Chapter 1. Drupal Overview
This book will show you how to build many different types of websites using the Drupal web publishing platform. Whether you’re promoting your rock band or building your company’s intranet, some of your needs will be the same. From a foundational perspective, your site will have content; be it audio or text or animated GIF images, a website communicates its content to the world. You will also need to manage this content. Although it’s possible to roll your own system with enough knowledge of the underlying web technologies, Drupal makes creating your website; adding new features; and day-to-day adding, editing, and deleting of content quick and easy. And finally, your website will have visitors, and this book will show you many different ways in which you can engage and interact with your community using Drupal.
This chapter will begin by providing the hard facts about Drupal: what it is, who uses it, and why they chose it. It will then dive into a conceptual overview, starting with what this ambiguous term “content management” actually means, and how we arrived at building websites this way. And finally, we’ll define and explain the core Drupal concepts that are necessary to understand how Drupal handles its content.
What Is Drupal?
Drupal is an open source content management system (CMS) being used by hundreds of thousands of organizations and individuals to build engaging, content-rich websites.[1] Building a website in Drupal is a matter of combining together various “building blocks,” which are described later in this chapter, in order to customize your website’s functionality to your precise needs. Once built, a Drupal website can be maintained with online forms, and without having to change code manually. Drupal is free to use; it has an enormous library of constantly evolving tools that you can use to make your website shine.
Drupal is also a content management framework (CMF). In addition to providing site-building tools for webmasters, it offers ways for programmers and developers to customize Drupal using plug-in modules. Almost every aspect of Drupal’s behavior can be customized using these modules, and thousands of them exist that add features from photo galleries to shopping carts to talk-like-a-pirate translators. Most modules have been contributed to the Drupal community and are available for download and use on your Drupal-based website, too. All of the functionality that we’ll be discussing in this book is built using a combination of “core” Drupal and these community-created modules.
It’s noteworthy to acknowledge Drupal’s community; the wetware element of Drupal is often cited as one of Drupal’s biggest assets. When Drupal 6 was released in February 2008, more than 700 members of the community contributed code to the core component of the software. More than 2,000 developers maintain contributed modules, with countless more helping with testing, documentation, user support, translations, and other important areas of the project. Those familiar with evaluating open source platforms will attest to the importance of a thriving community base.
Who Uses It?
Over the last couple of years, the popularity of Drupal has exploded, to the point where some pretty big names have taken notice. Media companies such as MTV UK, Lifetime, and Sony BMG Records are using Drupal as a means of building loyal communities around their products. Print publishers such as the New York Observer, The Onion, Popular Science magazine, and Fast Company magazine use Drupal to provide interactive online content to their readers. Amnesty International, the United Nations, and the Electronic Frontier Foundation use Drupal to coordinate activism on important issues. Ubuntu Linux, Eclipse, Firefox, and jQuery are open source projects that employ Drupal to nurture their contributor communities. Bloggers such as Tim Berners-Lee, Heather B. Armstrong (a.k.a. Dooce), the BlogHer community, and Merlin Mann use Drupal as their publishing platform. Figure 1-1 shows some of these high-profile Drupal websites.
What these websites have in common is a need for powerful publishing options and rich community features.
There are several places to obtain more information online about who is using Drupal out there today. Dries Buytaert, the Drupal project founder, maintains a list of high-profile Drupal websites on his blog at http://buytaert.net/tag/drupal-sites. The Drupal website has a section containing detailed case studies and success stories (http://drupal.org/cases). Additionally, http://www.drupalsites.net is a directory containing thousands of Drupal websites found across the Internet, from small hobby websites to large social networks with millions of active users.
What Features Does Drupal Offer?
Drupal provides a number of features, which are explained in greater detail in Chapter 2. These include:
- Flexible module system
Modules are plug-ins that can modify and add features to a Drupal site. For almost any functional need, chances are good that either an existing module fits the need exactly or can be combined with other modules to fit the need, or that whatever existing code there is can get you a good chunk of the way there.
