Chapter 22. Addressing Cascading Failures
If at first you don’t succeed, back off exponentially.
Dan Sandler, Google Software Engineer
Why do people always forget that you need to add a little jitter?
Ade Oshineye, Google Developer Advocate
A cascading failure is a failure that grows over time as a result of positive feedback.1 It can occur when a portion of an overall system fails, increasing the probability that other portions of the system fail. For example, a single replica for a service can fail due to overload, increasing load on remaining replicas and increasing their probability of failing, causing a domino effect that takes down all the replicas for a service.
We’ll use the Shakespeare search service discussed in “Shakespeare: A Sample Service” as an example throughout this chapter. Its production configuration might look something like Figure 22-1.
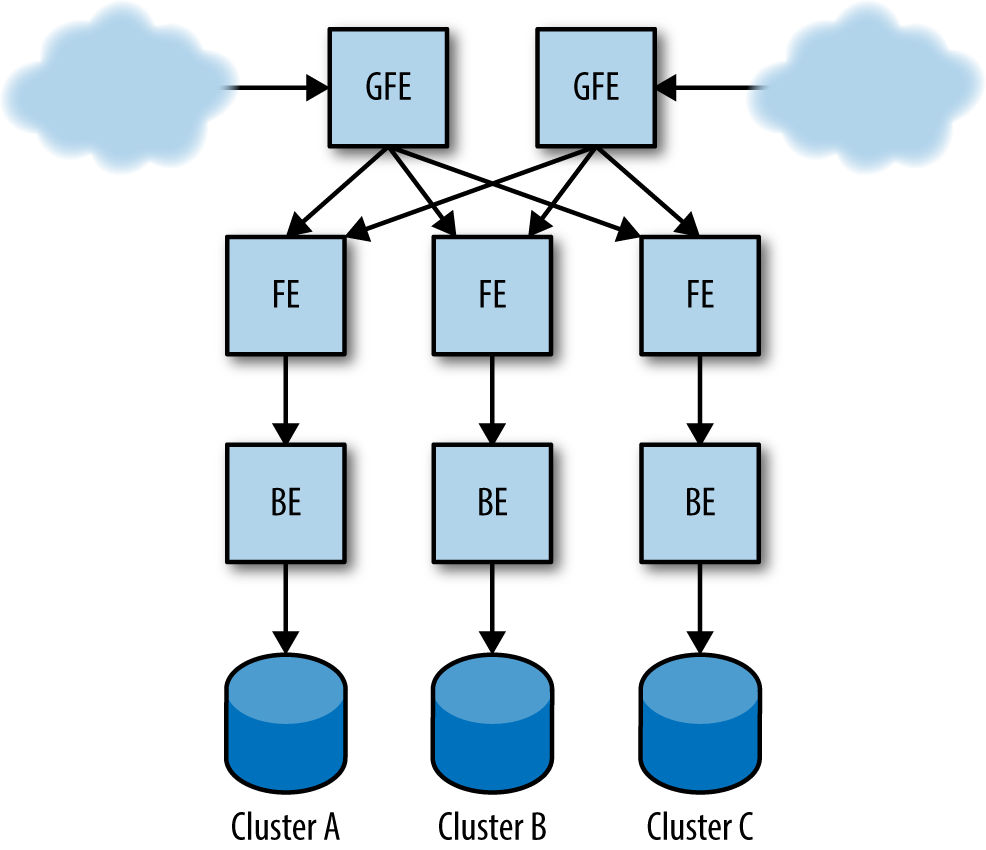
Figure 22-1. Example production configuration for the Shakespeare search service
Causes of Cascading Failures and Designing to Avoid Them
Well-thought-out system design should take into account a few typical scenarios that account for the majority of cascading failures.
Server Overload
The most common cause of cascading failures is overload. Most cascading failures described here are either directly due to server overload, or due to extensions or variations of this scenario.
Suppose the frontend ...
Get Site Reliability Engineering now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

