Chapter 1. Programming on the Web
You probably have been using the Web now for many years to read news, shop, gather information, and communicate with your friends. You start your web browser (Internet Explorer, Firefox, Safari, Opera, Chrome, or another) and navigate around the Web. You may even have a MySpace page or a blog somewhere and have written a bit of HyperText Markup Language (HTML) to customize the look of your page. Some web pages are just flat content, where you see the exact same thing every time you visit that page, and other pages have highly dynamic content and display something very different based on your actions or what you type.
In this book, you will learn how to write applications that generate those dynamic web pages and how to run your applications on the Google App Engine infrastructure.
A perfect example of an interactive and dynamic page is Google Search (Figure 1-1).
When you come to Google Search, you can type anything into the search box and click the Google Search button. Figure 1-2 shows search results for your request.
Google Search is a “web application”—it is software that runs on the Web. The Google Search application takes as its input many requests per second from web browsers around the world. When the Google Search application receives the request, it springs into action looking for web pages in its large datastore that match the search terms, sorts those pages based on relevance, and sends an HTML page back to your browser, which shows you the results of your search.
The Google Search engine is quite complex and makes use of a vast amount of data around the Web to make its decisions about what pages to show you and in what order to present your pages. The web applications that you write will generally be much simpler—but all the concepts will be the same. Your web applications will take incoming requests from browsers and your software will make decisions, use data, update data, and present a response to the user.
Because you will be writing a program, rather than just writing documents, the response that you give to the user can be as dynamic and as unique or customized for each user as you like. When a program is building your web pages, the sky is the limit.
The Request/Response Cycle
For you to be able to write your web applications, you must first know a few basic things about how the Web works. We must dig a little deeper into what happens when you click on a page and are shown a new page. You need to see how your web application is part of the cycle of requesting and displaying web pages. We call this the HyperText Transport Protocol (HTTP) request/response cycle.
The request/response cycle is pretty easy to understand. It starts when the user clicks on a web page or takes some other action and ends when the new page is displayed to the user. The cycle involves making a request and getting a response across the Internet by connecting to software and data stored in data centers connected to the Internet (Figure 1-3).
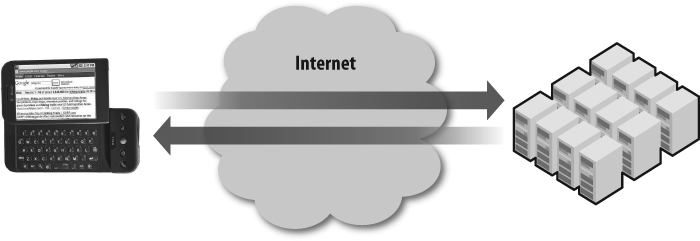
Although you probably have a general notion as to what is going on when you are using your web browser to surf the Web, before you can really develop web applications, you need to understand the process in more detail (Figure 1-4).
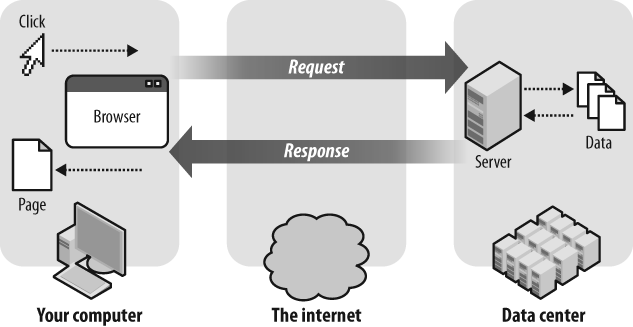
Your browser looks at the Uniform Resource Locator, or URL (i.e., http://www.google.com/search) that you clicked on. It then opens an Internet connection to the server in the URL (http://www.google.com) and requests the /search document. It also sends any data that you have typed into form fields along with the request for the /search document.
When your browser makes the connection, requests a document, and sends any input data that you have typed, it is called an “HTTP request” because your browser is requesting a new document to display.
