Web 2.0 patterns of interaction are more elaborate than the simple request/response interaction patterns facilitated by the client/server model of the original Web. Common Web 2.0 practices require that interactions reach deeper and into more capabilities than the web applications of the past. Fortunately, one of the Web 2.0 patterns—Service-Oriented Architecture (SOA)—allows capabilities to be exposed and consumed via services across disparate domains of ownership, making it much easier for the other patterns to operate.
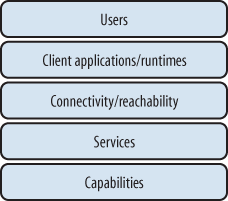
The evolution of the old client/server model into a five-tier model for Web 2.0, as shown in Figure 4-1, can be extended over time as new patterns and functionality are introduced into the equation. The Synchronized Web pattern, for example, requires that concepts such as connectivity and reachability be more carefully thought out in the core architecture, and these concepts need to be expanded to cover consistent models for objects, state, events, and more. The connectivity/reachability layer has to account for both online and offline states as well as the interactions between multiple agents or actors within a system’s architecture.
Note
Remember, Figure 4-1 is not an architecture; it’s an abstract model. The model’s purpose is to capture a shared conceptualization of the Internet as a platform for engaging people, processes, and applications. Readers should likewise not consider this the single authoritative model for Web 2.0. It is simply “a” model, and other models may be equally applicable.
This model reflects how Web 2.0 connects capabilities and users, recognizing several key evolutions beyond the simple client/server approach used in earlier web development. It may be reflected in implementations in a variety of environments. One implementation might be an enterprise sharing corporate information with its customers. A different implementation could apply the model to a peer-to-peer network. It could also be applied beyond the Internet itself. For example, software developers could use this model to expose the functionality encapsulated in a single class to other software components via a defined interface throughout the specific environment (connectivity/reachability) in which the interface exists.
The Internet is a platform used to connect devices (increasingly via “services”), but Web 2.0 is much more. As more and more types of devices are coupled to the Internet, the services have to be more carefully thought out in terms of their architecture, implementation, and descriptions. The client tier typically expressed in client/server models has been split in this model to emphasize three specific aspects of the client: the applications, the runtimes, and the users that are the ultimate targets of most interaction patterns. Because Web 2.0 is largely about humans as part of the machine, the model must reflect their existence. Many Web 2.0 success stories, such as Facebook, eBay, MySpace, and YouTube, involve a lot of human-generated content.
This model also acknowledges that the edge isn’t where it used to be. In recent years, we’ve seen refrigerators that connect to the Internet, personal digital assistants (PDAs) used to encrypt email, musicians around the world jamming with each other by plugging their guitars into their online computers, cars using the Global Positioning System (GPS) to query search services to find facilities in a specific locale, and more.
In the following sections, we’ll take a closer look at each layer in our Web 2.0 model.
The term capability, as used in this model, denotes any functionality that results in a real-world effect. That functionality does not necessarily have to reside in a computer; for example, a capability may involve a video game console detecting user input and turning it into a stream of bytes that provides another player with a gaming challenge. The model is not tied to any specific fixed implementation. Capabilities can be owned or provided by government departments, businesses of any size, or individuals with some backend functionality they wish to share with users (for example, the ability to share a text file with another person).
In a typical client/server architecture, during certain phases of communication a client assumes some of the roles of a server. Similarly, a user can be (or become) the provider of capabilities. Figure 4-2 shows a classic client/server interaction.
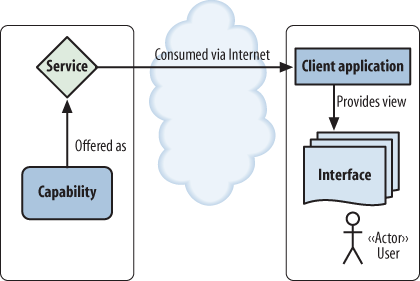
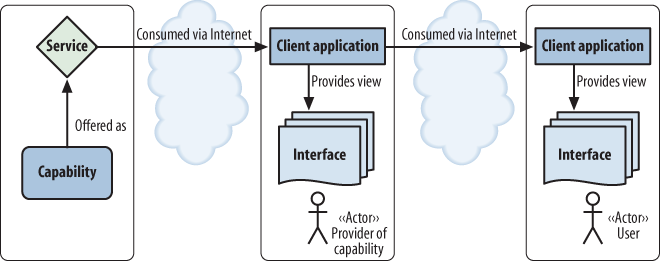
Figure 4-3 shows how all of that may change if the user is working with BitTorrent or similar P2P applications and protocols: the “client” in one transaction may subsequently become the provider of a capability that others consume.
