this book in your programs and documentation. You do not need to contact us for permission unless youâre reproducing a significant portion of the code. For example, writing a program that uses several chunks of code from this book does not require permission. Selling or distributing a CD-ROM of examples from OâReilly books does require permission. Answering a question by citing this book and quoting example code does not require permission. Incorporating a significant amount of example code from this book into your productâs documentation does require permission.
We appreciate, but do not require, attribution. An attribution usually includes the title, author, publisher, and ISBN. For example: âSafe C++ by Vladimir Kushnir. Copyright 2012 Vladimir Kushnir, 978-1-449-32093-5.â
If you feel your use of code examples falls outside fair use or the permission given above, feel free to contact us at permissions@oreilly.com.
Note
Safari Books Online (www.safaribooksonline.com) is an on-demand digital library that delivers expert content in both book and video form from the worldâs leading authors in technology and business.
Technology professionals, software developers, web designers, and business and creative professionals use Safari Books Online as their primary resource for research, problem solving, learning, and certification training.
Safari Books Online offers a range of product mixes and pricing programs for organizations, government agencies, and individuals. Subscribers have access to thousands of books, training videos, and prepublication manuscripts in one fully searchable database from publishers like OâReilly Media, Prentice Hall Professional, Addison-Wesley Professional, Microsoft Press, Sams, Que, Peachpit Press, Focal Press, Cisco Press, John Wiley & Sons, Syngress, Morgan Kaufmann, IBM Redbooks, Packt, Adobe Press, FT Press, Apress, Manning, New Riders, McGraw-Hill, Jones & Bartlett, Course Technology, and dozens more. For more information about Safari Books Online, please visit us online.
Please address comments and questions concerning this book to the publisher:
| OâReilly Media, Inc. |
| 1005 Gravenstein Highway North |
| Sebastopol, CA 95472 |
| 800-998-9938 (in the United States or Canada) |
| 707-829-0515 (international or local) |
| 707-829-0104 (fax) |
We have a web page for this book, where we list errata, examples, and any additional information. You can access this page at:
| http://oreil.ly/SafeCPP |
To comment or ask technical questions about this book, send email to:
| bookquestions@oreilly.com |
For more information about our books, courses, conferences, and news, see our website at http://www.oreilly.com.
Find us on Facebook: http://facebook.com/oreilly
Follow us on Twitter: http://twitter.com/oreillymedia
Watch us on YouTube: http://www.youtube.com/oreillymedia
First, I would like to thank Mike Hendrickson of OâReilly for recognizing the value of this book and encouraging me to write it.
I am very grateful to my editor, Andy Oram, who received the thorny task of editing a book written by a first-time author for whom English is a second language. Andyâs editing made this book much more readable. I also appreciate his friendly way of working with an author and enjoyed our collaboration very much. I especially would like to thank Emily Quill for significantly improving the style and clarity of the text. All errors are mine.
I would like to use this opportunity to thank Dr. Valery Fradkov, who taught me programming some time ago and provided many ideas for our first programs.
I would like to thank my son Misha for his help in figuring out what the latest version of Microsoft Visual Studio is up to. And finally, I am forever grateful to my wife Daria for her support during this project.
Get Safe C++ now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