- Customizable theming system
All output in Drupal is fully customizable, so you can bend the look and feel of your site to your will (or, more precisely, to your designer’s will).
- Extensible content creation
You can define new types of content (blog, event, word of the day) on the fly. Contributed modules can take this one step further and allow administrators to create custom fields within your newly created content types.
- Innate search engine optimization
Drupal offers out-of-the-box support for human-readable system URLs, and all of Drupal’s output is standards-compliant; both of these features make for search-engine friendly websites.
- Role-based access permissions
Custom roles and a plethora of permissions allow for fine-grained control over who can access what within the system. And existing modules can take this level of access control even further—down to the individual user level.
- Social publishing and collaboration tools
Drupal has built-in support for tools such as group blogging, comments, forums, and customized user profiles. The addition of almost any other feature you can imagine—for instance, ratings, user groups, or moderation tools—is only a download away.
A Brief History of Content Management
Before looking any closer at Drupal, let’s take a brief trip back in time to the days before content management systems. To understand how Drupal and other CMS packages simplify your work, we’ll take a look at how things worked when the Web was young.
A Historical Look at Website Creation
Back in the dim recesses of time (the 1990s, for those who remember zeppelins and Model T cars), web pages were nothing more than simple text files nestled comfortably into folders on a server somewhere on the Internet. With names like index.html, news.html, about_us.html, and so on, these files were viewable by anyone with a web browser. Using the HTML markup language, these files could link back and forth to each other, include images and other media, and generally make themselves presentable. A website, as the hipsters of that day would explain, was just a collection of those files in a particular folder, as pictured in Figure 1-2.
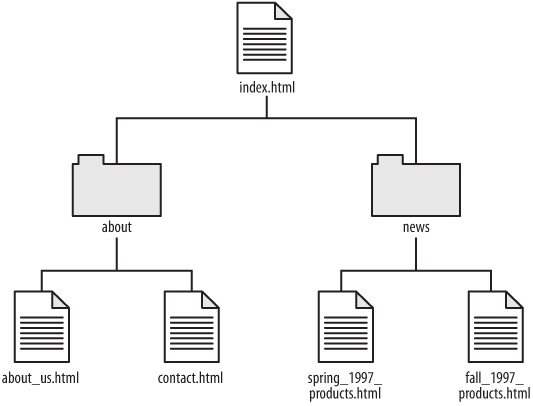
This system worked pretty well, and it made sense. Every URL that a user on the Internet could visit corresponded to a unique .html file on the web server. If you wanted to organize them into sections, you made a folder and moved the files into that folder; for example, http://www.example.com/news/ would be the address to the “News” section of the site, and the 1997 newsletter would be located at http://www.example.com/news/fall_1997_products.html. When the webmaster (or the intern) needed to fix a problem, they could look at the page in their web browser and open up the matching file on the web server to tweak it.
Unfortunately, as websites grew in size, it was obvious that this approach didn’t scale well. After a year or so of adding pages and shuffling directories around, many sites had dozens, hundreds, or sometimes even thousands of pages to manage. And that, friends, caused some serious problems:
- Changing the site’s design required an enormous amount of work
Formatting information, layout, and other site design was done individually on every single page. Cascading Style Sheets (CSS) hadn’t yet taken the web world by storm, so tasks as simple as changing the site’s default font required (that’s right) editing every single file.
- The site structure resulted in massive duplication of content
Most designs for websites included a standard footer at the bottom of the page with copyright and contact information, a header image or some kind of recurring navigation menu, and so on. If anything changed, every file had to be updated. If you were very, very lucky, all the webmasters before you had been very conscientious about making sure that there were no layout variations and this would be a scriptable change. Most webmasters weren’t lucky, and to this day mutter darkly about sites built using FrontPage, PageMill, Dreamweaver, and Notepad—all at once.
- Websites were impossible to keep consistent and up-to-date
Most complex sites were already organized into directories and subdirectories to keep things reasonably tidy. Adding a news story in the news directory meant that you also had to update the “overview” page that listed all news stories, perhaps post a quick notice on the front page of the website, and (horror!) remember to take the notice down when the news was no longer “fresh.” A large site with multiple sections and a fair amount of content could keep a full-time webmaster busy just juggling these updates.