The services tier makes capabilities available for people and programs to consume via a common set of protocols and standards. Service consumers do not necessarily know how the services are being fulfilled, as the service boundaries may be opaque. Services have a data model that manifests itself as data (payloads) going in and coming out of the service during its invocation life cycle. Even though the payloads themselves vary, the service pattern itself remains unchanged.
Many capabilities existed within modern enterprises before the Internet appeared, but this recently developed services layer is where many enterprises are starting to expose their core IT functionality. Each service provider, regardless of whether it is a corporate, government, or educational entity, follows a common pattern of using applications for some part of its core business functionality. During the first wave of the Web, much of this functionality remained largely unusable outside of an organization’s firewall. The first company websites were generally nothing more than static advertisements serving up very basic information to consumers on the client side.
Only a few industry leaders in 1996 and 1997 were sophisticated enough to incorporate customer relationship management (CRM) or enterprise resource planning (ERP) systems, databases of product inventory or support for email, forms, and blogs in their web systems. Siebel Systems, now part of Oracle, was one of those leaders. Siebel started out with a mandate to design, develop, market, and support CRM applications. Other companies, such as Amazon.com and eBay, built their CRM infrastructures from the ground up on the Web.
The architectural model behind the services tier is generally referred to as Service-Oriented Architecture.[42] Although it is often considered an enterprise pattern, SOA is an essential concept for the Internet as a whole. SOA is a paradigm for organizing and using distributed capabilities that may be under the control of different ownership domains. The reference model for SOA emphasizes that entities have created capabilities to solve or support solutions to the problems they face in the course of their business. One entity’s needs could be fulfilled by capabilities offered by someone else; or, in the world of distributed computing, one computer agent’s requirements can be met by a computer agent belonging to a different entity.
SOA accounts for the fact that these systems are distributed over disparate domains of ownership, which means that they require additional mechanisms (e.g., service descriptions in semantically meaningful dialects) in order to consume each other’s services. There isn’t a one-to-one correlation between needs and capabilities: the granularity of needs and capabilities varies from fundamental to complex, and any given need may require combining numerous capabilities, whereas any single capability may address more than one need. SOA is an architectural discipline that provides a powerful framework for identifying capabilities to address specific needs and matching up services and consumers.
Within SOA, if service interactions are to take place, visibility and reachability are key. Visibility refers to the capacity for those with needs and those with capabilities to see each other. This requirement can be met by using the standards and protocols common to the Internet. Service interactions are also facilitated by service descriptions that provide details about the service’s functions and technical requirements, related constraints and policies, and mechanisms for access or response. For services to be invoked from different domains, these descriptions need to be written in (or transformed into) a form in which their syntax and semantics will be interpretable.
In the services tier itself, the concept of interaction is the key activity of using a capability. Service interactions are often mediated by the exchange of messages, though it’s possible to have interactions that aren’t based on messages; for example, a service could be invoked based on some event, such as a timeout event or a no-response event. Interactions with capabilities may proceed through a series of information exchanges and invoked actions. Interaction has many facets, but they’re all grounded in a particular execution context, the set of technical and business elements that form a path between those with the capabilities and the ultimate users. An interaction is “an act” as opposed to “an object,” and the result of an interaction is an effect (or a set/series of effects). The resultant effect(s) may be reported to other system actors in event messages capturing the knowledge of what has transpired or other details about the state of a specific invocation.
A real-world example can illustrate how similar mechanisms function in different environments. Starbucks provides a service (it exchanges food and beverages for money). Its service has visibility (you can see and enter the store) and a service description (a menu written in a language you can understand). There is a behavior model (you stand in one line and place your order, pay the cashier when your order is accepted, and then stand in another line to receive the goods you bought) and a data model (how you interact, exchange currency, and so on). In one execution context (say, in Canada), the signs may be displayed in both French and English, you’ll pay with Canadian currency, and you’ll probably need to keep the door closed to keep out the cold weather. In another execution context (perhaps at a Starbucks in a hotel near the equator), the prices may be in a different currency, you may order in a different language, and you may not have to actually exchange money; the charges may be billed to your hotel room. Although the service is the same at a higher level of abstraction, the business context varies. Consumers, therefore, must fully understand the legal and real-world effects of interacting with services in a specific execution context.
