Chapter 4. Automation

I was working on a project that required updating several spreadsheets on a regular basis. I wanted to open Excel with multiple worksheets, but doing it by hand was cumbersome (and Excel doesn’t allow you to pass multiple files on a command line). So, I took a few minutes to write the following little Ruby script:
classDailyLogsprivate@@Home_Dir="c:\\MyDocuments\\Documents\\"defdoc_listdocs =Array.new docs <<"Sisyphus Project Planner.xls"docs <<"TimeLog.xls"docs <<"NFR.xls"enddefopen_daily_logsexcel =WIN32OLE.new("excel.application") workbooks = excel.WorkBooks excel.Visible =truedoc_list.eachdo|f|beginworkbooks.Open(@@Home_Dir+ f,true)rescueputs"Cannot open workbook:",@@Home_Dir+ fendendexcel.Windows.Arrange(7)endendDailyLogs.daily_logs
Even though it didn’t take long to open the files by hand, the little time it took was still a waste of time, so I automated it. Along the way, I discovered that you can use Ruby on Windows to drive COM objects, like Excel.
Computers are designed to perform simple, repetitive tasks over and over really fast. Yet an odd thing is happening: people are performing simple, repetitive tasks by hand on computers. And the computers get together late at night and make fun of their users. How did this happen?
Graphical environments are designed to help novices. Microsoft created the Start button in Windows because users had a hard time in previous versions knowing what to do first. (Oddly, you also shut down the computer with the Start button.) But the very things that make casual users more productive can hamper power users. You can get more done at the command line for most development chores than you can through a graphical user interface. One of the great ironies of the last couple of decades is that power users have gotten slower at performing routine tasks. The typical Unix guys of yore were much more efficient because they automated everything.
If you’ve ever been to an experienced woodworker’s shop, you’ve seen lots of specialized tools lying around (you may not have even realized that a laser-guided, gyroscopically balanced lathe existed). Yet in the course of most projects, woodworkers use a little scrap of wood from the floor to temporarily hold two things apart or hold two things together. In engineering terms, these little scraps are “jigs” or “shims.” As developers, we create too few of these little throwaway tools, frequently, because, we don’t think of tools in this way.
Software development has lots of obvious automation targets: builds, continuous integration, and documentation. This chapter covers some less obvious but no less valuable ways to automate development chores, from the single keystroke all the way to little applications.
Don’t Reinvent Wheels
General infrastructure setup is something you have to do for every project: setting up version control, continuous integration, user IDs, etc. Buildix[25] is an open source project (developed by ThoughtWorks) that greatly simplifies this process for Java-based projects. Many Linux distributions come with a “Live CD” option, allowing you to try out a version of Linux right off the CD. Buildix works the same way, but with preconfigured project infrastructure. It is itself an Ubuntu Live CD, but with software development goodies preinstalled. Buildix includes the following preconfigured infrastructure:
Subversion, the popular open source version control package
CruiseControl, an open source continuous integration server
Trac, open source bug tracking and wiki
Mingle, ThoughtWorks’ agile project tracking tool
You boot from the Buildix CD and you have project infrastructure. Or, you can use the Live CD as an installation CD for an existing Ubuntu system. It’s a project in a box.
Cache Stuff Locally
When you develop software, you constantly refer to resources on the Internet. No matter how fast your network connection, you still pay a speed penalty when you view pages via the Web. For oft-referenced material (like programming APIs), you should cache the content locally (which also lets you access it on airplanes). Some content is easy to cache locally: just use your browser’s “Save Page” feature. Lots of times, however, caching gets an incomplete set of web pages.
wget is a *-nix utility designed to cache parts of the web locally. It is available on all the *-nixes and as part of Cygwin on Windows. wget has lots of options to fetch pages. The most common is mirror, which mirrors the entire site locally. For example, to effectively mirror a web site, issue the following command:
wget--mirror--w2--html-extension--convert-links -P c:\wget_files\example1
That’s a mouthful. Table 4-1 gives a breakdown.