The HTTP request information is routed across the Internet to the appropriate server. The server is usually one of hundreds or thousands of servers located in one of Google’s many data centers around the world. When the server receives the request, it looks at the document that is being requested (/search), which user the request is coming from (in case you have previously logged in with this browser), and the data from any input fields. The server application then pulls data from a database or other source of data, produces a new HTML document, and sends that document back to your web browser. When your web browser receives the new HTML document, it looks at the HTML markup and CSS (Cascading Style Sheets), formats the new page, and shows it to you.
Although there are many steps that take a few paragraphs to describe, the whole process from clicking on one page to the display of the next page usually happens in less than a second. Of course, if your network connection is down or very slow or the server is running slowly, the process happens in “slow motion,” so the fact that there are several steps is a little more obvious as the progress bar crawls across your screen while your browser is waiting for the request to be sent and the response to be retrieved over your slow Internet connection.
If the page references images or other files in the HTML, your browser also makes separate requests for those documents. Many browsers will show a status bar as each of these requests/response cycles are processed by showing a running count on the browser’s status bar as the files are retrieved:
Retrieving "http://www.appenginelearn.com/"-Completed 5 of 8 items.
This message simply means that to display the page you requested, your browser needs to retrieve eight documents instead of just one. And although it is making progress, so far it has received only five of the documents. A document can be an HTML page, CSS layout, image file, media file, or any number of different types of documents.
In a sense, the HTTP request/response cycle determines the overall layout of the book: to build a web application, you need to have a general understanding of all aspects of the request/response cycle and what is happening at both ends (browser and server) of the request/response cycle (Figure 1-5).
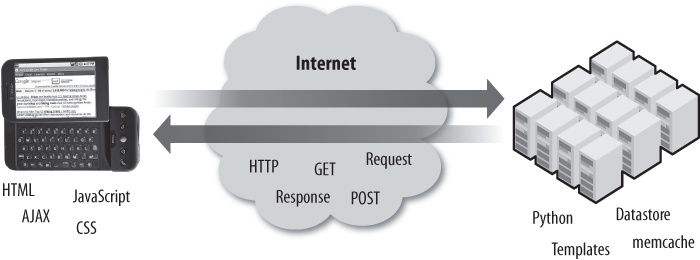
You need to learn about how the browser operates using HTML and CSS so that you know how to properly format web pages for display in the browser. You also need to learn about how to add interactivity to web pages using JavaScript and AJAX (Asynchronous JavaScript and XML).
You need to understand the mechanics of how the browser makes its requests using the HTTP protocol—in particular, the different types of requests (GET or POST) and how to handle incoming data entered by the user on forms or files to be uploaded as part of the request.
Inside of the server, you need to learn the Python programming language, the Google Datastore facility, how to generate Dynamic HTML easily using templates, and how to use the Google memory cache to make sure that your applications continue to be fast when being used by many users at the same time.
The browser technologies and HTTP topics are generic and apply to programming in any web application environment such as Ruby on Rails, PHP, Java Servlets, Django, Web2Py, or any of the literally hundreds of other web application frameworks. Learning these topics will be of use in any web programming environment.
Most of this book focuses on the unique aspects of programming in the Google App Engine framework. We cover Python, templates, the Datastore, and the memcache to give you a solid introduction to the App Engine environment and the Google Cloud.
What Is Google App Engine?
I recently attended a meeting at Google where they were giving away stickers for our laptops that said, “My other computer is a data center” (Figure 1-6). The implication was that we were learning to use Google App Engine, so we no longer needed any web servers or database servers to run the production instances of our applications. Our “other computer” was actually a bunch of computers and storage running somewhere deep inside of one of the many Google data centers around the world.

Google’s App Engine opens Google’s production infrastructure to any person in the world at no charge. Much like Google gives us all free email with an amazing amount of long-term storage, we now have the ability to run the software that we write in Google’s data centers (i.e., in the Google “cloud”).
