Chapter 1. Introduction to DevSecOps
We did not start our careers in security, but we both know that delivering software is of utmost importance to developers. “Delivering software” in this context means delivering something that does what it is supposed to do. This could refer to the code being stable, or the software meeting the functional requirements (for example, a calculator can add, multiply, subtract, and divide numbers) and performance expectations without any issues (for example, a chat application allows more than 10 people to send messages to each other simultaneously).
Building quality software, however, requires good coding practices, resilient architectures, and security. It’s common for security to be added into the software after it has been built, but the shift-left approach recommends moving security to much earlier in the development life cycle, building it in from the start. We will discuss that approach in this chapter, focusing on Security as Code (SaC). In this approach, our infrastructure’s security policies—detection, prevention, remediation—are all defined as code.
We will also discuss DevSecOps in this chapter, focusing on the three major players in software development:
- Development
- Is your code doing what it is meant to do?
- Operations
- What is this code running on? Do you have the required skills/time to maintain this going forward? Can the provisioned infrastructure handle the expected workload?
- Testing
- Can the code survive unexpected use cases? How does the code respond to something you didn’t account for?
The primary focus of this book is how to integrate security into your development process through cloud infrastructure. Declaring infrastructure in files is also known as Infrastructure as Code (IaC). Kief Morris provides a helpful definition in his book Infrastructure as Code, 2nd edition (O’Reilly):
Infrastructure as Code is an approach to infrastructure automation based on practices from software development. It emphasizes consistent, repeatable routines for provisioning and changing systems and their configuration. You make changes to code, then use automation to test and apply those changes to your systems.
Using IaC and declaring the security aspects of that infrastructure is Security as Code (SaC). SaC is not entirely different from IaC, but rather focuses on enabling security controls using templates.
This chapter introduces the basic concepts of SaC, and Chapter 2 provides setup and instructions to get you started. After that, the chapters are organized by security domains. Some chapters are exclusive to a single domain; others address multiple domains in a single stage of the buildout. Each domain has its own unique set of questions. For instance:
- Data protection (Chapter 3)
- Is everything encrypted? Does the encryption approach follow data classification policies? Do we have data classification implemented?
- Infrastructure security (Chapter 3)
- As we are running our application in the cloud, is all the infrastructure deployed securely? Is our S3 bucket publicly accessible when it should not be? Can we prevent deployment of our resources when something is missing?
- Application security (Chapter 3)
- Is the code we’re running secure? How many active vulnerabilities are there in our code? Did we release code with a critical vulnerability?
- Logging and monitoring (Chapter 4)
- Do we know what to monitor? When does an observation become an anomaly? Are the right application security indicators in place to inform us of any mishap?
- Identity and access management (Chapter 5)
- Who has access to what? Does anyone have any elevated privileges? Can someone elevate their own or others’ privileges?
- Incident response (Chapter 6)
- How do we react to incidents? Can we replace part of the offending application when something goes wrong?
Throughout the chapters, we will use Amazon Web Services (AWS) native security services and best practices to baseline the environment we are deploying. When we assume certain operational and team structures, we explicitly call out those assumptions.
Before DevOps: The Software Development Life Cycle
When you are new in your career, writing a piece of code that does exactly what was asked is a joy of its own. With time, however, we’ve realized writing quality code does not stop at making 2 + 2 = 4. What if the user enters “2 + a”? How should your software behave?
Well, that’s the responsibility of the Quality and Testing engineers, isn’t it? Wrong.
We’ve seen back-and-forth between developers and testers that was time-consuming and created unhealthy expectations from both teams. Let’s take the example of the calculator input of “2 + a”. If, as a coder, you did not think of this use case because it was not part of the requirements, and your tester or QA team did not record it as a test case, you would be shipping broken code to your customers. This broken code would be your final product. A codebase that doesn’t work as expected is not a joy for the end user to work with.
Code needs to be hosted on some infrastructure to be built and deployed. Is it going to run on a server in your datacenter, on a virtual machine in the cloud, on a container, or on someone’s laptop? Depending on your answer, you have another set of responsibilities related to infrastructure. Once you set up your infrastructure, you will need to answer a new series of questions, including:
-
Are the coders developing this on the exact same platform on which it will be deployed?
-
Who is setting up all the infrastructure?
-
Does the infrastructure fail open or fail safe, in the case of an error?
That set of questions needs another set of tests to make sure that the application code is being run correctly on the right platform, and that the platform is not misbehaving.
In traditional software development, only developers take care of development, which means their prime directive is writing code to a specification. The operations team handles the environment and method of deployment, and the change management procedures. Testers take the output of the developers and the operations team and make sure the near-final product does not break. These three roles are not mutually exclusive, but each team needs to wait for input from the previous team to start its work.
