Chapter 4. Topologies for Enterprise Storage Architecture
At its most fundamental level, the value of log analytics depends upon drawing on the largest universe of data possible and being able to manipulate it effectively to derive valuable insights from it. Two primary requirements of that truism from a systems perspective are capacity and performance,1 meaning that the systems that underlie log analytics—including storage, compute, and networking—must be able to handle massive and essentially open-ended volumes of data with the speed to make its analysis useful to satisfy business requirements.
As datacenter technologies have evolved, some advances in the ability to handle larger data volumes at higher speed have required little effort from an enterprise architecture perspective. For example, storage drives continue to become larger and less expensive, and swapping out spinning HDDs for solid-state drives (SSDs) is an increasingly simple transition. Datacenter operators continue to deploy larger amounts of memory and more powerful processors as the generations of hardware progress. These changes enable new horizons for what’s possible, with little effort on the part of the practitioner.
Accompanying changes to get the full value out of hardware advances require more ingenuity. As a simple example, advances in performance, security, and stability enabled by a new generation of processors might require the use of a new instruction set architecture such that software needs to be modified to take advantage of it.
More broadly and perhaps less frequently, changes to enterprise architecture are needed to take full advantage of technology advances as well as to satisfy new business needs. The rise of compute clusters, virtualization and containers, and SANs are examples of this type of technological opportunities and requirements.
Like other usage categories, log analytics draws from and requires all these types of changes. Much of what is possible today is the direct result of greater processing power, faster memory, more capable storage media, and more advanced networking technologies, compared to what came before. At the same time, seizing the full opportunity from these advances is tied to rearchitecting the datacenter. Incorporation of cloud technologies, edge computing, and the IoT are high-profile examples that most conference keynotes at least make mention of.
One critical set of challenges inherent to enabling massive data manipulations such as those involved in log analytics is the ballooning scale and complexity of the datacenter architecture required to collect, manipulate, store, and deliver value from the data. Platoons of system administrators are needed just to replace failed drives and other components, while the underlying architecture itself might not be ideal at such massive scale.
Note
Log analytics place performance demands on the underlying systems that are an order of magnitude greater than those of a general-purpose datacenter infrastructure. That reality means that the same architectures—including for storage—that have met conventional needs for years need more than an incremental degree of change; evolution at the fundamental architecture level might be indicated.
One example of the need to fundamentally revise architectures as new usages develop is the emergence of storage area networks (SANs), which took storage off the general network and created its own, high-performance network designed and tuned specifically for the needs of block storage, avoiding local area network (LAN) bottlenecks associated with passing large data volumes. Now, log analytics and enterprise analytics more generally are examples of emerging, data-intensive usages that place challenges beyond the outer limits of SAN performance.
Newer network-scale storage architectures must be able to handle sustained input/output (I/O) rates in the range of tens of gigabytes per second. Hyper-distributed applications are demanding heretofore unheard-of levels of concurrency. The architecture as a whole must be adaptable to the ongoing—and accelerating—growth of data stores. That requirement not only demands that raw capacity scale out as needed, but to support that larger capacity, performance must scale out in lockstep so that value can be driven from all that data. Complexity must be kept in check as well, lest management of the entire undertaking become untenable. Ultimately, it is important to remember that analysts and end users really aren’t interested in the storage, but rather how long it takes them to get to a meaningful result.
To consider the high-level arrangement of resources as it pertains to these challenges, three storage-deployment models play primary roles (see also Figure 4-1):
- DAS
-
Simple case in which each server has its own local storage on board that is managed by some combination of OS, hypervisor, application, or other software.
- Virtualized storage
-
Pools storage resources from across the datacenter into an aggregated virtual store from which an orchestration function dynamically allocates it as needed.
- Physically disaggregated storage and compute
-
Draws from the conventional NAS design pattern, where storage devices are distinct entities on the physical network.
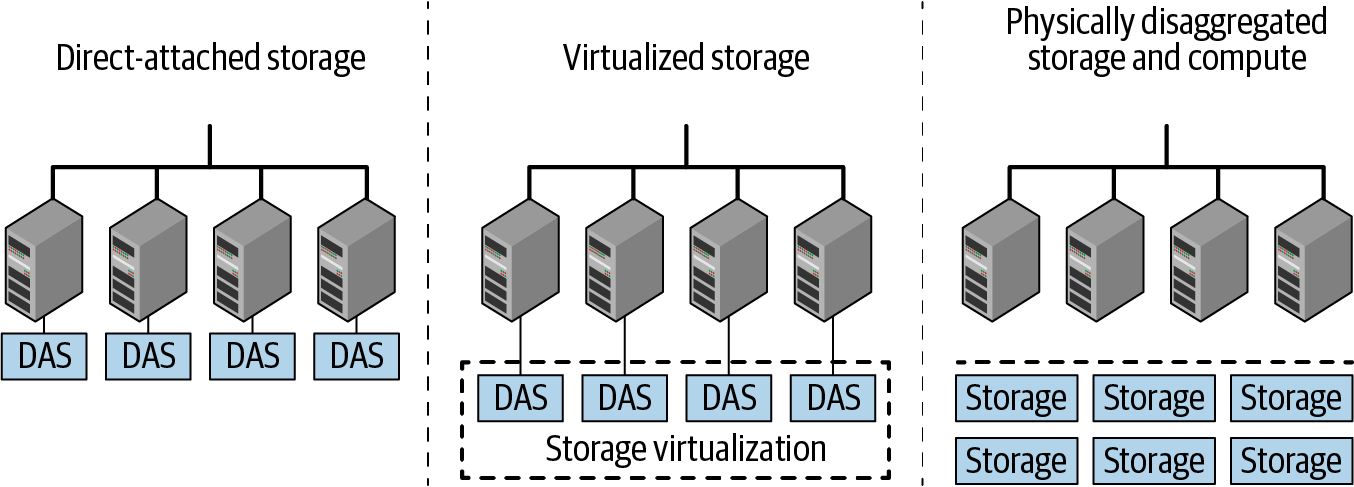
Figure 4-1. Common models for storage architecture in the enterprise
Direct-Attached Storage (DAS)
In many organizations, log analytics has grown organically from the long-standing use of log data on an as-needed basis for tasks such as troubleshooting and root-cause analysis of performance issues. Often, no specific initiative is behind expanded usages for logfiles; instead, individuals or working teams simply find new ways to apply this information to what they are already doing.