The Age of Scripts and Databases
The search for solutions to these problems prompted the first real revolution in web design: the use of scripts and Common Gateway Interface (CGI) programs. The first step was the use of special tags called Server-Side Includes (SSI) in each HTML file. These tags let web designers tell the web server to suck in the contents of another file (say, a standard copyright message or a list of the latest news stories) and include it in the current web page as if it were part of the HTML file itself. It made updating those bits much easier, as they were stored in only one place.
The second change was the use of simple databases to store pieces of similar content. All the news stories on CNN.com are similar in structure, even if their content differs. The same is true of all the product pages on Apple.com, all the blog entries on Blogger.com, and so on. Rather than storing each one as a separate HTML file, webmasters used a program running on the web server to look up the content of each article from the database and display it with all the HTML markup for the site’s layout wrapped around it. URLs such as http://www.example.com/news/1997/big_sale.html were replaced by something more like http://www.example.com/news.cgi?id=10. Rather than looking in the news directory, then in the 1997 directory, and returning the big_sale.html file to a user’s web browser, the web server would run the news.cgi program, let it retrieve article number 10 from the database, and send back whatever text that program printed out.
All these differences required changes in the way that designers and developers approached the building of websites. But the benefits were more than worth it: dozens or even hundreds of files could be replaced with one or more database-driven scripts, as shown in Figure 1-3.
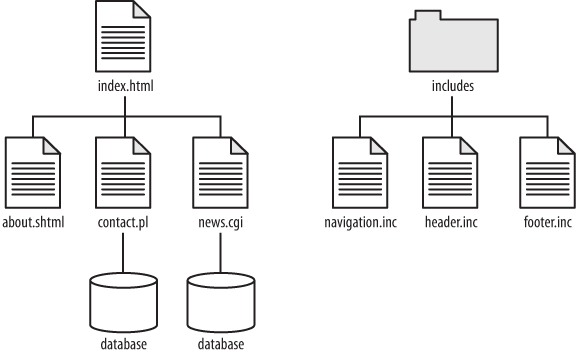
Even with those improvements, however, there were still serious challenges:
- Where do I change that setting again?
Large sites with many different kinds of content (product information, employee bios, press releases, free downloads, and so on) were still juggling an assortment of scripts, separate databases, and other elements to keep everything running. Webmasters updating content had to figure out whether they needed to change an HTML file, an entry in a database, or the program code of the script.
- Too many little pieces were cobbled together
Dynamic content—such as discussion forums or guestbooks where visitors could interact—required their own infrastructure, and often each of these systems was designed separately. Stitching them together into a unified website was no simple task.
The Content Revolution
Slowly but surely, programs emerged to manage these different kinds of content and features using a single, consistent user interface. The older generation of software focused on a particular task or application, but newer CMS implementations offered generalized tools for creating, editing, and organizing the information on a website. Most systems also provided mechanisms for developers to build add-ons and new features without reinventing the wheel. Figure 1-4 illustrates how a content management system uses a single database and script to integrate all of these features.
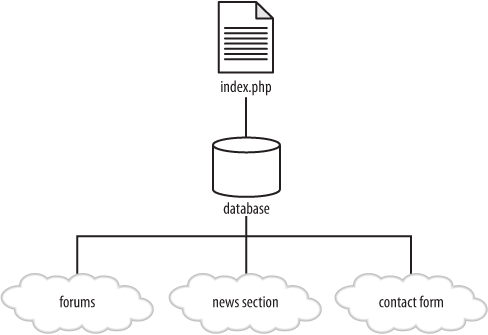
Drupal is one of these next-generation content management systems. It allows you to create and organize many kinds of content, provides user management tools for both the maintainers of and the visitors to your site, and gives you access to thousands of third-party plug-ins that add new features. Dries Buytaert, the founder of the Drupal project, said in a speech to the 2007 Open Source CMS Summit that his goal for Drupal was to “eliminate the webmaster.” That might sound a bit scary if you are the webmaster, but after that first thought, the implications are exciting. Using Drupal, the grunt work of keeping thousands of pages organized and up-to-date vanishes: you can focus on building the features that your site needs and the experience that your users want.