A very common representation of this flow is the Software Development Life Cycle (SDLC) model (see Figure 1-1). In practice, the waterfall model of the SDLC might operate something like this: developers create code quickly, based on functional requirements. The code is sent for testing, errors are found, and the code is sent back to developers. The developers fix the code and send it for another round of testing. Once the testing is complete, the code is handed off to the operations team for maintenance.
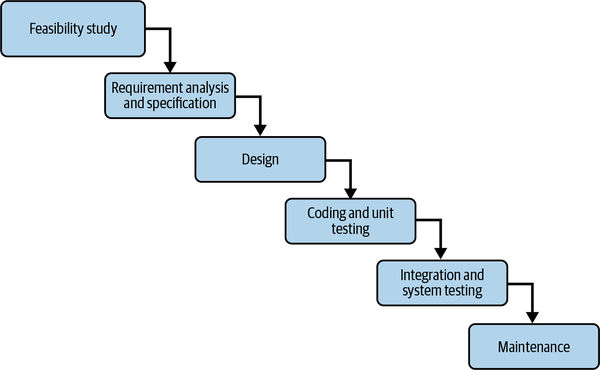
Figure 1-1. Software Development Life Cycle: waterfall model (https://oreil.ly/KtVv0)
Siloed teams operating in a hands-off style, similar to the SDLC in Figure 1-1, have their disadvantages. Each team has its own toolset and handles a very specific piece of the SDLC, and is typically unaware of the toolsets of the other teams. This makes it difficult to get quality software out the door on time.
The waterfall model leads to a lot of back-and-forth between teams, as we’ve noted. The back-and-forth is made worse when you have not delivered anything because your code has not passed your testing teams. So, a whole lot of time and effort is lost without producing any tangible outcomes.
Enter DevOps. In order to reduce time to market and improve the quality of software, the concept of DevOps was introduced. In their book Effective DevOps (O’Reilly), authors Jennifer Davis and Ryn Daniels define DevOps as:
A cultural movement that changes how individuals think about their work, values the diversity of work done, supports intentional processes that accelerate the rate by which businesses realize value, and measures the effect of social and technical change. It is a way of thinking and a way of working that enables individuals and organizations to develop and maintain sustainable work practices. It is a cultural framework for sharing stories and developing empathy, enabling people and teams to practice their crafts in effective and lasting ways.
In a DevOps model, the development, testing, and operations teams don’t work in silos, but are the same group. If we were to visualize the DevOps model, it would look like a homogeneous blob of roles. Kief Morris writes in Infrastructure as Code that the goal of DevOps is:
To reduce barriers and friction between organizational silos—development, operations, and other stakeholders involved in planning, building, and running software. Although technology is the most visible, and in some ways simplest face of DevOps, it’s culture, people, and processes that have the most impact on flow and effectiveness. Technology and engineering practices like Infrastructure as Code should be used to support efforts to bridge gaps and improve collaboration.
We want to emphasize this point: DevOps is not solely enabled by technology. It is effective only when people, processes, and technology are working together. There is a common misconception that if you use tools that are used in CI/CD systems, you’re automatically practicing DevOps. This is flawed thinking. What enables DevOps is collaboration.
What Is DevSecOps?
DevSecOps is not a “new version” of DevOps, but rather a conscious effort to add security into your DevOps framework. Like with DevOps, there are numerous definitions of and approaches to DevSecOps. For the purposes of this book, we define DevSecOps as the ability to implement and deploy SaC in software.
We will be leaning heavily on APIs, cloud services, and other open source projects to implement SaC. When a part of your SDLC becomes “as code,” your team should have the openness to build things.
As your organization begins to implement DevSecOps, there are two important things your team will need to outline: tools and security guidelines.
First, how will you write your IaC? In other words, what tools will you use? This could be a tool like AWS CloudFormation or Terraform. There are numerous services and products available from vendors and the open source community that you can use to build and integrate SaC into your pipeline. As we mentioned, this book will use AWS and open source projects to demonstrate the why and how of doing DevSecOps, instead of fixating on a particular tool’s licensing or procurement. We chose to focus on AWS in this book since it is currently the most popular cloud infrastructure vendor, controlling 33% of the market. However, the book’s underlying principles will be useful to all readers.
Second, what are your company’s security “rules of the road”? What has your security team designated as “definitely don’t do this” rules? Understanding why the security team provides certain guidance helps you understand the concerns underlying the rules.
