Chapter 1. Known Vulnerabilities in Open Source Packages
A “known vulnerability” sounds like a pretty self-explanatory term. As its name implies, it is a security flaw that is publicly reported. However, due to the number and importance of these flaws, a full ecosystem evolved around this type of risk, including widely used standards and both commercial and governmental players.
This chapter attempts to better define what a known vulnerability is, and explain the key industry terms you need to understand as you establish your approach for addressing them.
Vulnerabilities in Reusable Products
Known vulnerabilities only apply to reusable products with multiple deployments, also referred to as third-party components. These products could be software or hardware, free or commercial, but they always have multiple instances deployed. If a vulnerability exists only within one system, there’s no value in inventorying it and making other people aware of it (except, perhaps, among attackers).
Therefore, when we speak of known vulnerabilities we’re only referring to reusable products. Because most known vulnerabilities deal with commercial products (the world of open source known vulnerabilities is a bit more nascent), the entity in charge of the product is often referred to as a vendor. In this book, because it deals with open source packages and not commercial software, I’ll refer to that entity as the owner or author of the package.
Vulnerability Databases
At the most basic level, a vulnerability is deemed known as soon as it’s publicly posted in a reasonably easy to find location. Once a vulnerability is broadly disclosed, defenders can learn about it and protect their applications, but attackers—including automated or less sophisticated ones—also get the opportunity to easily find and exploit it.
That said, the internet is a big place, and holds a lot of software. New vulnerabilities are disclosed regularly, sometimes dozens in a single day. For defenders to be able to keep up, these vulnerabilities need to be stored in a central and easy to find location. For that purpose, quite a few structured databases, both commercial and open, have been created to compile these vulnerabilities and information about them, allowing individuals and tools to query test their systems against the vulnerabilities they hold.
In addition, there are several databases that focus on vulnerabilities in open source packages, such as Snyk’s DB, the Node Security Project, Rubysec, and Victims DB. However, before digging into those, let’s review the broader and more standardized foundations of the known vulnerability database world: CVE, CWE, CPE, and CVSS.
Known Vulnerabilities Versus Zero Days
Vulnerabilities can also be known to certain parties but not be publicly posted. For instance, bad actors often find vulnerabilities in popular libraries and sell them on the black market (often called the “dark web”). These vulnerabilities are often referred to as zero-day vulnerabilities, implying zero days have passed since its disclosure.
Common Vulnerabilities and Exposures (CVE)
The most well-known body of vulnerability information is Common Vulnerability and Exposures (CVE). CVE is a free dictionary of vulnerabilities, created and sponsored by the US government, maintained by the MITRE non-profit organization. While backed by the US government, CVEs are used globally as a classification system.
When a new vulnerability is disclosed, it can be reported to MITRE (or one of the other CVE Numbering Authorities), which can confirm the issue is real and assign it a CVE number. From that point on, the CVE number can be used as a cross-system identifier of the this flaw, allowing for easy correlation between security tools. In fact, most vulnerability databases will hold and share the CVE even when maintaining their own ID for the given vulnerability.
It’s important to note that CVE is not itself a database, but rather a dictionary of IDs. To help automated systems access all CVEs, the US government also backs the National Vulnerability Database (NVD). NVD is a database, and exposes the vulnerability information through the standardized Security Content Automation Protocol (SCAP).
CVE is a pretty messy list of vulnerabilities, as it applies to systems of an extremely wide variety. To help keep it consistent and usable for its consumers, MITRE established various guidelines and policies around content and classification. The three most noteworthy ones, at least for the world of OSS libraries, are CPE, CWE, and CVSS.
Common Platform Enumeration (CPE)
In addition to the vast number of vulnerabilities they represent, CVEs also indicate flaws in extremely different products. In an attempt to make it easier for you to discover if a given CVE applies to your products, NVD can amend each CVE with one or more Common Product Enumeration (CPE) fields. A CPE is a relatively lax data structure that describes the product name and version ranges (and perhaps other data) this CVE applies to. Note that CPEs are not a part of CVE, but rather a part of NVD. This means a known vulnerability will not have product info unless it makes it to NVD, which doesn’t always happen (more on that later on).