Architects also generally want to distinguish between public and private actions and realms of visibility. Private actions are inherently unknowable by other parties, yet may be triggered by publicly visible service interfaces. Public actions result in changes to the state that is shared between those involved in the current execution context and, possibly, others.
Support for private actions is one of the key characteristics of services. Such actions are handled with “managed transparency.” A service performing private functions that consumers cannot see hides the implementation of the capability it’s delivering from the service consumers or users. This opacity makes it possible to swap underlying technologies when necessary without affecting the consumer or user tier (those who consume the services). When implementing managed transparency, the service designers consider the minimal set of things consumers need to know regarding what lies beyond the service interface to make the service suit their needs. The declaration of what is behind a service is largely just a set of claims and cannot necessarily be monitored during runtime. Within reliable messaging frameworks such as the OASIS WS-RX[43] specification, service endpoints may “claim” that they’ve delivered a message payload to a final endpoint application, but there’s no way for the service consumer to validate this; it must rely on the service’s claims. That may seem like a problem, but the consumer being able to verify delivery would sidestep the service interface and possibly negate the benefits of SOA.
Another important concept of SOA from the OASIS standard is that of services having real-world effects. These effects are determined based on changes to shared state. The expected real-world effects of service invocation form an important part of deciding whether a particular capability matches the described needs. At the interaction stage, the description of the real-world effects shapes the expectations of those using the capability. Of course, you can’t describe every effect of using a capability, and in fact a cornerstone of SOA is that you can use capabilities without having to know all the details of how they’re implemented. A well-designed services tier might want to reflect a level of transparency that’s adequate for the purposes at hand, but it should be no more transparent than is necessary to fulfill its tasks.
The evolution toward a services tier in the Web 2.0 model represents a fundamental shift in the way the Internet works. This new paradigm forms the basis for many of the interactions considered “Web 2.0.” In the Mashup pattern, clients consume multiple services to facilitate their functionality. Software as a Service (SaaS) is a variation of the basic service packages in which functional units of computing are consumed via the service interface. Likewise, the rush to harness collective intelligence often involves making some capabilities available as services.
For interoperability on the wire to be possible, there must be some level of agreement on a set of protocols, standards, and technologies. The Internet became a visual tool usable by the average person when browsers that supported the Hypertext Transfer Protocol (HTTP) and Hypertext Markup Language (HTML) appeared. Browser development, making the Internet human-friendly, became a race. HTTP enabled data to be transmitted and HTML provided a foundation for declaring how data should be rendered visually and treated.
The Internet, like any network, has to have a common fabric for nodes to connect with each other. In the real world, we use roads, highways, sidewalks, and doors to reach one another. In cyberspace, protocols, standards, and technologies fulfill a major part of the infrastructure requirements. Additional mechanisms, such as the Domain Name System (DNS), specify how domain name servers can participate in a global federation to map domain names to physical IP addresses. From a user’s standpoint, search engines have become increasingly important in terms of visibility and reachability. You can’t use what you don’t know about, and you can’t use what you can’t reach.
So, how have reachability and visibility on the Internet evolved? Several web services standards have evolved, along with standards to serialize and declare information. HTTP today is a boring yet stable old workhorse. Its core functionality, in addition to being the basic way for browsers and servers to communicate, is to provide a solid foundation on which to implement more complex patterns than the basic request/response cycle.
The real technical (r)evolution here has been the advancement of web services standards to facilitate a new type of connectivity between users and capabilities—the application-to-application realm. These standards include Asynchronous JavaScript and XML (AJAX), the Simple Object Access Protocol (SOAP), Message Transmission Optimization (MTOM), the use of SOAP over the Universal Datagram Package (UDP) , Web Services-Security (WS-S), Web Services Reliable Exchange (WS-RX), and many others.
It’s not just data transmission that’s changing—there’s a lot more than HTML traversing the Web today. Many sites now offer RSS for syndication as well as Atom, and microformats make HTML at least somewhat machine-readable without requiring developers to go all the way to XML or RDF. Other sites have taken syndication to the extreme. For example, at http://www.livejournal.com/syn/list.bml, you can find a feed for just about any subject imaginable.
Each of these protocols and advancements has helped to spur the
development of new user experiences in the web realm. Perhaps the
single most common technology that most people equate with Web 2.0 is
AJAX. Breaking away from the old pattern of complete web pages as
single entities, AJAX lets developers build sites that can incrementally
update a web page or other information view. Though AJAX builds on
technologies such as JavaScript, the Document Object Model
(DOM), and Cascading Style Sheets (CSS), as well as the XMLHTTPRequest
object that had been lurking in browsers for years, the realization
that these pieces could be combined to change the web-browsing
experience was revolutionary. Developers were freed from the cage of
pages, and users experienced improved interaction with resources
without having to constantly move from page to page. AJAX shattered
the previous model in which each page request was treated as being
stateless, and no other requests were considered part of its
context.
