The Unix operating system design is centered on its filesystem, which has several interesting characteristics. We’ll review the most significant ones, since they will be mentioned quite often in forthcoming chapters.
A Unix file is an information container structured as a sequence of bytes; the kernel does not interpret the contents of a file. Many programming libraries implement higher-level abstractions, such as records structured into fields and record addressing based on keys. However, the programs in these libraries must rely on system calls offered by the kernel. From the user’s point of view, files are organized in a tree-structured namespace, as shown in Figure 1-2.
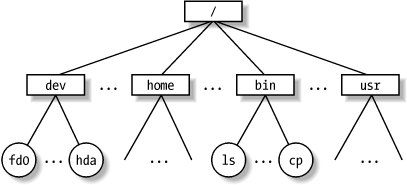
All the nodes of the tree, except the leaves, denote directory names.
A directory node contains information about the files and directories
just beneath it. A
file or directory name consists of a
sequence of arbitrary ASCII characters,[8] with the exception of / and of
the null character \0. Most filesystems place a limit on the length
of a filename, typically no more than 255 characters. The
directory corresponding to the root
of the tree is called the root directory
. By convention, its name is a slash
(/). Names must be different within the same
directory, but the same name may be used in different directories.
Unix associates a current working directory with each process (see Section 1.6.1 later in this chapter); it belongs to the process execution context, and it identifies the directory currently used by the process. To identify a specific file, the process uses a pathname , which consists of slashes alternating with a sequence of directory names that lead to the file. If the first item in the pathname is a slash, the pathname is said to be absolute , since its starting point is the root directory. Otherwise, if the first item is a directory name or filename, the pathname is said to be relative , since its starting point is the process’s current directory.
While specifying filenames, the notations " .” and “..” are also used. They denote the current working directory and its parent directory, respectively. If the current working directory is the root directory, “.” and “..” coincide.
A filename included in a directory is called a file hard link , or more simply, a link . The same file may have several links included in the same directory or in different ones, so it may have several filenames.
The Unix command:
$ ln f1 f2
is used to create a new hard link that has the pathname
f2 for a file identified by the pathname
f1.
Hard links have two limitations:
Users are not allowed to create hard links for directories. This might transform the directory tree into a graph with cycles, thus making it impossible to locate a file according to its name.
Links can be created only among files included in the same filesystem. This is a serious limitation, since modern Unix systems may include several filesystems located on different disks and/or partitions, and users may be unaware of the physical divisions between them.
To overcome these limitations, soft links (also called symbolic links ) have been introduced. Symbolic links are short files that contain an arbitrary pathname of another file. The pathname may refer to any file located in any filesystem; it may even refer to a nonexistent file.
The Unix command:
$ ln -s f1 f2
creates a new soft link with pathname f2 that
refers to pathname f1. When this command is
executed, the filesystem extracts the directory part of
f2 and creates a new entry in that directory of
type symbolic link, with the name indicated by f2.
This new file contains the name indicated by pathname
f1. This way, each reference to
f2 can be translated automatically into a
reference to f1.
Unix files may have one of the following types:
Regular file
Directory
Symbolic link
Block-oriented device file
Character-oriented device file
Pipe and named pipe (also called FIFO)
Socket
The first three file types are constituents of any Unix filesystem. Their implementation is described in detail in Chapter 17.
Device files are related to I/O devices and device drivers integrated into the kernel. For example, when a program accesses a device file, it acts directly on the I/O device associated with that file (see Chapter 13).
Pipes and sockets are special files used for interprocess communication (see Section 1.6.5 later in this chapter; also see Chapter 18 and Chapter 19)
Unix makes a clear distinction between the contents of a file and the information about a file. With the exception of device and special files, each file consists of a sequence of characters. The file does not include any control information, such as its length or an End-Of-File (EOF) delimiter.
All information needed by the filesystem to handle a file is included in a data structure called an inode . Each file has its own inode, which the filesystem uses to identify the file.
While filesystems and the kernel functions handling them can vary widely from one Unix system to another, they must always provide at least the following attributes, which are specified in the POSIX standard:
File type (see the previous section)
Number of hard links associated with the file
File length in bytes
Device ID (i.e., an identifier of the device containing the file)
Inode number that identifies the file within the filesystem
User ID of the file owner
Group ID of the file
Several timestamps that specify the inode status change time, the last access time, and the last modify time
Access rights and file mode (see the next section)
The potential users of a file fall into three classes:
The user who is the owner of the file
The users who belong to the same group as the file, not including the owner
All remaining users (others)
There are three types of access rights — Read , Write , and Execute — for each of these three classes. Thus, the set of access rights associated with a file consists of nine different binary flags. Three additional flags, called suid (Set User ID), sgid (Set Group ID), and sticky , define the file mode. These flags have the following meanings when applied to executable files:
-
suid A process executing a file normally keeps the User ID (UID) of the process owner. However, if the executable file has the
suidflag set, the process gets the UID of the file owner.-
sgid A process executing a file keeps the Group ID (GID) of the process group. However, if the executable file has the
sgidflag set, the process gets the ID of the file group.-
sticky An executable file with the
stickyflag set corresponds to a request to the kernel to keep the program in memory after its execution terminates.[9]
When a file is created by a process, its owner ID is the UID of the
process. Its owner group ID can be either the GID of the creator
process or the GID of the parent directory, depending on the value of
the sgid flag of the parent directory.