How Does Drupal Work?
At a conceptual level, the Drupal stack looks like Figure 1-5. Drupal is a sort of middle layer between the backend (the stuff that keeps the Internet ticking) and the frontend (what visitors see in their web browsers).
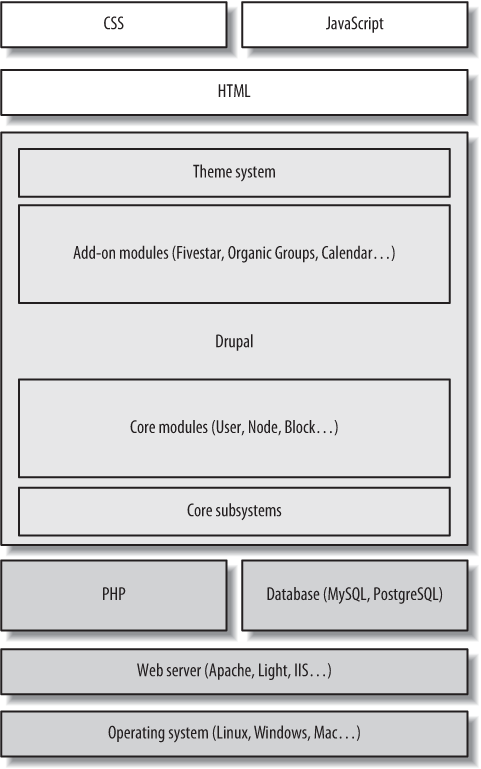
In the bottom layers, things like your operating system, web server, database, and PHP are running the show. The operating system handles the “plumbing” that keeps your website running: low-level tasks such as handling network connections, files, and file permissions. Your web server enables that computer to be accessible over the Internet, and serves up the correct stuff when you go to http://www.example.com. A database stores, well, data: all of the website’s content, user accounts, and configuration settings, in a central place for later retrieval. And PHP is a programming language that generates pages dynamically and shuffles information from the database to the web server.
Drupal itself is composed of many layers as well. At its lowest layer, it provides additional functionality on top of PHP by adding several subsystems, such as user session handling and authentication, security filtering, and template rendering. This section is built upon by a layer of customizable add-on functionality called modules, which will be discussed in the next section. Modules add features to Drupal and generate the contents of any given page. But before the page is displayed to the user, it’s run through the theme system, which allows modification and precise tweaking for even the pickiest designers’ needs. The theme system is covered in detail in Chapter 11.
The theme system outputs page content, usually as XHTML, although other types of rendering are supported. CSS is used to control the layout, colors, and fonts of a given page, and JavaScript is thrown in for dynamic elements, such as collapsible fieldsets on forms and drag-and-drop table rows in Drupal’s administrative interface.
We’ve talked about the “old” way of building websites using static HTML files, the transition to collections of scripts, and the “new” way: full-featured web applications that manage the entire website. This third way—Drupal’s way—requires a new set of conceptual building blocks. Every website you build with Drupal will use them!
Modules
Just about everything in Drupal revolves around the concept of modules, which are files that contain PHP code and a set of functionalities that Drupal knows how to use. All of the administrative- and end-user-facing functionality in Drupal, from fundamental features such as ability to log in or create content to dynamic photo galleries and complex voting systems, all come from modules. Some examples of modules are the Contact module, which enables a site-wide contact form, and the User module, which handles user authentication and permission checking. In other CMS applications, modules are also referred to as plug-ins or extensions.
There are two types of modules: “core” modules, which are included with Drupal itself, and “contributed” modules, which are provided by the Drupal community and can be separately downloaded and enabled. Apart from a few required core modules, all modules can be turned on or off depending on your website’s precise needs.