What Is a “Cloud”?
- The term “cloud” is often used when we know how to use something at a high level but we are conveniently shielded from the detail about how it actually works. We know that we have ways to work with and use things in the cloud, but we don’t bother looking at what is going on inside. Sometimes we refer to this concept as “abstraction&rdquo
- we deal with something complex and detailed in a very simple and abstract way and are unaware of the many intricate details that may be involved. For most of us, the automobile is an abstraction. We use a key, steering wheel, gearshift, gas pedal, and brake to drive around and we seldom worry about the thousands of highly specialized parts that are combined to produce the car. Of course, when your car breaks down or performs badly, those details begin to matter a lot. And when we do not have the skills to address the details, we hire someone (a mechanic), paying the professional to dig into those details and give us back a nicely working “abstraction”—and of course a hefty bill listing all the details within the abstraction that needed some work.
The Internet is another abstraction/cloud. The Internet is often represented as a cloud (Figure 1-7) because although we know that all the computers are connected together, most people are generally unaware of the internal details of the links and routers that make up the Internet at any given moment. So the image of a cloud is a great way of representing all that hidden detail inside. We simply treat the Internet as an “abstraction” and use it—ignoring all the complex internal details.
Why Did Google Build App Engine and Give It Away for Free?
The stated purpose of the creation of Google App Engine is to make the Web better. By empowering millions of new software developers to produce new applications for the Web, Google is hoping to encourage the growth of the Web. Another advantage of Google letting us see and use their scalable infrastructure is that we will help them find ways to improve their infrastructure and make use of it in novel ways. By opening App Engine up to the public, thousands of new bright developers are poring over every aspect of Google App Engine, testing, checking, poking, prodding, finding problems, and suggesting fixes and improvements. This process greatly builds the community of knowledge around the Google software environment, while keeping Google’s costs low.
And although it is likely that companies like Yahoo!, Amazon, and Microsoft will counter with highly abstracted application clouds of their own, Google will have had the market to themselves for some time, building a lead and gaining momentum with developer loyalty. Once developers get used to something that works well, they usually are not in a hurry to change. When or if the other companies enter the application cloud market, they will certainly be playing catch-up.
What Is the Google Infrastructure Cloud?
In order to support its worldwide applications such as Google Search and Google Mail (Gmail), Google owns and maintains a number of large data centers around the world, each with thousands of computers and extremely fast networks connecting the data centers. There is plenty of speculation and amateur research that tries to track the number and locations of the Google data centers—but it is pretty safe to say that there are more than 20 large Google data centers scattered around the world. Figure 1-8 is an artist’s depiction of what this might look like (please note that these locations are only approximate and not precise).
Google carefully engineers every aspect of these centers, based on the number of users of their products, the penetration of Internet connectivity in various regions, the patterns of use over time, and many other factors. As usage grows and shifts, Google production engineers add or adjust network and computing resources to meet the changing demand.
Because Google buys so many computers and buys computers continuously, Google has carefully studied the cost, performance, reliability, energy use, and many other factors, to make sure that their investments in data centers are done wisely. As a result, the Google production infrastructure is so complex and so dynamic that even the internal programming teams at Google have no chance of keeping track of all the details and changes in the configurations in all the data centers. It would be a maintenance nightmare if the developers of Google Mail had code that depended on running on a particular server or even running in a particular data center. Any server can go away or be rebooted at any moment. It might even be possible for a large part of a data center to be shut down for maintenance or because of some significant power outage or other local issue.
So Google has developed a software framework—an abstraction layer—that hides all of the detail about where data is located or which software is running on which server in which data center. Software like Google Mail simply says, “I need the mail for csev@umich.edu” and the framework finds it and delivers it to the application. Because the Google Mail application does this pretty quickly for users anywhere in the world, you can bet that this abstraction/framework is very clever and very fast.