CPEs are a powerful idea, and can enable great automated discovery of vulnerabilities. However, defining a product in a generic way is extremely hard, and the content quality of many CVEs is lacking. As a result, in practice CPEs are very often inaccurate, partial, or simply not automation-friendly enough to be practical. Products that rely heavily on CPEs, such as the OWASP Dependency Checker, need to use fuzzy logic to understand CPEs and fail when content is lacking, leading to a large number of false positives and false negatives.
To address this gap, most commercial vulnerability scanners and databases in the OSS libraries space only use CPEs as a starting point, but maintain their own mappings of a CVE to the related products.
Common Weakness Enumeration (CWE)
While every vulnerability is its own unique snowflake, at the end of the day most vulnerabilities fall into a much more finite list of vulnerability types. MITRE classifies those types into the Common Weakness Enumeration (CWE) list, and provides information about each weakness type. While CWE items can get pretty specific (e.g., CWE-608 represents use of a non-private field in Struts’ ActionForm class), its broader categories are more widely used. For instance, CWE-285 describes Improper Authorization, and CWE-20 represents the many variants of Improper Input Validation. CWEs are also hierarchal, allowing a broader scope CWE to contain multiple narrower scope ones.
The smaller number of CWEs makes it more feasible to provide rich detail and remediation advice for each item, or define policies based on a vulnerability type. Each CVE is classified with one or more CWEs, helping its consumers focus on the CWEs they’re most interested in and removing the need to repeat CWE-level information for each associated CVE.
Common Vulnerability Scoring System (CVSS)
Vulnerabilities are disclosed on a regular basis, and at a rather alarming pace, but not all of them require dropping everything and taking action. For instance, leaking information to an attacker is not as bad as allowing them to remotely execute commands on a server. In addition, if a vulnerability can be exploited with a simple HTTP request, it’s more urgent to fix than one requiring an attacker to modify backend files.
That said, classifying vulnerabilities isn’t easy, as there are many parameters and it’s hard to judge the weight each one should get. Is access to the DB more or less severe than remote command execution? If this execution is done as a low-privileged user, by how much should that reduce its severity score compared to an exploit performed as root? And how to judge an exploit requiring a long sequence of requests, but that can be accomplished with a tool downloaded from the web?
On top of all of those, the severity of an issue also depends on the system on which it exists. For example, an information disclosure vulnerability is more severe on a bank’s website than it is on a static news site, and a vulnerability that requires physical machine access matters more to an appliance than to a cloud service.
To help tackle all of these, MITRE created a Common Vulnerability Scoring System (CVSS). This system is currently at its third iteration, so you’re likely to see references to CVSSv3, which is the version discussed here. CVSSv3 breaks up the scoring into three different scores, each of which are split into several smaller scores:
- Base
-
Immutable details about a vulnerability, including the attack vector, exploit complexity, and impact it could have.
- Temporal
-
Time-sensitive information, like the maturity of exploit tools out there or ease of remediation.
- Environmental
-
Context information for the vulnerable system, such as how sensitive it is or how is it accessible.
Figure 1-1 shows the variables and calculation of a CVSSv3 score for a sample vulnerability (the calculation was generated using FIRST.org’s online tool).
While all three scores matter, public databases typically show CVSS scores based only on the Base component. The constant change in the Temporal score makes it costly to maintain, and the Environmental score is, by definition, specific to each vulnerability instance. Still, users of these databases can fill in those two scores, adjust the weights as they see fit, and get a final score.