| Character(s) | What it’s doing |
wget | The command itself. |
--mirror | The command to mirror the web site. wget will recursively follow links on the site and download all necessary files. By default, it only gets files that were updated since the last mirror operation to avoid useless work. |
--html-extension | Lots of web files have non-HTML extensions even if they ultimately yield HTML files (like cgi or PHP). This flag tells wget to convert those files to HTML extensions. |
--convert-links | All links on the page are converted to local links, fixing the problem for a page that has absolute URIs in them. wget converts all the links to local resources. |
-P
c:\wget_files\example1 | The target directory where you want the site placed locally. |
Automate Your Interaction with Web Sites
There may be web sites from which you would like to distill information that require logon or other steps to get to content. cURL allows you to automate that interaction. cURL is another open source tool that is available for all the major operating systems. It is similar to wget but specializes in interacting with pages to retrieve content or grab resources. For example, say you have the following web form:
<formmethod="GET"action="junk.cgi"><inputtype=textname="birthyear"><inputtype=submitname=pressvalue="OK"></form>
cURL allows you to fetch the page that results after supplying the two parameters:
curl"www.hotmail.com/when/junk.cgi?birthyear=1905&press=OK"
You can also interact with pages that require an HTML POST instead of GET using the “-d” command-line option:
curl-d"birthyear=1905&press=%20OK%20"www.hotmail.com/when/junk.cgi
cURL’s real sweet spot is interacting with secured sites via a variety of protocols (like HTTPS). The cURL web site goes into incredible detail on this subject. This ability to navigate security protocols and other web realities makes cURL a great tool to interact with sites. It comes by default on Mac OS X and most Linux distributions; you can download a copy for Windows at http://curl.haxx.se/.
Interact with RSS Feeds
Yahoo! has a service (currently and perpetually in beta) called Pipes. The Pipes service allows you to manipulate RSS feeds (like blogs), combining, filtering, and processing the results to create either a web page result or another RSS feed. It uses a web-based drag-and-drop interface to create “pipes” from one feed to another, borrowing the Unix command-line pipe metaphor. From a usability standpoint, it looks much like Mac OS X Automator, where each of the commands (or pipe stages) produces output to be consumed by the next pipe in line.
For example, the pipe shown in Figure 4-1 fetches the blog aggregator from the No Fluff, Just Stuff conference site that includes recent blog postings. The blog postings occur in the form of “blog author - blog title,” but I want only the author in the output, so I use the regex pipe to replace the author-title with just the author’s name.
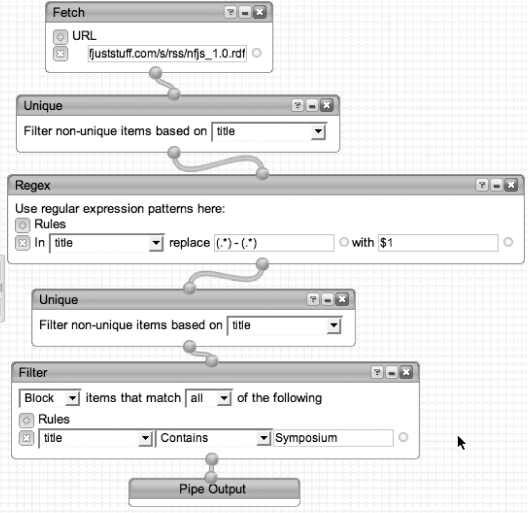
The output of the pipe is either another HTML page or another RSS feed (the pipe is executed whenever you refresh the feed).
RSS is an increasingly popular format for developer information, and Yahoo! Pipes allows you to programmatically manipulate it to refine the results. Not only that, Pipes is gradually adding support for harvesting information off web pages to put into pipes, allowing you to automate retrieval of all sorts of web-based information.
Subvert Ant for Non-Build Tasks
Note
Use tools out of their original context when appropriate.
Batch files and bash scripts allow you to automate work at the operating system–level. But both have picky syntax and sometimes clumsy commands. For example, if you need to perform an operation on a large number of files, it is difficult to retrieve just the list of files you want using the primitive commands in batch files and bash scripts. Why not use tools already designed for this purpose?