Once the framework that hides location and server detail from the programmer is in place, Google has great flexibility in terms of dynamic reallocation of resources to meet changing needs and demands. As one part of the world goes to sleep and another starts to wake up, data, software, and computation can be moved around the world, following the sun—and in those countries where people are sleeping, data centers can be dynamically reallocated to tasks such as spidering the Web, building indexes, performing backups, doing maintenance, or handling overflow load from servers in regions where the users are awake.
The software developers are completely unaware of the production configuration of the data centers, as it is changing on a moment-to-moment basis.
If you are thinking, “Wow—that must be pretty complex,” you are right. One very important “competitive advantage” that distinguishes these mega-web companies is how well they can deploy cost-efficient scalable resources and provide quick, consistent, and reliable responses to users anywhere in the world. Every time we click their applications and search boxes, they make revenue, as we look at their ads all day long.
Enter the Application Engine
Note
This section is conjecture—it is not based on any internal knowledge of Google’s approach or development.
For many years, Google had two main applications—Search and Mail. There were always a lot of secondary Google applications like Video or Sites, and Google internally encouraged a lot of experimentation. Small teams would form and try to build something that the world might find interesting. Google is legendary in labeling new services “Beta” to emphasize that they are under construction and will be improved upon for a long time. Because Google is committed to exploring innovative ideas, it probably tried to make the Google infrastructure increasingly easier to use for these new employees. It is also important to make sure that when a new application is introduced into the production environment, it is not allowed to consume resources in a way that would harm other production applications. So the cloud makes it easier for new employees to develop applications and protects the applications from each other by monitoring application activity and shutting down or throttling applications that “misbehave.”
Once this approach was well understood for Google employees, it would have been a very logical step to see whether the environment could be further documented and ruggedized for use by the general public. Although it is almost certain that the actual Google applications written by Google employees can make use of resources that App Engine applications cannot access, it also is quite likely that the internal and external developer environments bear a striking similarity.
Your Application Must Be a Good Citizen in the Google Cloud
Because you are running your application on the Google infrastructure, along with the rest of the App Engine applications and the rest of the Google Applications, you need to follow a few rules. If your application misbehaves, it might be punished. The good news is that because the App Engine environment is completely “sandboxed,”[1] App Engine blocks you from doing nearly all the things that Google does not want you to do. The Python environment that you run in App Engine has disabled the operations considered “unsafe” or “insecure.” For example, you cannot write to the disk on the servers (you can write to the Datastore—just not to the disk on your local server). You cannot open a direct network connection from your App Engine application, either, as you are likely behind some of Google’s firewalls; if you could make arbitrary network connections, you might be able to cause a bit of mischief with Google’s other applications. You can retrieve the contents of a URL—you just cannot make your own network connections. These limitations are just commonsense rules to make sure that everyone lives happily together inside the Google cloud.
Google automatically monitors all the running applications (including yours) to make sure that no application uses so many resources that it might have a negative impact on other applications running in the cloud. Google measures the time it takes for your application to respond to each web request. When Google notices that your program is responding slowly or taking too many resources to respond to the request, the request is aborted. If your application abuses resources regularly, you might find yourself throttled or shut down all together. Google is not so concerned when your application is using lots of resources because it is very popular but is more concerned with ensuring that each time someone clicks on your application you use a reasonable amount of resources to handle each “click” or web request. It generally wants your application to be well-written and to make good use of the Google resources.
If your application begins to use a lot of resources because of increasing popularity, Google will happily start charging you for the resources.
How the Cloud Runs Your Application
The best explanation of how the Google cloud works internally is that everything is “virtual.” If you look at wired land-line telephones, the prefix of a phone number generally indicates something about the physical geographic location of the phone. On the other hand, many cellular phones have the same prefix, regardless of their physical location. When you make a call to a cellular number from a wired phone, the call is routed across wires into the cellular network and then somehow the cellular network “tracks down” your cellular phone and routes the call to the appropriate cellular tower that is physically near your phone.
