May 2024
Beginner to intermediate
549 pages
8h 11m
Chinese
在这一章中,我们将讨论以下内容:
无监督机器学习是一种尝试从一组未打标的观察样本中直接或间接(通过隐因子)获取推断的技术。简单来说,无监督机器学习技术试图从一组数据中发现隐藏的知识或结构,无须对训练数据打标。
当用于大型数据集(迭代、来回反复计算、大量的中间写操作)时,大多数机器学习库会崩溃失效,借助于并行和大规模数据集的设计特性,Apache Spark机器学习库将中间数据写入内存,从而能够处理大型数据集。
从更抽象的层面来说,无监督学习可以划分几个部分。
图8-1展示了机器学习技术的整个框架。前面的章节重点关注了监督机器学习技术,在本章将重点关注使用Spark ML/MLLIB库的无监督机器学习技术,包括聚类和隐因子模型。
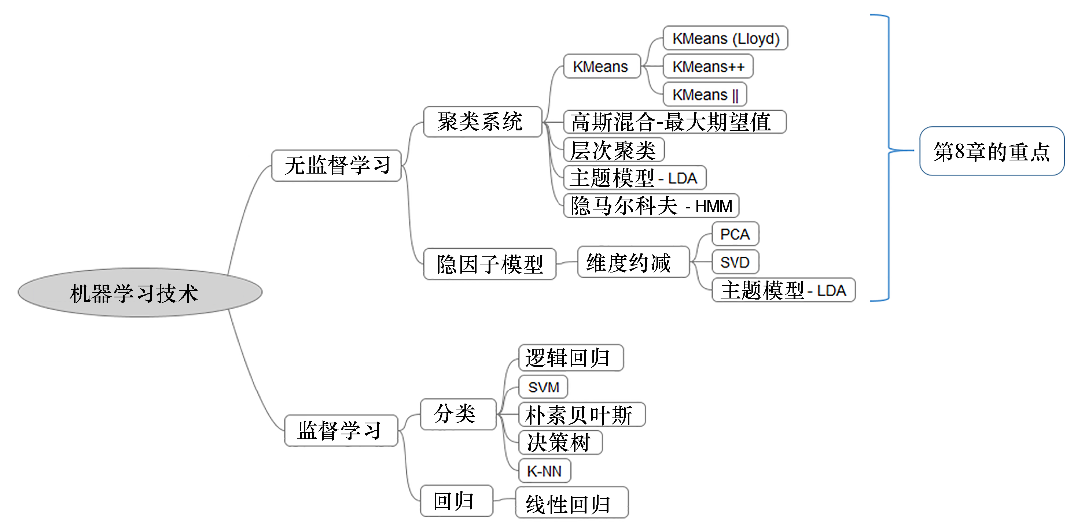
图8-1
通常使用类蔟内的相似性测量指标对类簇建模,例如使用欧式距离或概率。Spark提供了一套完整、高性能的算法,可以实现大规模的并行。Spark不仅提供API,还提供了完整的源代码,非常有助于开发者理解性能瓶颈和解决个性化的需求(如衍生到GPU)。 ...
Read now
Unlock full access