When a user accesses the contents of either a regular file or a directory, he actually accesses some data stored in a hardware block device. In this sense, a filesystem is a user-level view of the physical organization of a hard disk partition. Since a process in User Mode cannot directly interact with the low-level hardware components, each actual file operation must be performed in Kernel Mode. Therefore, the Unix operating system defines several system calls related to file handling.
All Unix kernels devote great attention to the efficient handling of hardware block devices to achieve good overall system performance. In the chapters that follow, we will describe topics related to file handling in Linux and specifically how the kernel reacts to file-related system calls. To understand those descriptions, you will need to know how the main file-handling system calls are used; these are described in the next section.
Processes can access only “opened” files. To open a file, the process invokes the system call:
fd = open(path, flag, mode)
The three parameters have the following meanings:
-
path Denotes the pathname (relative or absolute) of the file to be opened.
-
flag Specifies how the file must be opened (e.g., read, write, read/write, append). It can also specify whether a nonexisting file should be created.
-
mode Specifies the access rights of a newly created file.
This system call creates an “open file” object and returns an identifier called a file descriptor . An open file object contains:
Some file-handling data structures, such as a pointer to the kernel buffer memory area where file data will be copied, an
offsetfield that denotes the current position in the file from which the next operation will take place (the so-called file pointer ), and so on.Some pointers to kernel functions that the process can invoke. The set of permitted functions depends on the value of the
flagparameter.
We discuss open file objects in detail in Chapter 12. Let’s limit ourselves here to describing some general properties specified by the POSIX semantics.
A file descriptor represents an interaction between a process and an opened file, while an open file object contains data related to that interaction. The same open file object may be identified by several file descriptors in the same process.
Several processes may concurrently open the same file. In this case, the filesystem assigns a separate file descriptor to each file, along with a separate open file object. When this occurs, the Unix filesystem does not provide any kind of synchronization among the I/O operations issued by the processes on the same file. However, several system calls such as
flock( )are available to allow processes to synchronize themselves on the entire file or on portions of it (see Chapter 12).
To create a new file, the process may also invoke the creat( ) system call, which is handled by the kernel exactly like
open( ).
Regular Unix files can be addressed either sequentially or randomly, while device files and named pipes are usually accessed sequentially (see Chapter 13). In both kinds of access, the kernel stores the file pointer in the open file object — that is, the current position at which the next read or write operation will take place.
Sequential access is implicitly assumed: the read( ) and write( ) system calls always refer
to the position of the current file pointer. To modify the value, a
program must explicitly invoke the lseek( ) system
call. When a file is opened, the kernel sets the file pointer to the
position of the first byte in the file (offset 0).
The lseek( ) system call requires the following
parameters:
newoffset = lseek(fd, offset, whence);
which have the following meanings:
-
fd Indicates the file descriptor of the opened file
-
offset Specifies a signed integer value that will be used for computing the new position of the file pointer
-
whence Specifies whether the new position should be computed by adding the
offsetvalue to the number 0 (offset from the beginning of the file), the current file pointer, or the position of the last byte (offset from the end of the file)
The read( ) system call requires the following
parameters:
nread = read(fd, buf, count);
which have the following meaning:
-
fd Indicates the file descriptor of the opened file
-
buf Specifies the address of the buffer in the process’s address space to which the data will be transferred
-
count Denotes the number of bytes to read
When handling such a system call, the kernel attempts to read
count bytes from the file having the file
descriptor fd, starting from the current value of
the opened file’s offset field. In some
cases—end-of-file, empty pipe, and so on—the kernel does
not succeed in reading all count bytes. The
returned nread value specifies the number of bytes
effectively read. The file pointer is also updated by adding
nread to its previous value. The write( ) parameters are similar.
When a process does not need to access the contents of a file anymore, it can invoke the system call:
res = close(fd);
which releases the open file object corresponding to the file
descriptor fd. When a process terminates, the
kernel closes all its remaining opened files.
To rename or delete a file, a process does not need to open it. Indeed, such operations do not act on the contents of the affected file, but rather on the contents of one or more directories. For example, the system call:
res = rename(oldpath, newpath);
changes the name of a file link, while the system call:
res = unlink(pathname);
decrements the file link count and removes the corresponding directory entry. The file is deleted only when the link count assumes the value 0.
Get Understanding the Linux Kernel, Second Edition now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