The typical make commands we use now as development tools already know how to grab lists of files, filter them, and perform operations on them. Ant, Nant, and Rake have much friendlier syntax than batch and script files for tasks that must operate on groups of files.
Here is an example of subverting Ant to do some work that would be so difficult in a batch file that I never would have bothered. I used to teach a lot of programming classes where I wrote samples on the fly. Frequently, because of questions, I would customize the application as we went along. At the end of the week, everyone wanted a copy of the custom applications I had written. But in the course of writing them, lots of extra stuff piled up (output files, JAR files, temporary files, etc.), so I had to clean out all of the extraneous files and create a nice ZIP archive for them. Rather than doing this by hand, I created an Ant file do to it. The nice part about using Ant was a built-in awareness of a set of files:
<targetname="clean-all"depends="init"><deleteverbose="true"includeEmptyDirs="true"><filesetdir="${clean.dir}"><includename="**/*.war"/><includename="**/*.ear"/><includename="**/*.jar"/><includename="**/*.scc"/><includename="**/vssver.scc"/><includename="**/*.*~"/><includename="**/*.~*~"/><includename="**/*.ser"/><includename="**/*.class"/><containsregexpexpression=".*~$"/></fileset></delete><deleteverbose="true"includeEmptyDirs="true"><filesetdir="${clean.dir}"defaultexcludes="no"><patternsetrefid="generated-dirs"/></fileset></delete></target>
Using Ant allowed me to write a high-level task to perform all the steps I was doing by hand before:
<targetname="zip-samples"depends="clean-all"><deletefile="${class-zip-name}"/><echomessage="Your file name is ${class-zip-name}"/><zipdestfile="${class-zip-name}.zip"basedir="."compress="true"excludes="*.xml,*.zip, *.cmd"/></target>
Writing this as a batch file would have been a nightmare! Even
writing it in Java would be cumbersome: Java has no built-in awareness
of a set of files matching patterns. When using build tools, you don’t
have to create a main method or any of the other
infrastructure already supplied by the build tools.
The worst thing about Ant is its reliance on XML, which is hard to write, hard to read, hard to refactor, and hard to diff. A nice alternative is Gant.[26] It provides the ability to interact with existing Ant tasks, but you write your build files in Groovy, meaning that you are now in a real programming language.
Subvert Rake for Common Tasks
Rake is the make utility for Ruby (written in Ruby). Rake makes a great shell script substitute because it gives you the full expressive power of Ruby but allows you to easily interact with the operating system.
Here’s an example that I use all the time. I do lots of presentations at developers’ conferences, which means that I have lots of slide decks and corresponding example code. For a long time, I would launch the presentation, then remember all the other tools and samples I would have to launch. Inevitably, I would forget one and have to fumble around during the talk to find the missing sample. Then I wised up and automated the process:
requireFile.dirname(__FILE__) +'/../base'TARGET=File.dirname(__FILE__)FILES= ["#{PRESENTATIONS}/building_dsls.key","#{DEV}/java/intellij/conf_dsl_builder/conf_dsl_builder.ipr","#{DEV}/java/intellij/conf_dsl_logging/conf_dsl_logging.ipr","#{DEV}/java/intellij/conf_dsl_calendar_stopping/conf_dsl_calendar_stopping.ipr","#{DEV}/thoughtworks/rbs/intarch/common/common.ipr"]APPS= ["#{TEXTMATE}#{GROOVY}/dsls/","#{TEXTMATE}#{RUBY}/conf_dsl_calendar/","#{TEXTMATE}#{RUBY}/conf_dsl_context"]
This rake file lists all the files that I need to open and all the applications required for the talk. One of the nice things about Rake is its ability to use Ruby files as helpers. This rake file is essentially just declarations. The actual work is done in a base rake file called base, which all the individual rake files rely upon.
require'rake'requireFile.dirname(__FILE__) +'/locations'requireFile.dirname(__FILE__) +'/talks_helper'task:opendoTalksHelper.new(FILES,APPS).open_everythingend
Notice at the top of the file I require a file named talks_helper:
classTalksHelperattr_writer:openers,:processesdefinitialize(openers, processes)@openers,@processes= openers, processesenddefopen_everything@openers.each { |f|`open#{f.gsub/\s/,'\\'}`}unless@openers.nil?@processes.eachdo|p| pid =fork{system p}Process.detach(pid)endunless@processes.nil?endend
This helper class includes the code that does the actual work.