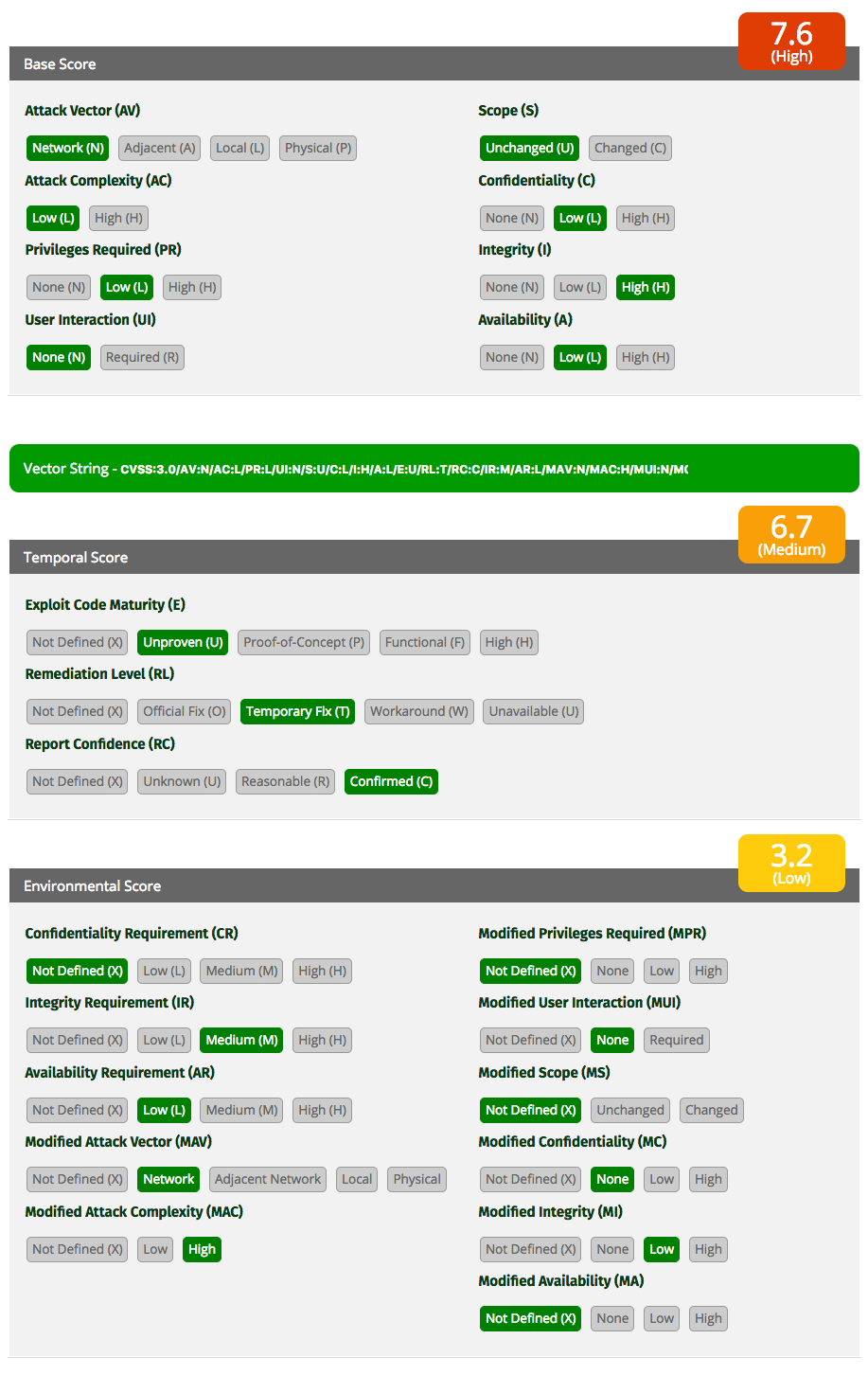
Figure 1-1. A completed CVSSv3 score
Known Vulnerabilities Outside CVE and NVD
Having a CVE is helpful, but it’s also a hassle. Receiving a CVE number requires the author or reporter to know about it in the first place, and then go through a certain amount of paperwork and filing effort. Finally, CVEs need to be approved by specific CVE Numbering Authorities (CNA), which takes time. As a result, while CVEs are the norm for vulnerabilities in certain types of systems (e.g., network appliances), they’re not that common in other worlds.
CVEs are in especially bad shape when it comes to known vulnerabilities in OSS packages. Based on a Snyk’s database as of October, 2017, only 67% of Ruby gem vulnerabilities have a CVE assigned, and a meager 11% of npm package vulnerabilities have such an ID.
One reason for this gap is the fact many library vulnerabilities are reported by developers, not security researchers, and communicated as bugs. Such issues are often fixed quickly, but once fixed the author and reporter rarely go through the CVE process. Even when they do, the assignment of the CVE lags far behind, while attackers may be exploiting the vulnerability now made known.
