May 2025
Beginner to intermediate
420 pages
5h 24m
Chinese
本作品已使用人工智能进行翻译。欢迎您提供反馈和意见:translation-feedback@oreilly.com
通常,我们对路径的第一个概念是,从起点到终点需要经过多少个站点。 这就是第 8 章的主题。
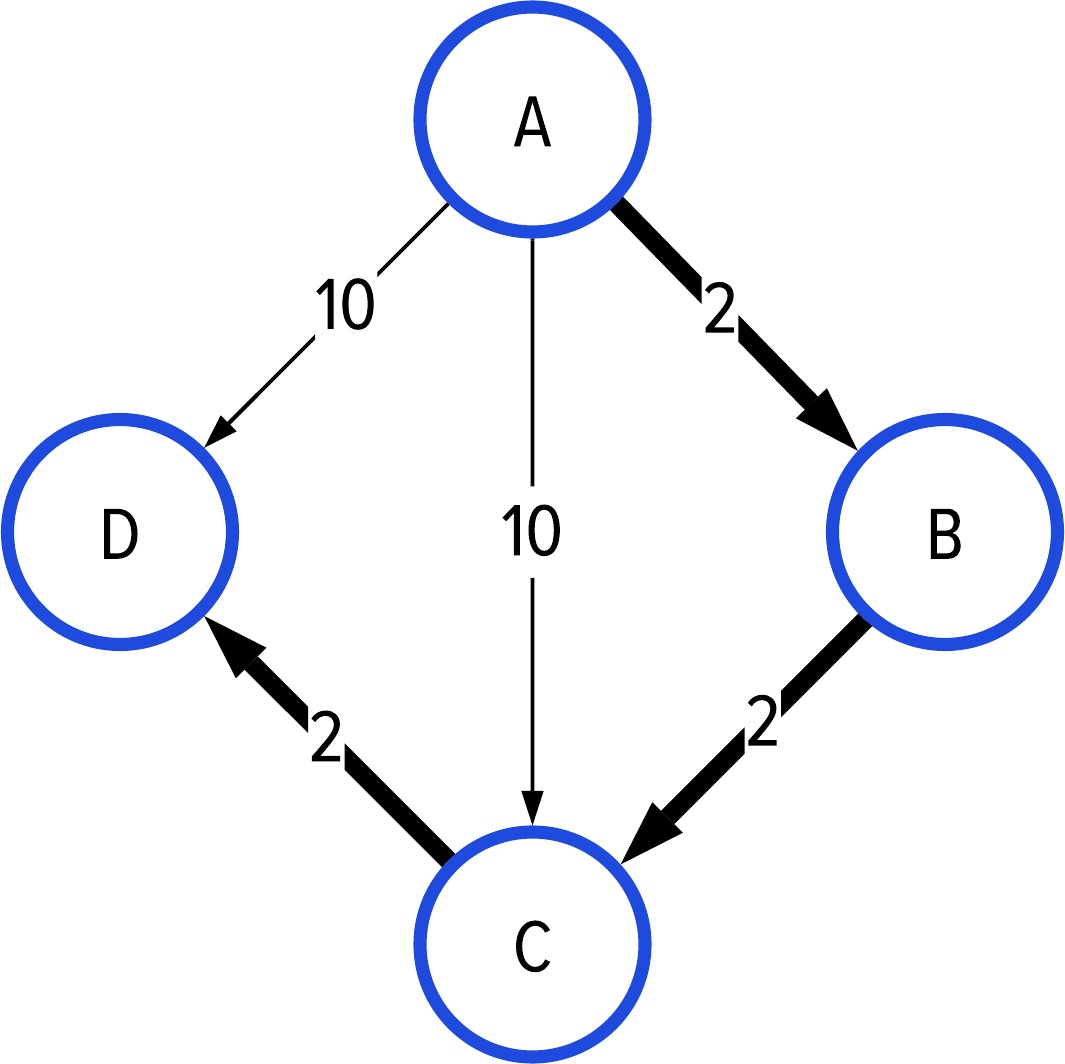
在处理图中路径时,下一个概念是发展距离的概念。我们可以为路径上的每一步添加某种权重或成本。我们将这类问题称为 "最小成本路径"或 "最短加权路径"。
最短加权路径是计算机科学和数学领域非常流行的优化问题。这类问题往往是多方面的、复杂的优化问题,因为它们试图将多个信息源组合成一个成本度量,以达到最小化。
我们在第 8 章末尾看到过一个加权路径问题的例子。我们试图通过聚集路径权重来找到数据中最可信的路径。由于在我们的样本数据中,高信任度由较高的值表示,因此这种寻路问题导致我们发现,信任度较高的路径也是穿过我们数据的较长路径。这并不是我们想要的结果。
相反,我们需要了解如何利用边的权重来寻找最短路径。通过数学和计算机科学的视角,我们希望创建一个有界最小优化问题。
从这个意义上说,高信任度与路径长度成反比。 我们希望找到既短又具有高信任度的路径。这就是我们本章要解决和优化的难点二元性。
本章主要分为三节。
在第一节中,我们将正式定义最短加权路径问题,并走一遍算法。 我们的寻路算法使用广度优先搜索来优化寻路,从而找到最短加权路径。
第二部分介绍边缘权重归一化过程。我们将介绍权重从 "越高越好 "到 "越低越好 "的一般转换和翻转过程。我们将展示为样本数据集计算的新权重,创建新边缘,并重新加载示例的归一化信任分数。
最后一节将在我们的规范化数据上使用 A* 算法。我们将用 Gremlin 查询语言分解编写 A* 算法,并在示例数据上运行该算法,以查找公钥1094 和公开邀请1337 之间的最短加权路径。
虽然您阅读本书的旅程漫长,但我们希望您能高度信任我们即将推出的范例。看到了吗?您已经将较长的路径与较高的信任度联系起来了。
我们已经尝试过在寻路问题中使用边权重。在第 8 章末尾,当我们引入sack() 步骤来汇总比特币场外交易信任网络中各路径的信任评级时,我们就已经这样做了。
然而,我们的过程效率很低,因为我们所拥有的工具并不能解决我们认为要解决的问题。本节将通过传授两种新工具来解决我们第一次尝试失败的两个原因。
首先,我们将定义最短加权路径问题,并举出几个正确的例子。然后,我们将介绍一种寻找最短加权路径问题解决方案的新算法,即 A* 搜索算法。稍后,当我们在 Gremlin 中构建 A* 搜索算法来寻找规范化比特币 OTC 网络中的最短加权路径时,您将看到这些工具。
让我们从新的问题定义开始。
Read now
Unlock full access