This mechanism allows me to have one simple rake file per presentation
and automatically launch what I need. Rake’s great advantage lies in
the ease with which you can interact with the underlying operating
system. When you delimit strings with the backtick character (`), it
automatically executes it as a shell command. The line of code that
includes `open #{f.gsub /\s/, '\\ '}` really executes the
open command from the underlying
operating system (in this case, Mac OS X; you can substitute start in Windows), using the variable I have
defined above as the argument. Using Ruby to drive the underlying
operating system is much easier than writing bash scripts or batch
files.
Subvert Selenium to Walk Web Pages
Selenium[27] is an open source user acceptance testing tool for web applications. It allows you to simulate user actions by automating the browser via JavaScript. Selenium is written entirely in browser technology, so it runs in all mainstream browsers. It is an incredibly useful tool for testing web applications, regardless of the technology used to create the web application.
But I’m not here to talk about using Selenium as a testing tool. One of the ancillary projects to Selenium is a Firefox browser plug-in called Selenium IDE. Selenium IDE allows you to record your interaction with a web application as a Selenium script, which you can play back through Selenium’s TestRunner or through Selenium IDE itself. While this is useful when creating tests, it is invaluable if you need to automate your interaction with a web application.
Here is a common scenario. You are building the fourth page of a wizard-style web application. The first three pages are complete, meaning that all their interaction works correctly (including things like validations). To debug the behavior of the fourth page, you must walk through the first three pages over and over. And over. And over. You always think, “OK, this will be the last time I have to walk through these pages because I’m sure I’ve fixed the bug this time.” But it’s never the last time! This is why your test database has lots of entries for Fred Flintstone, Homer Simpson, and that ASDF guy.
Use Selenium IDE to do the walking for you. The first time you need to walk through the application to get to the fourth page, record it using Selenium IDE, which will look a lot like Figure 4-2. Now, the next time you have to walk to the fourth page, with valid values in each field, just play back the Selenium script.
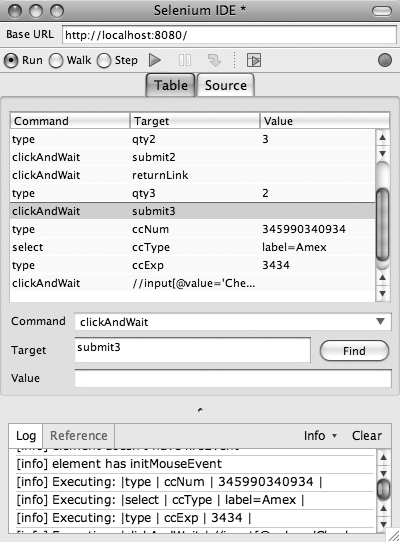
Another great developer use for Selenium pops up as well. When your QA department finds a bug, they generally have some primitive way of reporting how the bug came about: a partial list of what they did, a fuzzy screen shot, or something similarly unhelpful. Have them record their bug discovery missions with Selenium IDE and report back to you. Then, you can automatically walk through the exact scenario they did, over and over, until you fix the bug. This saves both time and frustration. Selenium has essentially created an executable description of user interaction with a web application. Use it!
Note
Don’t spend time doing by hand what you can automate.
Use Bash to Harvest Exception Counts
Here’s an example of using bash that you might run into on a typical project. I was on a large Java project that had gone on for six years (I was just a tourist on this project, arriving in the sixth year for about eight months). One of my chores was to clean up some of the exceptions that occurred on a regular basis. The first thing I did was ask “What exceptions are being thrown and at what frequency?” Of course, no one knew, so my first task was to answer that question.
