Chapter 4. Redeploying Batch Models in Real Time
For all the greenfield opportunities to apply machine learning to business problems, chances are your organization already uses some form of predictive analytics. As mentioned in previous chapters, traditionally analytical computing has been batch oriented in order to work around the limitations of ETL pipelines and data warehouses that are not designed for real-time processing. In this chapter, we take a look at opportunities to apply machine learning to real-time problems by repurposing existing models.
Future opportunities for machine learning and predictive analytics span infinite possibilities, but there is still an incredible amount of easily accessible opportunities today. These come by applying existing batch processes based on statistical models to real-time data pipelines. The good news is that there are straightforward ways to accomplish this that quickly put the business rapidly ahead. Even for circumstances in which batch processes cannot be eliminated entirely, simple improvements to architectures and data processing pipelines can drastically reduce latency and enable businesses to update predictive models more frequently and with larger training datasets.
Batch Approaches to Machine Learning
Historically, machine learning approaches were often constrained to batch processing. This resulted from the amount of data required for successful modeling, and the restricted performance of traditional systems.
For example, conventional server systems (and the software optimized for those systems) had limited processing power such as a set number of CPUs and cores within a single server. Those systems also had limited high-speed storage, fixed memory footprints, and namespaces confined to a single server.
Ultimately these system constraints led to a choice: either process a small amount of data quickly or process large amounts of data in batches. Because machine learning relies on historical data and comparisons to train models, a batch approach was frequently chosen (see Figure 4-1).

Figure 4-1. Batch approach to machine learning
With the advent of distributed systems, initial constraints were removed. For example, the Hadoop Distributed File System (HDFS) provided a plentiful approach to low-cost storage. New scalable streaming and database technologies provided the ability to process and serve data in real time. Coupling these systems together provides both a real-time and batch architecture.
This approach is often referred to as a Lambda architecture. A Lambda architecture often consists of three layer: a speed layer, a batch layer, and a serving layer, as illustrated in Figure 4-2.
The advantage to Lambda is a comprehensive approach to batch and real-time workflows. The disadvantage is that maintaining two pipelines can lead to excessive management and administration to achieve effective results.
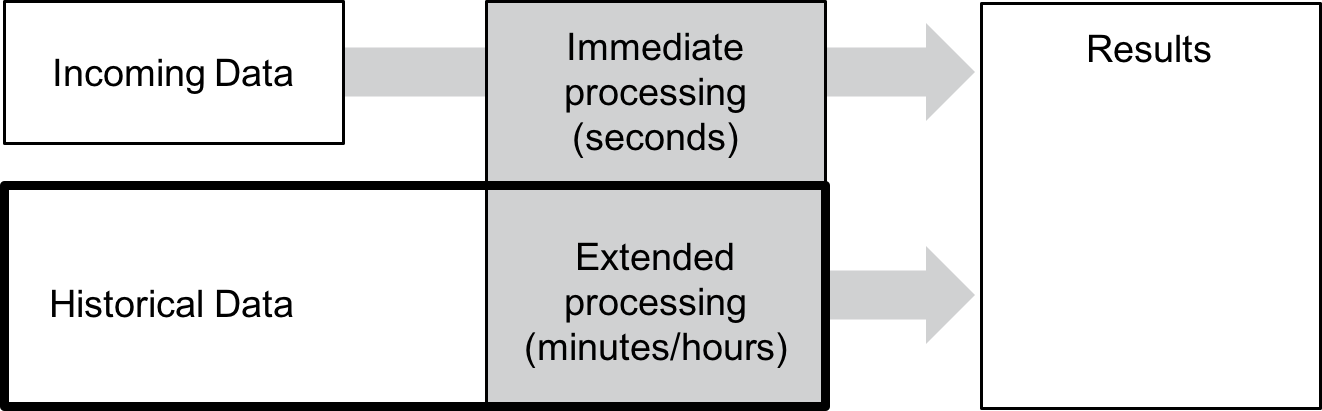
Figure 4-2. Lambda architecture
Moving to Real Time: A Race Against Time
Although not every application requires real-time data, virtually every industry requires real-time solutions. For example, in real estate, transactions do not necessarily need to be logged to the millisecond. However, when every real estate transaction is logged to a database, and a company wants to provide ad hoc access to that data, a real-time solution is likely required.
Other areas for machine learning and predictive analytics applications include the following:
Information assets
Optimizing commerce, recommendations, preferences
Manufacturing assets
Driving cost efficiency and system productivity
Distribution assets
Ensuring comprehensive fulfillment
Let’s take a look at manufacturing as just one example.
Manufacturing Example
Manufacturing is often a high-stakes, high–capital investment, high-scale production operation. We see this across mega-industries including automotive, electronics, energy, chemicals, engineering, food, aerospace, and pharmaceuticals.
Companies will frequently collect high-volume sensor data from sources such as these:
Manufacturing equipment
Robotics
Process measurements
Energy rigs
Construction equipment
The sensor information provides readings on the health and efficiency of the assets, and is critical in areas of high capital expenditure combined with high operational expenditure.
Let’s consider the application of an energy rig. With drill bit and rig costs ranging in the millions, making use of these assets efficiently is paramount.
Original Batch Approach
Energy drilling is a high-tech business. To optimize the direction and speed of drill bits, energy companies collect information from the bits on temperature, pressure, vibration, and direction to assist in determining the best approach.
