May 2025
Intermediate to advanced
456 pages
5h 50m
Chinese
本作品已使用人工智能进行翻译。欢迎您提供反馈和意见:translation-feedback@oreilly.com
本章是对生成式建模领域的一般性介绍。
我们将首先从理论上温和地介绍生成建模,并了解生成建模是如何与更广泛研究的判别建模自然对应的。然后,我们将建立一个框架,描述一个好的生成模型应具备的理想特性。我们还将阐述必须了解的核心概率概念,以便充分理解不同方法如何应对生成模型的挑战。
这将自然而然地引导我们进入倒数第二部分,该部分列出了当今该领域占主导地位的六大生成模型系列。最后一节将介绍如何开始使用本书附带的代码库。
生成模型可大致定义如下:
生成模型是机器学习的一个分支,它涉及训练一个模型,以生成与给定数据集相似的新数据。
这在实践中意味着什么?假设 ,我们有一个包含马匹照片的数据集。我们可以在这个数据集上训练一个生成模型,以捕捉支配马匹图像中像素间复杂关系的规则。然后,我们可以从该模型中提取样本,创建出原始数据集中不存在的新颖、逼真的马匹图像。图 1-1 展示了这一过程。
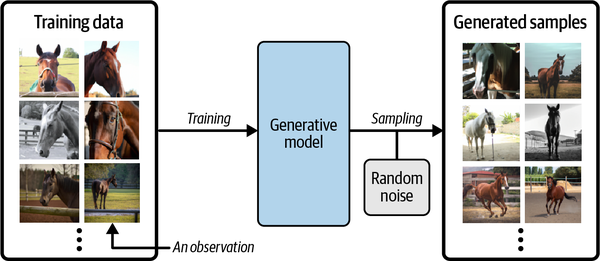
为了建立一个生成模型,我们需要一个由我们试图生成的实体的许多示例组成的数据集。 称为训练数据,其中一个数据点称为观测点。
每个观测结果都包含许多特征。对于图像生成问题,特征通常是单个像素值;对于文本生成问题,特征可能是单个单词或字母群。我们的目标是建立一个模型,它能生成新的特征集,这些特征集看起来就像使用与原始数据相同的规则创建的一样。从概念上讲,对于图像生成来说,这是一项非常困难的任务,因为单个像素值的分配方式非常多,而构成我们试图生成的实体图像的这种排列方式相对较少。
生成式模型还必须是概率性的,而不是确定性的,因为我们希望能够对输出的多种不同变化进行采样,而不是每次都得到相同的输出。如果我们的模型仅仅是一种固定的计算,比如取训练数据集中每个像素的平均值,那么它就不是生成式模型。 生成模型必须包含随机成分,以影响模型生成的各个样本。
换句话说,我们可以想象存在某种未知的概率分布,它解释了为什么某些图像可能出现在训练数据集中,而另一些图像则不可能。我们的工作就是建立一个尽可能接近这种分布的模型,然后从中采样,生成新的、独特的观察结果,这些观察结果看起来就像是原始训练集中的观察结果。
Read now
Unlock full access