In a noncloud environment, the Internet works like the wired phone network. Web servers have a fixed and known location. They are assigned an Internet Protocol (IP) address based on that known location, such as 74.208.28.177. Your IP address is like a phone number—the entire Internet knows where that IP address is located and can route packets across the links that make up the Internet to get the data to that physical server. You also assign the server a domain name, like www.dr-chuck.com, which lets Internet software use the Domain Name System (DNS) resolution to look up the numeric IP address (74.208.28.177) associated with the domain name as a convenience.
The Google cloud is more like a cellular network. Programs and data “roam around” the world and the web requests (like cellular calls) somehow find their way to your software, regardless of where in the world your software happens to be running. If you have an App Engine application running at a domain name of cloudcollab.appspot.com, Google can give this domain name a different IP address depending on what region of the world you are coming from. In the eastern United States, you might get one numeric IP address, and in South Africa, you might get another numeric IP address. Once Google gets your request into the Google network, it figures out which data center(s) can run your application or perhaps which data centers are already running your application. It probably picks a data center that is some combination of reasonably close and not currently overloaded or perhaps the data center where the data for your application is stored. If all of a sudden your application experiences a spike of traffic in the United Kingdom, Google will likely copy your program and some of your data to one of its data centers there and start your application in that data center and pass the incoming requests from the United Kingdom to your program running in the United Kingdom.
If your application is very popular, it might be running in a number of different data centers at the same time. Or if your application gets 10 requests per hour, it probably is not running anywhere most of the time. When Google sees a request for your application, it starts up a single copy somewhere and gives the request to your application. Once your application finishes the request, it is shut back down to conserve resources.
The most important point of this is that your application has absolutely no idea if or when it is running, where geographically it is running, and how many copies of it are running around the world. Google takes care of all those details for you completely and (thankfully) hides them from you. Somehow the requests from your users make it to your application and back to the end user—Google takes all the responsibility for making this happen quickly and efficiently.
Running an application in the cloud is kind of like flying business class across the Pacific Ocean between Australia and the United States. You are vaguely aware that you are going really fast inside of a highly complex device that you barely understand. The pilots, crew, maintenance people, chefs, logistics staff, traffic controllers, and gate agents all are making sure that your trip happens efficiently and comfortably—and that it is uneventful. All you know is that you sit in a recliner, watch a movie, eat a nice filet mignon, have a glass of red wine, lay the seat flat, sleep for a few hours, and wake up refreshed on a different continent.
Why You Really Want to Run in the Cloud
You might initially think that you don’t want to run in the Google cloud because you want to make your own decisions and control your own destiny. You might want to run your own servers in your own facility and make all the decisions about your application. Perhaps you just like walking into a server room and seeing the hardware that is running the application. Although this sense of control might sound appealing at first, it is really just a lot of trouble and energy that does not advance the cause of your application. Here are a few of the things that you have to worry about when you run on your own servers: what operating system should I run? What version of the operating system is the most reliable? When do I apply vendor patches (especially those pesky security patches)? How do I protect my system from intruders? Do I need a firewall to protect my servers? How do I monitor my servers to detect when an intrusion happens and then how do I get notified? How far do I have to drive to the server room to reformat and reinstall the software at 4:00 a.m. so that it is back up by 10:00 a.m.? What database do I run? What version? What patches? Should I upgrade the memory of my database server, or should I add an additional disk to the RAID controller? Can I use a single database server, or do I need to cluster several database servers? How does the clustered database server get backed up? How long does it take to restore my database when there is a hardware problem with the database server’s disk drives? How many application web servers do I need? I know that my application’s peak usage is from 7:00 p.m. to 9:00 p.m. each day. Do I buy enough hardware to handle that peak load, or do I buy a little less hardware and just let the servers slow down a bit during the 7:00 p.m. to 9:00 p.m. period? If my application is so popular that it is used both in the United States and Europe, do I need to find a data center in Europe and put some hardware in Europe so that all the European users see a quick response time? When should I upgrade my hardware? Should I add more hardware and keep the old hardware or simply pitch the old hardware and install all new hardware? How much energy does my hardware take? Is there a way to reduce the energy footprint of my hardware?