The problem was that this application excreted 2 GB logs each and every week, containing the exceptions I needed to categorize, along with a huge amount of other noise. It didn’t take me long to realize that it was a waste of time to crack open this file with a text editor. So, I sat down for a little while and ended up with this:
#!/bin/bashforXin$(egrep-o"[A-Z]\w*Exception"log_week.txt|sort|uniq);doecho-n-e"processing$X\t"grep-c"$X"log_week.txtdone
Table 4-2 shows what this handy little bash script does.
| Character(s) | What it’s doing |
egrep -o | Find all strings in the log file that have some text before “Exception” , sort them, and get a distinct list |
"[A-Z]\w*Exception" | The pattern that defines what an exception looks like |
log_week.txt | The gargantuan log file |
| sort | Pipe the results through sort, creating a sorted list of the exceptions |
| uniq | Eliminate duplicate exceptions |
for X in $(. . .)
; | Perform the code in the loop for each exception in the list generated above |
echo -n -e "processing
$X\t" | Echo to the console which exception I’m harvesting (so I can tell it’s working) |
grep -c "$X"
log_week.txt | Find the count of this exception in the giant log file |
They still use this little utility on the project. It’s a good example of automating the creation of a valuable piece of project information that no one had taken the time to do before. Instead of wondering and speculating about the types of exceptions being thrown, we could look and find out exactly, making our targeted fixing of the exceptions much easier.
Replace Batch Files with Windows Power Shell
As part of the work on the Vista release of Windows, Microsoft significantly upgraded the batch language. The code name was Monad, but when it shipped it became Windows Power Shell. (For the sake of the extra trees required to spell it out every time, I’m going to keep calling it “Monad.”) It is built-in to Windows Vista, but you can also use it on Windows XP by just downloading it from the Microsoft web site.
Monad borrows much of its philosophy from similar command shell
languages like bash and DOS, where you can pipe the output of one
command into another. The big difference is that Monad doesn’t use
plain text (like bash); instead, it uses objects. Monad commands
(called cmdlets) understand a common set of
objects that represent operating system constructs, like files,
directories, even things like the Windows event viewer. The semantics
of using it work the same as bash (the pipe operator is even the same
old | symbol), but the capabilities are vast.
Here’s an example. Say that you want to copy all the files that were updated since December 1, 2006 to a folder named DestFolder. The Monad command looks like this:
dir | where-object { $_.LastWriteTime -gt "12/1/2006" } |
move-item -destination c:\DestFolder
Because Monad cmdlets “understand” other cmdlets and the kinds of things they output, you can write scripts much more succinctly than with other scripting languages. Here’s an example. Let’s say that you needed to kill all processes using more than 15 MB of memory using bash:
ps -el | awk '{ if ( $6 > (1024*15)) { print $3 } }'
| grep -v PID | xargs kill
Pretty ugly! It uses five different bash commands, including awk to parse out the results of the ps command. Here is the equivalent Monad command:
get-process | where { $_.VS -gt 15M } | stop-process
Here, you can use the where command to filter the get-process output for a certain property (in this case, the VS property, which is the memory size).
Monad was written using .NET, which means that you also have access to standard .NET
types. String manipulation, which has traditionally been tough in
command shells, relies on the String methods in .NET. For
example, issuing the following Monad command:
get-member -input "String" -membertype method
outputs all the methods of the String class. This
is similar to using the man utility
in *-nix.
Monad is a huge improvement over what came before in the Windows world. It offers first-class programming at the operating system–level. Many of the chores that forced developers to resort to scripting languages like Perl, Python, and Ruby can now be easily done in Monad. Because it is part of the core of the operating system, system-specific objects (like the event viewer) can be queried and manipulated.
Use Mac OS X Automator to Delete Old Downloads
Mac OS X has a graphical way of writing batch files called Automator. In many ways, it is a graphical version of Monad even though it predates Monad by several years. To create Automator workflows (Mac OS X’s version of a script), drag commands from Automator’s work area and “wire” together the output of one command and the input of another. Each application registers its capabilities with Automator upon installation. You can also write pieces of Automator in ObjectiveC (the underlying development language of Mac OS X) to extend it.
