Chapter 2. Understanding Sharding
To set up, administrate, or debug a cluster, you have to understand the basic scheme of how sharding works. This chapter covers the basics so that you can reason about what’s going on.
Splitting Up Data
A shard is one or more servers in a cluster that are responsible for some subset of the data. For instance, if we had a cluster that contained 1,000,000 documents representing a website’s users, one shard might contain information about 200,000 of the users.
A shard can consist of many servers. If there is more than one server in a shard, each server has an identical copy of the subset of data (Figure 2-1). In production, a shard will usually be a replica set.
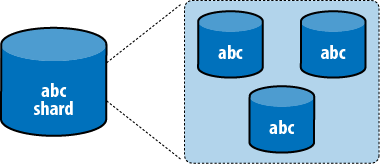
To evenly distribute data across shards, MongoDB moves subsets of the data from shard to shard. It figures out which subsets to move based on a key that you choose. For example, we might choose to split up a collection of users based on the username field. MongoDB uses range-based splitting; that is, data is split into chunks of given ranges—e.g., ["a”, “f”).
Throughout this text, I’ll use standard range notation to describe ranges. “[” and “]” denote inclusive bounds and “(” and “)” denote exclusive bounds. Thus, the four possible ranges are:
xis in (a,b)If ...
Get Scaling MongoDB now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