In DevSecOps, you are building security directly into your software development pipeline (see Figure 1-2). In step 1, the developer lints their code locally and makes sure its formatting follows the team’s conventions and standards. They then commit the code to the repository. In step 2, the build system of the pipeline scans for errors and any other vulnerabilities and misconfigurations. The security of the pipeline is built into this stage. Finally, in step 3, the code is (possibly) ready for deployment. The last hurdle is a decision gate—a mechanism that checks for errors. If any errors are found, deployment is canceled and the developer is informed. If the code has no errors, the deployment goes through.
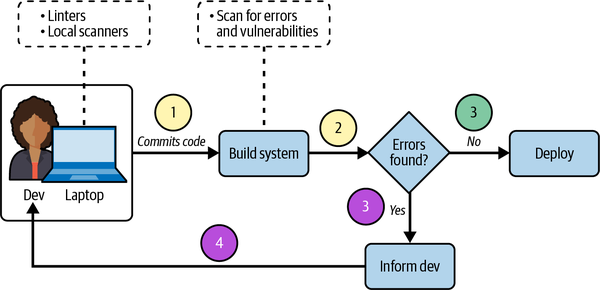
Figure 1-2. Building security into a DevOps pipeline
Steps 1 and 2 happen every time. The top version of step 3 only occurs when the linters and scanners discover no errors. Both the lower version of step 3 and step 4 only occur when the linters and scanners discover an issue.
The code that is deployed is not the only thing that needs to be secured. You also need to protect the security checks you are implementing within the DevOps pipeline. Imagine for a moment that anyone who commits code can turn security checks on and off. Would it be secure?
We have seen teams bypass their security checks because an “urgent” code change was needed and it was faster to deploy without security. That is a recipe for disaster. Situations where a real emergency justifies a nonsecured code change should be recorded and remediated. There should not be a bypass function for deployments.
Introducing Automatoonz
Security is a broad topic. Its subfields include physical security, application security, cryptography, training, and many more. We will limit our scope in this book to a subset of security domains, which we’ll explore by following the journey of an imaginary company we’ll call Automatoonz.
Automatoonz is an animation company that’s recently been getting into web toons and series creation. The company operates on AWS and is currently trying to build security into its development and deployment processes. It wants to be lean and secure, but the company is relatively new in the space and doesn’t have the funding to hire more security engineers. Thus, its aim is to automate as much security as possible.
Because Automatoonz operates on AWS, there are some security responsibilities it doesn’t have to worry about, such as physical security. AWS refers to this as the shared responsibility model.
Cloud Infrastructure: Secure by Default
In cloud infrastructure, every resource is created through an API call. Each API call has parameters that configure your resource exactly as you want it. The software development kit (SDK) you use will also automatically generate a default configuration, to provide maximum customization options.
For example, if you are using the AWS SDK for Python (Boto3) to create an Amazon S3 bucket, the only required parameter is a name for the bucket. The SDK does not ask you for encryption, nor does it require you to ensure the bucket is not publicly accessible. If you want to enforce encryption on the contents of the bucket, you should do so upon deployment. This is what is referred to as Secure by Default.
Secure by Default does not mean you should lock down everything you possibly can. It’s often said that the safest computer system is the one that’s unplugged. But, if you make your system so secure that it’s practically unusable—well, people won’t use it. They’ll look for workarounds, potentially compromising security in the process. In this book, we aim to demonstrate usable security—a balance between usability and security.
In an IaC paradigm, you can templatize your resources—make declarative code for patterns you come across and create templates that developers can work from, in order to keep the codebase consistent. For example, if you are building a web server within AWS, you should be able to standardize the architecture for future deployments. If the architecture is defined only in a diagram, you’ll need to codify that diagram as IaC. To do so, you’ll need to create declarative templates so that the same web server pattern can be deployed repeatedly with zero deviation.
What does templatization provide in terms of security? Let’s revisit the S3 bucket example. At Automatoonz, the legal team is tasked with ensuring that all of the company’s data is encrypted at rest, meaning that data stored in any persistent storage has to be encrypted through a cryptographic key, which is only accessible to authorized users. In cloud computing, you can define encryption at rest through API flags in your IaC templates. This also helps standardize a Secure by Default posture for your infrastructure.
Of course, the legal team informs the developers of this requirement, and the developers need to apply the right checks and balances to adhere to the policy. If there is an IaC template for the bucket, the developers must check it before it is sent to AWS endpoints for resource creation. This will prevent the unencrypted bucket from ever being created.
At a very high level, Figure 1-3 shows what we are trying to achieve. The developer on the left creates an AWS CloudFormation template, which in turn creates an S3 bucket. This goes to a decision gate. If encryption is not enabled, the decision gate shuts down deployment. Only after the template is fixed can the deployment go through.