The emergence of AJAX signified a pivotal moment where the Web started to grow up and caused a revolution for users. However, web services also play an important role in the reachability and visibility concept of the model in Figure 4-1. Many businesses require more than best effort messages (messages not considered 100% reliable). Reliable messaging is a term used to denote messaging behavior whereby messages will reach their destinations 100% of the time, with externally auditable results, or failures will be reported to the appropriate parties. While failures may occur, reliable messaging ensures that every single message has a known disposition and outcome; in absolutely no instance can a sender be unsure of the status of a specific message or set of messages.
Although reliable messaging dates back to at least the mid-1980s with systems such as ISIS and ANSAware in the academic field, the first web-based protocols for reliable messaging evolved out of an OASIS and United Nations (UN/CEFACT) set of standards called Electronic Business XML (ebXML).[44] The characteristics of the message exchange patterns in ebXML were modeled on the older reliable messaging patterns of Electronic Data Interchange (EDI). EDI value-added networks played an important role in ensuring message delivery and kept audit trails that both sender and receiver could use to ensure nonrepudiation (not being able to deny having sent a message) and recoverability (being able to bring the state of a business process back to the last known agreed state should a network fail during transmission).
Although the ebXML effort itself failed to achieve significant adoption, much of the thinking that went into ebXML shaped the functionality of the web services standards that followed, like the OASIS Web Services Reliable Exchange (WS-RX) Technical Committee’s work. The problem with basic reliable messaging is that it still concerns only individual messages. The WS-RX specification can create reliable messaging for groups of related messages and, in the process, can be implemented with a lower overhead than applying reliable messaging functionality to each message individually.
At a physical level, Internet connectivity may typically be achieved via CAT5 network cables and other high-speed fiber channels. As the Internet continues to evolve, however, more devices are being connected to it that use different physical means of signaling. We’re already seeing Internet-connected digital billboards, large-screen outdoor monitors, smart phones, PDAs, electronic paper, digital cameras, automobiles, mobile audio devices, and more. Each new model of interaction may require a different mode of physical delivery.
Wireless communication is becoming by far the most popular connectivity option. Many devices rely on technologies such as Wi-Fi, Bluetooth, and other protocols to connect to the Internet. This evolution is important to understand from an architectural perspective, given that it’s a strong driver for separating the actual Internet protocols (such as HTTP) from the underlying physical means of communication.
There are also some transport mechanisms that are not so obviously part of Web 2.0. We’ll take a look at those in the next few subsections.
Some of the physical transport media mentioned in the last section challenge common perceptions of the Internet. For example, how can paper interact with the Internet?
Let’s look at an example. A few years ago, Adobe developed a system for imprinting international trade documents with 2D barcodes. The barcode captures information from an electronic message and is then printed on a paper document. The entire message can then be reserialized as an electronic message by scanning the barcode and interpreting it into a stream of bytes.
Considering the Internet’s ability to impact the quality of life on earth, hooking people who do not have electricity or computers into the Internet is a daunting but important task. The 2D barcode on paper represents one way of thinking outside the box.
Ordinary bar codes printed on products also make it possible for users to gather more information about real-world products from wireless devices that take a picture of the bar code, send it to a service for processing, and thereby find out more about what the barcode identifies. The barcode wasn’t meant as a deliberate “message” to the user or the service, but it can easily be hijacked for different applications.
The low cost of storage for digital content has opened new frontiers for permanently and temporarily connected devices. Most of us tend to think of the Internet as an “always connected” high-speed bit pipe, but this is not the only model. If a transmission moves from such a pipe to a person’s computer and is transferred to a USB device that another system subsequently detaches and reads, it’s still part of the data transmission. (The same was true of floppy disks and CDs in earlier years.) It isn’t efficient or fast, but this is a pattern that has evolved in the physical layer of the Open Systems Interoperability (OSI) reference model stack during the Web 2.0 revolution.
Note
Jim Gray wrote an article about the so-called Sneakernet in 2007 that elaborated on why the economics of this concept were favorable to using network connections to transfer larger data packages, and Jeff Atwood further elaborated on the concept at http://www.codinghorror.com/blog/archives/000783.html.