Yet another lag takes place between the assignment of a CVE and posting it to NVD, providing more detail and perhaps CPEs. Such delays are expected when a new vulnerability reserves a number while it’s going through a responsible disclosure process, but the lag often happens after the vulnerability is known.
This lag is very evident when looking at vulnerable Maven packages: 37% of Maven package vulnerabilities that have a CVE were public before being added to NVD, and 20% of those were public for 40 weeks or more before being added.
Known vulnerabilities that are not on NVD are still known, but harder to detect. Library vulnerabilities are likely to either have no CVE, not be listed on NVD (and thus have no advisory or CPE), or have poor-quality CPEs. Each of those would prevent their detection by tools that rely exclusively on these public data sources, notably OWASP Dependency Checker.
Using CWE and CVSS Without CVE
While CVE, CWE, and CVSS are all MITRE standards, they can be used independently of one another. CWE and CVSS are often used for vulnerabilities that have no CVE, offering standardized classification and severity even if there is no industry-wide ID.
Unknown Versus Known Vulnerabilities
Every known vulnerability was at some point unknown. This may seem obvious, but it’s an important point to understand—a new known vulnerability is not a new vulnerability but rather a newly disclosed one. The vulnerability itself was already there before it was discovered and reported. However, while disclosing a vulnerability doesn’t create it, it does change how it should be handled, and how urgently it should be fixed.
For attackers, finding and exploiting an unknown vulnerability is hard. There are endless potential attack variants, which need to be invoked quickly while avoiding detection. Determining if an attack succeeded isn’t always easy either, implying a submitted payload might have successfully gone through while the attacker remains none the wiser.
Once a vulnerability is disclosed, exploiting it becomes far easier. The attacker has the full detail of the vulnerability and how it can be invoked, and only needs to identify the running software (a process called fingerprinting) and get the malicious payload to it. This process is made even easier through automated exploit tools, which enumerate known vulnerabilities and their exploits. This automation also lowers the barrier to entry, allowing less sophisticated attackers to attempt penetration.
Known vulnerabilities are largely considered to be the primary cause for successful exploits in the wild. To quote two sample sources, Verizon stated “Most attacks exploit known vulnerabilities that have never been patched despite patches being available for months, or even years”, and Symantec predicts that “Through 2020, 99% of vulnerabilities exploited will continue to be ones known by security and IT professionals for at least one year”. On the application side, analyst firms such as Gartner and RedMonk have repeatedly stated the critical importance of dealing with known vulnerabilities in your open source libraries.
Known vulnerabilities should therefore be handled urgently. Even though it’s the same vulnerability, its disclosure makes it much more likely attackers would use it to access your system. The disclosure of a vulnerability triggers a race, seeing whether a defender can seal the hole before an attacker can go through it. Figure 1-2 shows attackers response to the disclosure of the severe Struts2 vulnerability mentioned earlier, ramping from zero attacks to over a thousand observed attacks per day in a couple of days.
