February 2006
Intermediate to advanced
826 pages
63h 42m
English
Perhaps the easiest way to think of the DOM is to think of the document tree . Let’s take the following XHTML document as an example:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Sample XHTML</title>
<meta http-equiv="content-type"
content="text/html; charset=iso-8859-1" />
<meta http-equiv="Content-Language" content="en-us" />
</head>
<body>
<h1>This is a heading, level 1</h1>
<p>This is a paragraph of text with a
<a href="/path/to/another/page.html">link</a>.</p>
<ul>
<li>This is a list item</li>
<li>This is another</li>
<li>And another</li>
</ul>
</body>
</html>This is a pretty basic web page, making use of a few different elements. If we were to visualize this as a document tree , it would look something like Figure 27-1.
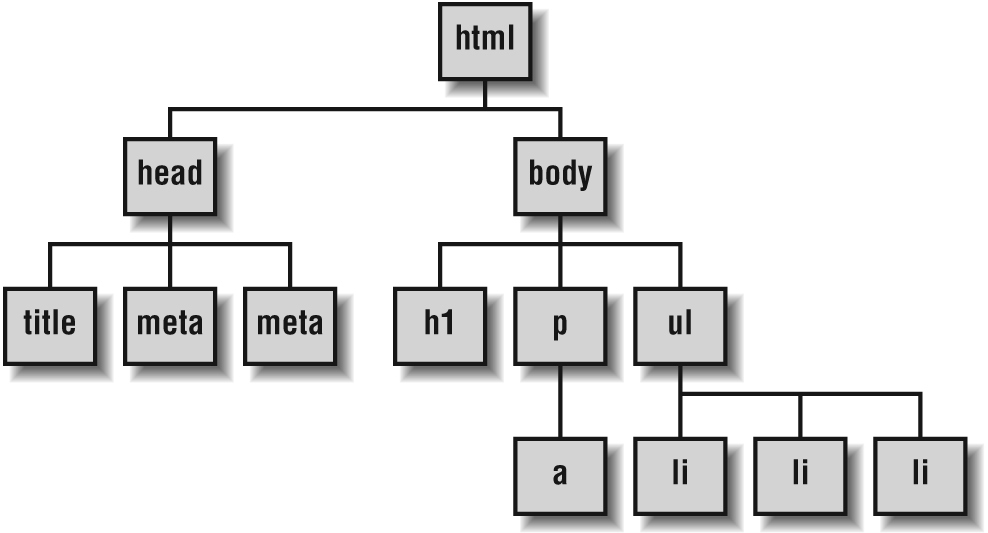
Figure 27-1. A sample document tree
A document tree like this is roughly akin to a very high level view of the DOM’s node tree.
Essentially, the DOM is a collection of nodes. These nodes usually take one of three forms:
Element nodes
Attribute nodes
Text nodes
These nodes are arranged in a hierarchy that we sometimes refer to using a familial model. In (X)HTML, the hierarchy begins with the html element, which is the root element, meaning it has no ancestors. In the above example, html has two child
nodes
(head