Here is an example Automator workflow that deletes all the old files you’ve downloaded if they are more than two weeks old. The workflow is shown in Figure 4-3 and consists of the following steps:
This workflow caches the last two weeks of downloads in a folder called recent.
Empty recent so that it is ready for new files.
Find all downloads with a modified date within the last two weeks.
Move them to recent.
Find all the non-folders in the downloads directory.
Delete all the files.
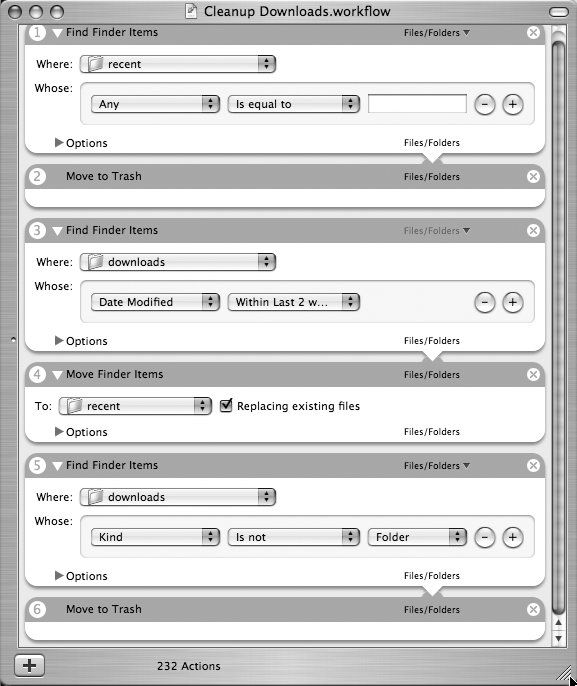
This workflow does more work than the Monad script above because there is no easy way in the workflow to specify that you want all the files not modified in the last two weeks. The best solution is to grab the ones that have been modified in the last two weeks, move them out of the way to a cache directory (named recent), and delete all the files in downloads. You would never bother to do this by hand, but because it’s an automated utility, it can do extra work. One alternative would be to write a shell script in bash and incorporate it into the workflow (one of the options is to call a bash script), but then you’re back to parsing out the results of a shell script to harvest the names. If you wanted to go that far, you could do the whole thing as a shell script.
Tame Command-Line Subversion
Eventually, you get to the point where you can’t subvert another tool or find an open source project that does just what you want. That means it’s time to build your own little jig or shim. This chapter contains lots of different ways to build tools; here are some examples of using these tools to solve problems on real projects.
I’m a big fan of the open source version control system Subversion. It is just the right combination of power, simplicity, and ease of use. Subversion is ultimately a command-line version control system, but lots of developers have created frontends for it (my favorite is the Tortoise integration with Windows Explorer). However, the real power of Subversion lies at the command line. Let’s look at an example.
I tend to add files in small batches to Subversion. To use the command-line tool, you must specify each of the filenames you want to add. This isn’t bad if you have only a few, but if you’ve added 20 files, it is cumbersome. You can use wildcards, but you’ll likely grab files that are already in version control (which doesn’t hurt anything, but you’ll get piles of error messages that might obscure other error messages). To solve this problem, I wrote a little one-line bash command:
svn st | grep '^\?' | tr '^\?' ' ' | sed 's/[ ]*//' | sed 's/[ ]/\\ /g' | xargs svn add
Table 4-3 shows what this one-liner does.
| Command | Result |
svn st | Get Subversion status on all files in this directory and all its subdirectories. The new ones come back with a ? at the beginning and a tab before the filename. |
grep '^\?' | Find all the lines that start with the ?. |
tr '^\?' ' ' | Replace the ? with a space (the tr command translates one character for another). |
sed 's/[
]*//' | Using sed, the stream-based editor, substitute spaces to nothing for the leading part of the line. |
sed 's/[ ]/\\
/g' | The filenames may have embedded spaces, so use sed again to substitute any remaining spaces with the escaped space character (a space with a \ in front). |
xargs svn
add | Take the resulting lines and pump them into the svn add command. |
This command line took the better part of 15 minutes to implement, but I’ve used this little shim (or is it a jig?) hundreds of times since.