Similarly, no specific architecture is adopted to support log analytics’ potential, and the systems that perform log analytics are general-purpose servers with DAS that consist of one or more HDDs or SSDs in each server unit. Scaling out in this model consists of buying more copies of the same server. As the organization adopts more advanced usages to get the full value from log analytics, a sprawling infrastructure develops that is difficult to manage and maintain. Requirements for datacenter space, power, and cooling can also become cost-prohibitive.
In addition, this approach can constrain flexibility, because the organization must continue to buy the same specific type of server, with the same specific drive configuration. Moreover, in order to add storage space for larger collections of historic data, it is necessary to buy not just the storage capacity itself, but the entire server as a unit, with added cost for compute that might not be needed, as well as increased datacenter resources to support it. The inefficiency associated with that requirement multiplies as the log analytics undertaking grows.
Virtualized Storage
Storage virtualization arose in part as a means of improving resource efficiency. This model continues to use DAS at the physical level, with a virtualization layer that abstracts storage from the underlying hardware. Even though the physical storage is dispersed, applications see it in aggregate, as a single, coherent entity of which they can be assigned a share as needed. This approach helps eliminate unused headroom in any given server by making it available to the rest of the network, as well.
The software-defined nature of the virtualized storage resource builds further upon the inherent rise in efficiency from this method of sharing local storage. Orchestration software dynamically creates a discrete logical storage resource for a given workload when it is needed and eliminates it when it is no longer needed, returning the storage capacity to the generalized resource pool.
Virtualization of compute and networking extends this software-defined approach further, by creating on-demand instances of those resources, as well. Together, these elements enable a software-defined infrastructure that can help optimize efficient use of capital equipment and take advantage of public, private, and hybrid cloud. Because the storage topology for the network is continually redefined in response to the needs of the moment, the infrastructure theoretically reflects a best-state topology at all times.
Software-defined storage was developed for the performance and density requirements of traditional IT applications. Because log analytics has I/O requirements that are dramatically higher than those workloads, it can outpace the capabilities of the storage architecture. In particular, the distributed and intermixed nature of the infrastructure in this model can create performance bottlenecks that strain the ability of the network to keep up.
In addition, because data movement across the network is typically more expensive and slower than computation, it is not unusual to create multiple copies of data at different locations, which increases physical storage requirements.
Physically Disaggregated Storage and Compute
Moving to a more cloud-like model, the storage architecture can physically disaggregate storage and compute. In this model, large numbers of servers are provisioned that don’t keep state themselves, but just represent and transform that state. Separate storage devices are deployed as a separate tier that maintain all the states for those servers. The storage devices themselves are purpose-built to be highly efficient at scale, handling data even in the multipetabyte range.
Because the compute and storage elements of the environment are physically disaggregated, they can be scaled out independently of each other. More compute or storage elements can be added in a flexible way, providing the optimal level of resources needed as business requirements grow. In addition, as historical data stores become larger, they benefit from the fact that this physically disaggregated model allows storage elements to be packed very densely together, to improve network efficiency, and to use efficient error encoding to get maximum value out of the storage media. The centralized nature of the storage also helps improve efficiency by avoiding the need to create extraneous copies of the data.
At large scale, physical disaggregation is often superior to compute and storage virtualization at meeting the high IO requirements of log analytics implementations. And while conceptually, this design approach is not entirely new compared to SAN or NAS, it can be built to meet design criteria that are beyond the performance and throughput capabilities of those traditional architectures. Physically disaggregated architectures for log analytics are, at some level, just new and enhanced manifestations of established concepts.
For example, one critical design goal is to build in extremely high concurrency, parallelizing work at a very fine-grained level that enables it to be spread evenly across the environment. In addition, the representations of file structure and metadata should be thoroughly distributed. These consistency measures help avoid hot spots within the infrastructure. This allows for the optimal use of resources to support real-time operation in the face of the massive ingest rates associated with log analytics, which can commonly exert 10 times the performance and throughput requirements on the infrastructure compared to common enterprise workloads.
Tip
Physically decoupling compute and storage enables each to scale out independent of the other, decreasing total cost of ownership (TCO) by removing the need to purchase extraneous equipment. Following an architectural pattern similar to SAN and NAS but with modern data management and flash-based storage enables the levels of performance and throughput needed for real-time analytics at scale.
1 Of the canonical three legs of the data tripod—volume, velocity, and variety—this context is concerned primarily with the first two because of its focus on system resources, as opposed to how those resources are applied. More broadly speaking, all three are intertwined and essential not only to storage architecture, but to the entire solution stack.
Get Understanding Log Analytics at Scale, 2nd Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