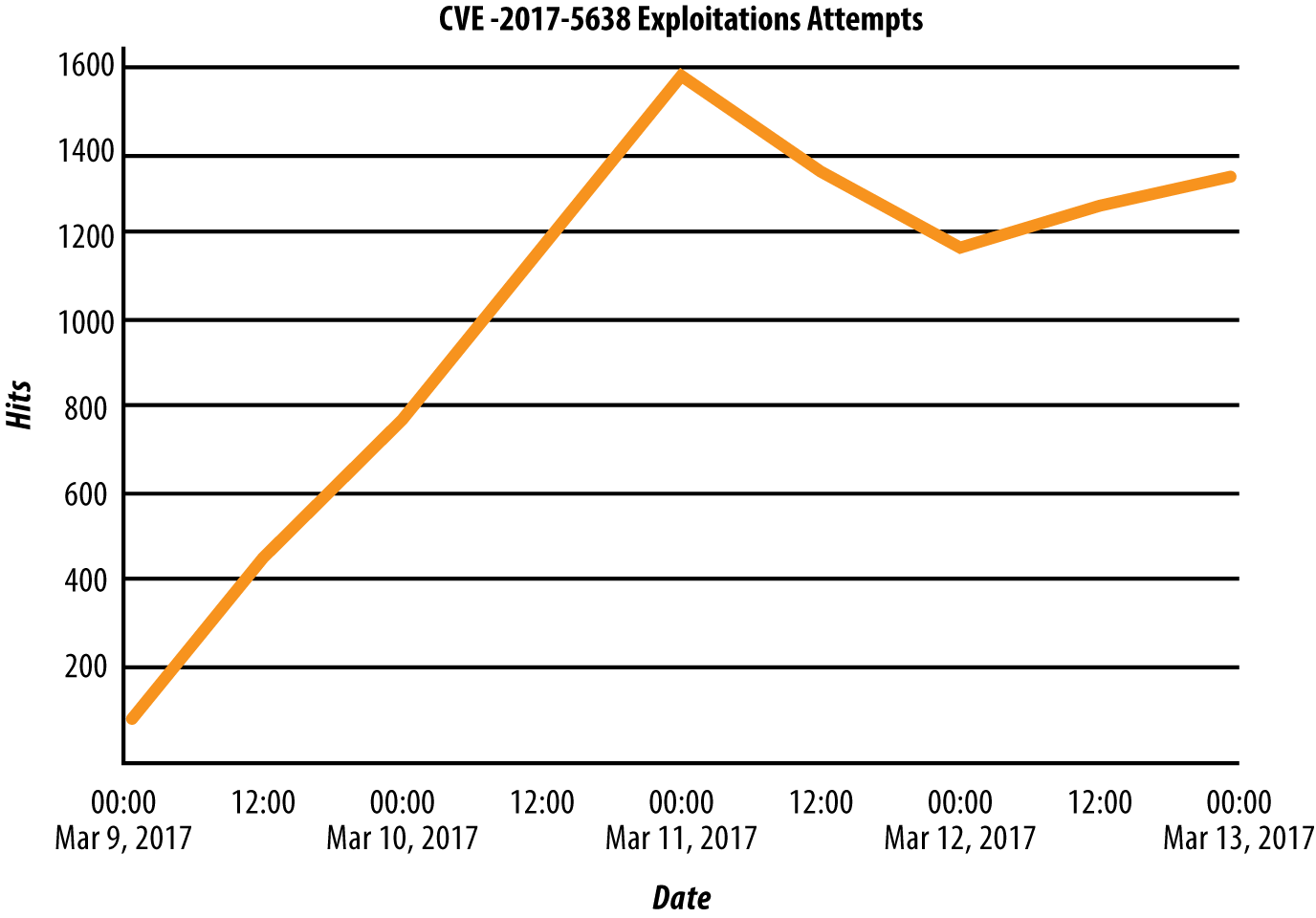
Figure 1-2. Daily exploitation attempts of the Struts vulnerability disclosed on March 9th kicked in immediately
The good news is that known vulnerabilities are also easier to defend against than unknown ones. Typically a known vulnerability also has a known solution, often in the form of a software upgrade or patch. Even if no software solution exists, you should at least have a better understanding of how to detect attacks and keep them from getting through with your security controls. As I’ll discuss in Chapter 5, it’s important to invest in systems that let you learn about such disclosures quickly and to act on them faster than the bad actors will.
Responsible Disclosure
So far I talked about a disclosure as a single point in time, when in fact it shouldn’t be so binary. The right way to disclose a vulnerability, dubbed responsible disclosure, involves several steps that aim to give defenders a head start in the mentioned race.
Understanding responsible disclosure is not critical for open source consumers, but it is very important for open source authors. To learn more about responsible disclosure, you can read Tim Kadlec’s excellent blog post, or look at Snyk’s responsible disclosure template.
Summary
Known vulnerabilities are not as simple as they initially appear. The definition of what’s considered known and the management of the vulnerability metadata are very hard to do well.
CVE and NVD work well for curating vulnerabilities in commercial products, but do not scale to the volume and ownership model of open source projects. Over time, these standards may evolve to meet this demand, but right now their coverage and detail level are not enough to protect your libraries.
Get Securing Open Source Libraries now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