Though there are contributed modules that offer “drop in and go” functionality, over the years the Drupal community has generally focused on modules that do one thing well, in a way that can be combined with other modules. This approach means that you have almost limitless control over what your website looks like and how it behaves. Your image gallery isn’t limited by what the original developer thought an image gallery ought to look and act like. You can drop in ratings or comments and sort the pictures by camera type rather than date if you’d like. In order to have this flexibility, however, you have to “build” the functionality in Drupal by snapping together various modules and twiddling their options, rather than just checking off a checkbox for “image gallery” and leaving it at that. Drupal’s power brings with it a learning curve not encountered in many other CMS packages, and with the plethora of available modules, it can be daunting trying to determine which to use. Appendix B is dedicated to tips and tricks on how to determine module quality and suitability for your projects.
Users
The next building block of a Drupal website is the concept of users. On a simple brochure-ware website that will be updated by a single administrator and visited only by potential customers, you might create just a single user account for the administrator. On a community discussion site, you would set up Drupal to allow all of the individuals who use the site to sign up for the site and create their own user accounts as well.
Note
The first user you create when you build a new Drupal site—User 1—is special. Similar to the root user on a UNIX server, User 1 has permission to perform any action on the Drupal site. Because User 1 bypasses these normal safety checks, it’s easy to accidentally delete content or otherwise break the site if you use this account for day-to-day editing. It’s a good idea to reserve this account for special administrative tasks and configuration, and create an additional account for posting content.
Every additional user can be assigned to configurable roles, like “editor,” “paying customer,” or “VIP.” Each role can be given permissions to do different things on the website: visiting specific URLs, viewing particular kinds of content, posting comments on existing content, filling out a user profile, even creating more users and controlling their permissions. By default, Drupal comes with two predefined roles: authenticated user and anonymous user. Anyone who creates a user account on the site is automatically assigned the “authenticated user” role, and any visitors who haven’t yet created user accounts (or haven’t yet logged in with their username and password) have the “anonymous user” role.
Content (Nodes)
Nodes are Drupal’s next building block, and one of the most important. An important part of planning any Drupal site is looking at your plans and deciding what specific kinds of content (referred to by Drupal as “content types”) you’ll be working with. In almost every case, each one will be a different kind of node.
All nodes, regardless of the type of content they store, share a handful of basic properties:
An author (the user on your site who created the content)
A creation date
A title
Body content
Do you want to create a page containing your company’s privacy policy? That’s a node. Do you want users to be able to post blog entries on the site? Each one is a node. Will users be posting links to interesting stories elsewhere on the Web? Each of those links is stored as—you guessed it—a node.
In addition to nodes’ basic, common properties, all nodes can take advantage of certain built-in Drupal features, like flags that indicate whether they’re published or unpublished and settings to control how each type of node is displayed. Permissions to create and edit each type of node can also be assigned to different user roles; for example, users with the “blogger” role could create “Blog entry” nodes, but only “administrator” or “editor” users could create “News” nodes.
Note
Nodes can also store revision information detailing each change that’s been made since they were created. If you make a mistake (deleting an important paragraph of the “About Us” page, for example), this makes it easy to restore a previous version.
Drupal comes preconfigured with two types of nodes: “Page” and “Story.” There’s nothing special about them—they offer the standard features all nodes share and nothing more. The only differences between those two types of nodes are their default configuration settings. “Page” nodes don’t display any information about the author or the date on which they were posted. They’re well suited to content like “About Us” and “Terms of Service,” where the original author is irrelevant. “Story” nodes do display that information, and are also set to appear on the front page of the site whenever they’re posted. The result is a blog-like list of the latest stories on the site.
You can use Drupal’s content administration tools to create other “simple” node types yourself. Many administrators create a “news” or “announcement” node type to post official announcements, while other contributors can post story nodes. What happens, though, if you need to store more information than “title” and “body content?” Plug-in modules can add to Drupal’s content system new kinds of nodes that offer more features. One example (which comes with Drupal) is the “Poll” module. When users create new “Poll” nodes, they create a list of poll questions rather than the usual “body” content. Poll nodes, when they’re displayed to visitors, appear as voting forms and automatically tally the number of votes for each question.