Build a SQL Splitter in Ruby
A coworker and I were working on a project where we needed to be able to parse a large (38,000-line) legacy SQL file. To make the parsing job easier, we wanted to break the monolithic file into smaller chunks of about 1,000 lines each. We thought very briefly about doing it by hand, but decided that automating it would be better. We thought about trying to do this with sed, but it looked like it would be complicated. We eventually settled on Ruby, and about an hour later, we had this:
SQL_FILE="./GeneratedTestData.sql"OUTPUT_PATH="./chunks of sql/"line_num =1file_num =0Dir.mkdir(OUTPUT_PATH)unlessFile.exists?OUTPUT_PATHfile =File.new(OUTPUT_PATH+"chunk"+ file_num.to_s +".sql",File::CREAT|File::TRUNC|File::RDWR,0644) done, seen_1k_lines =falseIO.readlines(SQL_FILE).eachdo|line| file.puts(line) seen_1k_lines = (line_num %1000==0)unlessseen_1k_lines line_num +=1done = (line.downcase =~/^\W*go\W*$/orline.downcase =~/^\W*end\W*$/) !=nilifdoneandseen_1k_lines file_num +=1file =File.new(OUTPUT_PATH+"chunk"+ file_num.to_s +".sql",File::CREAT|File::TRUNC|File::RDWR,0644) done, seen_1k_lines =falseendend
This little Ruby program reads lines from the original source file until it has read 1,000 lines. Then, it starts looking for lines that have either GO or END on them. Once it finds either of those two strings, it finishes off the current file and starts another one.
We calculated that it probably would have taken us about 10 minutes to break this file up via brute force, and it took about an hour to automate it. We eventually had to do it five more times, so we almost reclaimed the time we spent automating it. But that’s not the important point. Performing simple, repetitive tasks by hand makes you dumber, and it steals part of your concentration, which is your most productive asset.
Note
Performing simple, repetitive tasks squanders your concentration.
Figuring out a clever way to automate the task makes you smarter because you learn something along the way. One of the reasons it took us so long to complete this Ruby program was our unfamiliarity with how Ruby handled low-level file manipulation. Now we know, and we can apply that knowledge to other projects. And, we’ve figured out how to automate part of our project infrastructure, making it more likely that we’ll find other ways to automate simple tasks.
Note
Finding innovative solutions to problems makes it easier to solve similar problems in the future.
Justifying Automation
When you deploy your application, it takes only three steps: run the “create tables” script on the database, copy the application files to your web server, and update the configuration files for the changes you’ve made to the routing for your application. Simple, easy steps. You have to do this every couple of days. So, what’s the big deal? It takes only about 15 minutes.
What if your project lasts eight months? You will have to go through this ritual 64 times (actually, the pace will pick up as you near the finish line and have to deploy it a lot more often). Add it up: 64 times performing this chore × 15 minutes = 960 minutes = 16 hours = 2 work days. Two full work days to do the same thing over and over! And this doesn’t take into account the number of times you accidentally forget to do one of the steps, which costs more time in debugging and repairing. If it takes you less than two days to automate the whole process, then it’s a no-brainer because you get pure time savings back. But what if it takes three days to automate it—is it still worth it?
I have encountered some system administrators who write bash scripts for every task they perform. They do this for two reasons. First, if you do it once, you’re almost certainly going to do it again. Bash commands are very terse by design, and it sometimes takes a few minutes even for an experienced developer to get it right. But if you ever have to do that task again, the saved commands save you time. Second, keeping all the nontrivial command-line stuff around in scripts creates living documentation of what you did, and perhaps why you performed some task. Saving everything you do is extreme, but storage is very cheap—much cheaper than the time it takes to recreate something. Perhaps you can compromise: don’t save every single thing you do, but the second time you find yourself doing something, automate it. Chances are excellent that if you do it twice, you’ll end up doing it 100 times.