The client tier of the old client/server model remains in the new Web 2.0 model with minimal changes, but some new issues are raised. First, the idea of SOA begs the question, “Why is everyone concentrating on the servers and not the clients for this new paradigm?” It’s very important to mitigate the client-side connectivity considerations for online and offline tolerance to deliver a rich user experience. Many new client-tier application runtimes have evolved out of the realization that a hybrid approach, somewhere between a browser and a desktop application, might be an indispensable model for developers in the future. Developments such as Adobe Systems’s Adobe Integrated Runtime (AIR)[45] and Sun Microsystems’s Java FX[46] have shown us that there is serious developer and vendor interest in exploring new models.
Figure 4-4 shows shifts on the part of both web-dependent and native applications to a new breed of client-tier applications that embody the best of both worlds. “RIA desktop apps” include traits from both old-school desktop applications and the latest web-delivered Web 2.0 applications, yet they also add some unique functionality. Typically, security models have kept applications delivered over the Internet from interacting with local system resources. The hybrid RIA ability to expand the basic security model to accomplish things such as reading and writing to local hard drives gives Web 2.0 developers an extended set of capabilities. AIR, formerly named “Apollo,” was the first development platform to reach into this void, and Sun’s Java FX and Google Gears soon followed.[47]
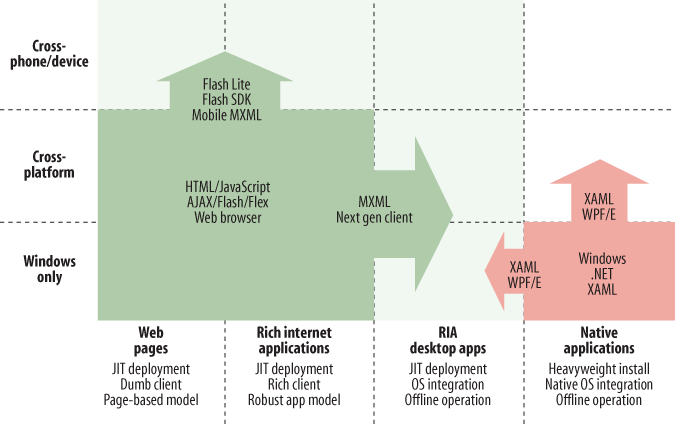
The patterns described in Chapter 7 raise additional questions about the functionality of clients. For example, the Mashup pattern describes a system whereby one client application can concurrently communicate with several services, aggregate the results, and provide a common view. The client may have both read and write access to data from different domains. Each service’s policies must be respected, and, in some cases, different models for security are required within one application. Similarly, the Synchronized Web pattern discusses state alignment across multiple nodes, where you need to be aware that events transpiring in one browser event might affect the states of multiple other components of a system. We discuss some of the core concepts for consideration within the client tier in Chapter 5.
Including the user as a core part of the model is one of the main factors that distinguishes Web 2.0 from previous revolutions in the technology space. The concept of a user, like the concept of an enterprise, is a stereotype that encompasses several different instantiations. A user can be an individual who is looking at a PDA screen, interacting with information via a telephone keypad, using a large IBM mainframe, using a GPS-aware smart device where data triggers events, or uploading video content to YouTube, among many other things. The user is the consumer of the interaction with the enterprise, and reciprocally, the provider of capabilities that the enterprise consumes. Users may also share the results of an interaction with other users, taking on the capabilities role in that exchange.
Users have become an integral part of the Internet’s current generation. In most early interactions and exchanges, users were typically anonymous actors who triggered events that resulted in interaction requests. A person opening a web browser on a home computer visited sites to read their content but didn’t exactly participate in them. Over time, websites made these interactions contextually specialized, taking advantage of knowing something about the user and making the user an important part of the overall model for Web 2.0. Even users who were just visiting provided information about their level of interest. Delivering a rich user experience requires understanding something about the user; otherwise, you’re just anonymously sending content that will likely be too generic to deliver such an experience. Users are becoming part of the machine, although not in the way fans of a cyborg (cybernetic organism) population might have envisioned. Our collective interactions with computer processes are becoming part of our collective human experience. This phenomenon is blurring the lines between the real and cyber worlds.
Examining the concept of harnessing collective intelligence illustrates one of the most notable aspects of how important the user is to Web 2.0. Ellyssa Kroski’s superbly researched and written article “The Hype and Hullabaloo of Web 2.0”[48] is a must-read, whether you’re a die-hard aficionado or a battle-hardened detractor. Ellyssa provides some practical examples of harnessing collective intelligence, one of the linchpin techniques of successful Web 2.0 software. The article describes this as when the “critical mass of participation is reached within a site or system, allowing the participants to act as a filter for what is valuable.”