Additionally, other modules can add to nodes’ properties such as comments, ratings, file upload fields, and more. From the control panel, you can specify which types of nodes receive these features. Figure 1-6 illustrates this concept.
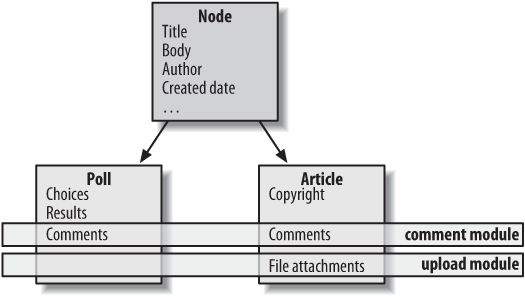
The idea that new modules add properties and build on top of the node system means that all content in Drupal is built on the same underlying framework, and therein lies one of Drupal’s greatest strengths. Features like searching, rating, and comments all become plug-and-play components for any new type of node you may define, because under the hood, Drupal knows how to interface with their base elements—nodes.
Using plug-in modules to add new types of nodes—or to add additional fields to existing node types—is a common task in Drupal. Throughout the book, we’ll be covering a handful of the hundreds of plug-in modules and you’ll learn how to build complex content types using these basic tools.
Ways of Organizing Content
Another important building block is really an entire toolbox of techniques for organizing the nodes that make up your site’s content. First-generation websites grouped pages using folders and directories. Second-generation sites use separate scripts to manage and display different kinds of content. Drupal, though, maintains almost everything as a node. How can you break your site up into separate topical sections, user-specific blogs, or some other organizational scheme?
First, each individual node on your site gets its own URL. By default, this URL is something like http://www.example.com/node/1. These URLs can be turned into user-friendly paths like http://www.example.com/about using Drupal’s built-in Path module. For organizational purposes, all of these nodes are treated as a single “pool” of content. Every other content page on your site—topical overviews, recent news, and so on—is created by pulling up lists of nodes that match certain criteria and displaying them in different ways. Here are a few examples:
- The front page
By default, the front page of a Drupal site is a blog-like overview of the 10 most recently posted stories. To build this, Drupal searches the pool of content for nodes with the “Published” flag set to
true, and the “Promote to front page” flag set totrue. In addition, it sorts the list so that nodes with the “Sticky” flag are always at the top; this feature is useful for hot news or announcements that every user should see.- The Taxonomy module
We mentioned earlier that plug-in modules can add new pieces of information to nodes, and that’s exactly what Taxonomy does. It allows the administrator of a site to set up categories of topics that nodes can be associated with when they’re created, as well as blog-style free-tagging keywords. You might use this module to create a predefined set of “Regions” for news stories to be filed under, as well as “Tags” for bloggers to enter manually when they post. The Taxonomy module calls all of these things “terms,” and provides a page for each descriptive term that’s used on the site. When a visitor views one of these pages, Drupal pulls up a list of all the nodes that were tagged with the term.
- The Blog module
Drupal’s built-in Blog module implements a multiuser blogging system by doing just three things. First, it adds a new node type called “Blog post.” Second, it provides a listing page at http://www.example.com/blog that displays any nodes of type “Blog” that also have their “Published” flag set to
true. (If a blog post has its “Published to front page” flag set totrue, it will show up on the front page as well; Drupal never hides content on one page just because it appears on another.) Third, it provides a custom page for each user on the site that displays only blog posts written by that user. http://www.example.com/blog/1, for example, would display all blog post nodes that are published and were written by User 1—the administrator.
Drupal comes with several other modules that provide different ways of organizing nodes, and hundreds of plug-in modules can be downloaded to organize your site in a variety of ways. The important thing to remember is that almost all “pages” in Drupal are one of two things: a specific content node, or a list of nodes that share a particular set of properties.
Types of Supporting Content
In addition to content and listings of content, there are also various ways to supplement the content on the page. Two such types of supporting content included with Drupal core are comments and blocks.