Virtually everyone on *-nix systems creates aliases in their hidden .bash_profile configuration files, with commonly used command-line shortcuts. Here are some examples, showing the general syntax:
aliascatout='tail -f /Users/nealford/bin/apache-tomcat-6.0.14/logs/catalina.out'aliasderby='~/bin/db-derby-10.1.3.1-bin/frameworks/embedded/bin/ij.ksh'aliasmysql='/usr/local/mysql/bin/mysql -u root'
Any frequently used command can appear in this file, freeing you from having to remember some incantation that does magic. In fact, this ability significantly overlaps that of using key macro tools (see Key Macro Tools” in Chapter 2). I tend to use bash aliases for most things (less overhead with expanding the macro), but one critical category exists for which I use key macro tools. Any command line you have that contains a mixture of double and single quotes is hard to get escaped exactly right as an alias. The key macro tools handle that much better. For example, the svnAddNew script (shown earlier in Tame Command-Line Subversion”) started as a bash alias, but it was driving me nuts trying to get all the escaping just right. It now lives as a key macro, and life is much simpler.
Note
Justifying automation is about return on investment and risk mitigation.
You will see lots of chores in your projects that you would like to automate away. You have to ask yourself the following questions (and be honest with your answers):
Will it save time in the long run?
Is it prone to errors (because of lots of complex steps) that will rob time if done incorrectly?
Does this task destroy my focus? (Almost any task takes you away from your locus of attention, making it harder to get back to your focused state.)
What is the hazard of doing it wrong?
The last question is important because it addresses risk. I was once on a project with people who, for historical reasons, didn’t want to create separate output directories for their code and the tests. To run the tests, we needed to create three different test suites, one for each kind of test (unit, functional, and integration). The project manager suggested that we just create the test suite by hand. But we decided to take the time to automate its creation via reflection instead. Updating the test suite by hand is error prone; it is too easy for a developer to write tests and then forget to update the test suite, meaning that his work will never get executed. We deemed the hazard of not automating as too great.
One of the things that will probably worry your project manager when you want to automate some task is that it will spiral out of control. We all have the experience of thinking that we can get something done in two hours only to have it quickly turn into four days. The best way to mitigate this risk is to timebox your efforts: allocate an exact amount of time for exploration and fact gathering. At the end of the timebox, re-evaluate objectively whether completely pursuing this task is feasible. Timeboxed development is about learning enough to make realistic judgments. At the end of a timebox, you may decide to use another one to find out more. I know that the clever automation task is more interesting than your project work, but be realistic. Your boss deserves real estimates.
Don’t Shave Yaks
Finally, don’t allow your automation side project to turn into yak shaving. Yak shaving is part of the official jargon file for computer science. It describes this scenario:
You want to generate documentation based on your Subversion logs.
You try to add a Subversion hook only to discover that the Subversion library you have is incompatible and therefore won’t work with your web server.
You start to update your web server, but realize that the version you need isn’t supported by the patch level of your operating system, so you start to update your operating system.
The operating system upgrade has a known issue with the disk array the machine uses for backups.
You download an experimental patch for the disk array that should get it to work with your operating system, which works but causes a problem with the video driver.
At some point, you stop and try to remember what got you started down this road. You come to the realization that you are shaving a yak, and you stop to try to figure out what shaving a yak has to do with generating documentation for Subversion logs.
Yak shaving is dangerous because it eats up a lot of time. It also explains why estimating tasks is so often wrong: just how long does it take to fully shave a yak? Always keep in mind what you are trying to achieve, and pull the plug if it starts to spiral out of control.
Summary
This chapter contained lots of examples of ways to automate things, but the examples aren’t really the important point. They simply serve to illustrate ways that I and others have figured out to automate common chores. Computers exist to perform simple, repetitive tasks: put them to work! Notice the repetitive stuff that you do on a daily and weekly basis and ask yourself: can I automate this away? Doing so increases the amount of time you can spend working on useful problems, instead of solving the same simple problem over and over. Performing simple tasks by hand robs some of your concentration, so eliminating those little nagging chores frees your precious mindpower for other things.
Get The Productive Programmer now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