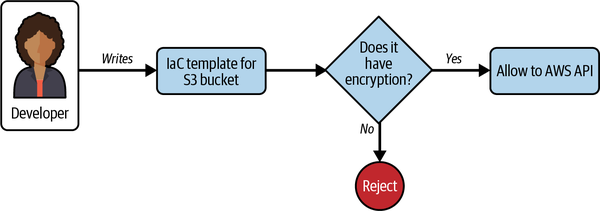
Figure 1-3. Decision gate that rejects unencrypted S3 bucket templates
Move Fast, Secure Fast: The Importance of Automation
When you drive a car, there are certain rules of the road that you must obey. Not adhering to these rules can lead to mishaps, serious accidents, and legal trouble. In security, we have similar invariable rules. Sometimes the rules are driven by regulatory or compliance requirements; other times they’re intended to create engineering excellence. Regardless of the reason, every team is expected to follow these rules.
How can developers ensure they consistently follow rules related to security? Recall our earlier discussion of IaC, and its ability to define cloud resources in a declarative manner. Herein lies our answer. If we can set predictable flags and/or parameters for cloud resources, we can allow operations such as creating new resources or deploying new code to go through only if certain things are present.
When you want to move at the speed of the cloud, you want to secure things at the speed of the cloud as well. This means automating as much of your security as possible. There is a manual way of doing the check shown in Figure 1-3, in which the developer looks at their code and prevents a misconfiguration. But remember the old adage, “Humans are the weakest link in security”? You ideally want to automate these checks. To automate a security check—a central idea in DevSecOps—there are certain attributes to consider:
- Idempotence
- The security check should yield the same results no matter how many times you pass the template in question.
- Baseline
- The security check should apply to all or most resources. If a security check only applies to one variant of a resource, which appears in less than 30% of your deployments, you will get a lot of noise and failures while doing the check.
- Recommendation
- You found a security misconfiguration. That’s cool, but did you tell the build system what to do? If you leave your end users without a fix, you are adding to their work. Your scans should recommend fixes when a misconfiguration is found.
We will be using these attributes as we build our pipeline throughout the book. One thing we want to reiterate: automation does not solve everything. Without the right owners and processes, all the automation in the world will not amount to anything. These security checks need to be maintained, and the developer should give feedback to improve efficiency.
DevSecOps Culture
Technology is not a silver bullet. Culture plays a role, too. DevOps at its core is built on a culture, and its tools are only useful when people use them in the right ways.
We have seen organizations acquire every possible tool that claims to solve security issues, yet not even configure half of them. Why aren’t the teams using these security tools? Do they lack training? Are the tools overkill, or too expensive to roll out to the entire organization?
We highly recommend answering one simple question before you buy any security tool: What security problem are you trying to solve? Answers like “make things secure” and “improve my security” are as vague as it gets. Try to boil it down to a single sentence. If that doesn’t give you a clear answer, consider writing a risk statement. A risk statement looks something like this:
- Lack of X leads to loss of Y because of Z.
-
X = a security function, like access control or logging
-
Y = the impact if your security control is not implemented (i.e., what is at stake?)
-
Z = how your security control prevents a security event
We won’t go into detail on procurement, but it is crucial to understand what security problem a tool is meant to solve before buying it. A lot of enterprise-grade tools offer free trials or demos. If your team has a builder mindset, you may want to explore the vast expanse of open source cloud security tools, many of which have made their mark in the industry and continue to get better.
Once you’ve selected a tool, who will maintain it? Will it need to be updated regularly? Your tool should have a clear owner on the operational side. Let’s say you get a cloud security posture management (CSPM) tool, and the security team has integrated every cloud account to be ingested. The security team receives alerts from the accounts, but takes no action because it expects the cloud account owner to act on those alerts. But the cloud account owner thinks the security team is handling it. Without a clear process for addressing the alerts, the teams have no plan of action. Simple tools like responsibility assignment matrices (or RACI charts) and runbooks can take care of this. We discuss these tools in more detail in Chapter 7.
Summary
Now that we have introduced DevSecOps and clarified the scope of the book, let’s start implementing DevSecOps into our pipeline!
The subsequent chapters will begin by setting up the infrastructure for Automatoonz and iteratively building security capabilities into the application development process. We will primarily focus on the technology and tooling, but we will call out any people and process must-haves, derived from our experience.
A quick recap of key takeaways from this chapter:
-
DevSecOps is a variant of DevOps that includes security in its iterative DevOps model.
-
If you can prevent misconfigured resources from being created, you can create security hygiene and educate developers.
-
Automating security checks requires idempotence, baselines, and recommendations. Chapters 3 and 4 address this topic in more detail.
-
Automating security checks alone will not solve security problems. Establish people and processes to own and operate the automation.
-
Establish why you’re implementing a security tool before rolling it out.
Get Security as Code now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