Comments are merely responses by a user to a piece of content, and exist only in relation to that content. Users may post comments to add their thoughts to the subject matter within a node, as they often do when a particularly controversial subject comes up on a blog entry or forum topic. Like nodes, but to a lesser extent, comments can be expanded with contributed modules to have additional features such as ratings or file upload fields.
Comments provide a large number of options to tweak: comments can be displayed in a threaded or flat list, comments can be sorted with the newest or oldest on top, anonymous users can be allowed to or prevented from leaving comments, and if anonymous comments are enabled, contact details can be required or optional.
Blocks are widgets that fit into areas such as the sidebars, footers, and headers of a Drupal site. They’re generally used to display helpful links or dynamic lists such as “Most popular content” or “Latest comments” and similar items. The users building block controls information about and access for your site’s visitors; nodes take center stage displaying content; and blocks help give a single piece of content some context in the structure of your site.
Many times, blocks will display different content, depending on which user is currently logged in: a “Comments by your buddies” block, for example, might display a list of posts by users that the current visitor has added to their Buddies list. Each user who logs in will obviously see a different list. Additionally, blocks may be configured to show up only on certain pages, or to be hidden only on certain pages.
Getting Help
It’s easy to focus only on the functionality you get for free with an open source application. But it would be a mistake to forget that the Drupal community itself is another vital building block for your website!
As you go through the hands-on examples in this book, you might run into some issues particular to your installation. Or, issues might be created as new versions of modules are released. Fortunately, the Drupal community has a wealth of resources available to help troubleshoot even the nastiest error you might encounter:
The Drupal handbooks at http://drupal.org/handbooks contain a wealth of information on everything from community philosophies to nitty-gritty Drupal development information.
The Getting Started guide at http://drupal.org/getting-started contains some particularly useful information to help get you through your first couple of hours with Drupal.
The Troubleshooting FAQ at http://drupal.org/Troubleshooting-FAQ has useful tips and tricks for deciphering error messages that you might encounter.
For more one-on-one help, try the Support forums at http://drupal.org/forum/18 for everything from preinstallation questions to upgrade issues.
If your question is about a specific module, you can post a “support request” issue (or a “bug report” if it’s a blatant problem) to the module’s issue queue, which reaches the module’s maintainer. A helpful video on how to maneuver around the Drupal.org issue queues is available from http://drupal.org/node/273658, and issue queues are also discussed in Appendix B.
There’s a #drupal-support IRC channel on irc.freenode.net if you’re more of the chatty type.
Warning
Unlike #drupal-support, the #drupal channel on irc.freenode.net is not a support channel. This channel is a place for developers to get coding help and for other contributors to actively brainstorm and discuss improving the Drupal project as a whole. By all means, participate here to get involved in the community, and ask your coding-related questions, but remember that questions like, “Where is the option I toggle to do this?” and “What module should I use for that?” will make people a bit cranky.
When asking for help, it’s always best to do as much research as you can first, and then politely ask direct, to-the-point questions. “Foo module is giving me the error ‘Invalid input’ when I attempt to submit ‘Steve’ in the name field. I tried searching for existing solutions, and found an issue at http://drupal.org/node/1234 filed about it, but the solution there didn’t fix it for me. Could anyone give me some pointers?” will get far better, faster, and more meaningful responses than, “Why doesn’t Foo module work? You developers are useless!” or “How can I build a website with Drupal?” Oftentimes, you’ll probably find that during the process of typing out your question in enough detail for someone else to answer it, you come up with the solution yourself!
Conclusion
In this chapter, you’ve learned what Drupal is. You have seen the history of websites and content management to better understand the challenges inherent in keeping a growing site healthy. We’ve examined the conceptual building blocks that Drupal uses when building next-generation sites, as well as how they fit together. We’ve also seen numerous ways to get help if you’re stuck. In the following chapter, we’ll put these pieces together to make your first Drupal website!
[1] For more on the open source software movement, please see http://opensource.org—which, incidentally, is also a Drupal site.
Get Using Drupal now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