Traditional pipelines involve collecting drill bit information and sending that through a traditional enterprise message bus, overnight batch processing, and guidance for the next day’s operations. Companies frequently rely on statistical modeling software from companies like SAS to provide analytics on sensor information. Figure 4-3 offers an example of an original batch approach.
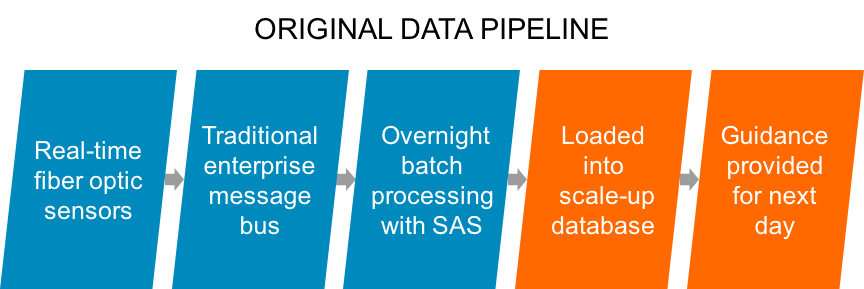
Figure 4-3. Original batch approach
Real-Time Approach
To improve operations, energy companies seek easier facilitation of adding and adjusting new data pipelines. They also desire the ability to process both real-time and historical data within a single system to avoid ETL, and they want real-time scoring of existing models.
By shifting to a real-time data pipeline supported by Kafka, Spark, and an in-memory database such as MemSQL, these objectives are easily reached (see Figure 4-4).
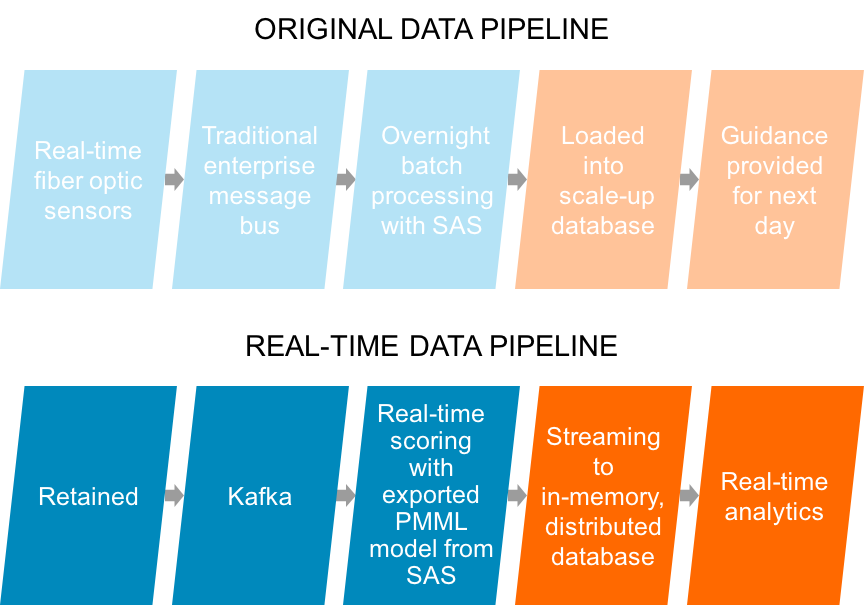
Figure 4-4. Real-time data pipeline supported by Kafka, Spark, and in-memory database
Technical Integration and Real-Time Scoring
The new real-time solution begins with the same sensor inputs. Typically, the software for edge sensor monitoring can be directed to feed sensor information to Kafka.
After the data is in Kafka, it is passed to Spark for transformation and scoring. This step is the crux of the pipeline. Spark enables the scoring by running incoming data through existing models.
In this example, an SAS model can be exported as Predictive Model Markup Language (PMML) and embedded inside the pipeline as part of a Java Archive (JAR) file.
After the data has been scored, both the raw sensor data and the results of the model on that data are saved in the database in the same table.
When real-time scoring information is colocated with the sensor data, it becomes immediately available for query without the need for precomputing or batch processing.
Immediate Benefits from Batch to Real-Time Learning
The following are some of the benefits of a real-time pipeline designed as described in the previous section:
- Consistency with existing models
- By using existing models and bringing them into a real-time workflow, companies can maintain consistency of modeling.
- Speed to production
- Using existing models means more rapid deployment and an existing knowledge base around those models.
- Immediate familiarity with real-time streaming and analytics
- By not changing models, but changing the speed, companies can get immediate familiarity with modern data pipelines.
- Harness the power of distributed systems
- Pipelines built with Kafka, Spark, and MemSQL harness the power of distributed systems and let companies benefit from the flexibility and performance of such systems. For example, companies can use readily available industry standard servers, or cloud instances to stand up new data pipelines.
- Cost savings
- Most important, these real-time pipelines facilitate dramatic cost savings. In the case of energy drilling, companies need to determine the health and efficiency of the drilling operation. Push a drill bit too far and it will break, costing millions to replace and lost time for the overall rig. Retire a drill bit too early and money is left on the table. Going to a real-time model lets companies make use of assets to their fullest extent without pushing too far to cause breakage or a disruption to rig operations.
Get The Path to Predictive Analytics and Machine Learning now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