This description is an understatement. The article gives some excellent examples of collective intelligence, but saying that harnessing collective intelligence allows web systems to be “better” is like saying that Moore’s Law states how computers become faster over time. It wasn’t for nothing that Einstein said that compound interest was the most powerful force in the universe. Harnessing collective intelligence has the same kinds of exponential effects.
The product that highly successful companies such as eBay, MySpace, YouTube, Flickr, and many others offer is in fact the aggregation of their users’ contributions. So, too, is the blogosphere. The pattern of user-generated content (the Participation-Collaboration pattern) is potent and immensely powerful. Thus, mastering architectures of participation to create real value will be essential to success in the Web of the future.
Here is a list of five great ways to harness collective intelligence from your users:
- Be the hub of a data source that is hard to recreate
Success in this context is often a matter of being the first entry with an above-average implementation. Runaway successes such as Wikipedia and eBay are almost entirely the sum of the content their users contribute. And far from being a market short on remaining space, lack of imagination is often the limiting factor for new players. Digg[49] (a social link popularity ranking site) and Delicious[50] (a social bookmarking site) offer models for how to become a hub quickly. Don’t wait until your technology is perfect; get a collective intelligence technique out there that creates a user base virtually on its own from the innate usefulness of its data, in a niche where users are seeking opportunities to share what they have.
- Gather existing collective intelligence
This is the Google approach. There is an endless supply of existing information waiting out there on the Web to be analyzed, derived, and leveraged. You can be smart and use content that already exists instead of waiting for others to contribute it. For example, Google uses hyperlink analysis to determine the relevance of any given page and builds its own database of content that it then shares through its search engine. Not only does this approach completely avoid dependency on the ongoing kindness of strangers, but it also lets you start out with a large content base.
- Trigger large-scale network effects
This is what Katrinalist[51] (a Web 2.0 effort to pool knowledge in the aftermath of Hurricane Katrina to locate missing people), CivicSpace[52] (an on-demand custom space for any social website), Mix2r[53] (a collaborative music-creation web space where people who have never physically met can add to and remix each other’s music), and many others have done. It is arguably harder to do than either of the preceding two methods, but it can be great in the right circumstances. With 1.2 billion connected users on the Web,[54] the potential network effects are theoretically almost limitless. Smaller examples can be found in things such as the Million Dollar Pixel Page,[55] an attempt to raise $1 million by building web pages of 1,000 by 1,000 pixels and selling each of them for $1. Network effects can cut both ways and are not reliably repeatable, but when they happen, they can happen big.
- Provide a folksonomy
Self-organization by your users can be a potent force to allow the content on your site or your social software to be used in a way that better befits your community. This is another example of the law of unintended uses, something Web 2.0 design patterns strongly encourage. Let users tag the data they contribute or find, and then make those tags available to others so they can discover and access resources in dynamically evolving categorization schemes. Use real-time feedback to display tag clouds of the most popular tags and data; you’ll be amazed at how much better your software works. It worked for Flickr and Delicious, and it can work for you too. (And even if you don’t provide an explicit tagging system, you may find that your users create one, like the #subject notation in Twitter.)
- Create a reverse intelligence filter
As Ellyssa pointed out, the blogosphere is the greatest example of a reverse intelligence filter, and sites such as Memeorandum[56] (a political spin reversal web page) have been using this to great effect. Hyperlinks, trackbacks, and other references can be counted and used to determine what’s important, with or without further human intervention and editing. Combine them with temporal filters and other techniques, and you can easily create situation-awareness engines. It sounds similar to the method of seeking collective intelligence, but it’s different in that you can use it with or without external data sources. Plus, the filter is aimed not at finding, but at eliding the irrelevant.
[42] SOA is formally defined as an abstract model within the Organization for Advancement of Structured Information Systems (OASIS) Reference Model for Service-Oriented Architecture.
[44] ebXML is described in more detail at http://www.ebxml.org.
[46] See http://java.sun.com/javafx/.
[47] See http://gears.google.com.
[49] See http://digg.com.
[50] See http://del.icio.us.
[51] See http://www.katrinalist.net.
[52] See http://civicspacelabs.org.
[53] See http://www.mix2r.com.
[56] See http://www.memeorandum.com.
Get Web 2.0 Architectures now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