And on and on. These problems do not go away just because you run on the Google infrastructure. But they are Google’s problems, not your problems. You have outsourced these and hundreds of other subtle issues by running a production facility at Google. Google has some of the brightest production engineers in the world, who are very good at solving these problems and doing so very efficiently.
Although Google will charge you when your application begins to use significant resources, there is virtually no way that you could build the same scalable, worldwide, reliable, redundant, and efficient production environment anywhere near as cheaply as you can purchase those services from Google.
It is important to note that although Google App Engine is very exciting, because it is freely available to anyone to use and explore, there are many other available options for hosting applications on the Web. You should carefully investigate the appropriate production solution for your particular application.
The Simplest App Engine Application
You should consult the appendixes in this book for instructions on how to install Google Application Engine and run your first trivial application in Python. Once you have the App Engine environment installed, your first application consists of two files.
The first file is named app.yaml, and its purpose is to describe your application to App Engine:
application: ae-00-trivial version: 1 runtime: python api_version: 1 handlers: - url: /.* script: index.py
I will cover the details of this file later; at a high level, it names the application and uses an asterisk as a wildcard, matching any string of characters so as to route all the incoming document requests (i.e., URLs) to the program named index.py.
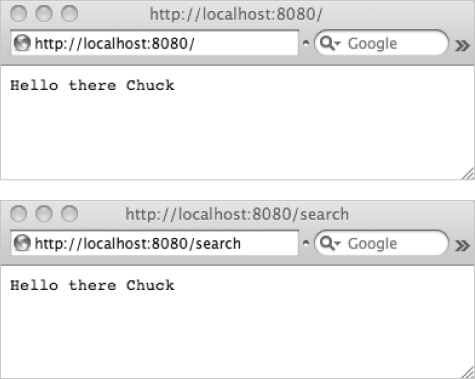
The index.py file consists of three lines of Python:
print 'Content-Type: text/plain' print '' print 'Hello there Chuck'
The first line of the response is a header line, which describes the type of data being returned in the response. The second line is a blank line to separate the headers from the document, and the third line is the actual document itself. In effect, regardless of which document your browser requests, the program has a very simple and single-minded response, as shown in Figure 1-9.
Although this application is trivial, it can be deployed in the Google App Engine production cloud.
Summary
Welcome aboard Google App Engine. Your application will run in Google’s best-of-breed data centers around the world. Google engineers take all the responsibility for the production environment for your application. All you need to worry about is whether your application works well, makes efficient use of resources, and makes your users happy.
If your application goes viral and usage takes off, Google’s engineers swing into action, making sure that you have all the resources that you need and making use of the resources in Google data centers around the world.
If your application does not take off and is just a fun little place for you to putter around and experiment with your own creative ideas and share them with a few friends, Google lets you use their production infrastructure for free.
Once you have created and deployed your App Engine application, perhaps you too will need to add a sticker to your laptop that says, “My other computer is a data center.” Or perhaps it would be more appropriate to have a sticker that says, “My other computer(s) is/are somewhere in one or more world-class data centers scattered around the world.” (You might need to buy a bigger laptop for that one, though.)
Exercises
- Explain how your responsibility as a developer changes when your application is hosted in Google’s cloud environment versus when you build and support your own dedicated hosting facility.
- Briefly describe the HTTP request/response cycle. What does it mean when your browser retrieves 40 documents to display your page? What are those 40 documents?
- What is the purpose of the “handlers” entry in the app.yaml file?
[1] The term sandbox is used to indicate that multiple applications are kept in their own little sandbox—a place where it is safe to play without hurting others.
Get Using Google App Engine now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

