March 2025
Intermediate to advanced
352 pages
9h 37m
Spanish
Este trabajo se ha traducido utilizando IA. Agradecemos tus opiniones y comentarios: translation-feedback@oreilly.com
Una vez que empiezas a hacer web scraping, empiezas a apreciar todas las pequeñas cosas que los navegadores hacen por ti. La web, sin sus capas de formato HTML, estilo CSS, ejecución JavaScript y representación de imágenes, puede parecer un poco intimidante al principio. En este capítulo, empezaremos a ver cómo dar formato e interpretar estos datos desnudos sin la ayuda de un navegador web.
Este capítulo comienza con los fundamentos del envío de una solicitud GET (una solicitud para buscar, u "obtener", el contenido de una página web) a un servidor web para una página concreta, la lectura de la salida HTML de esa página y la realización de algunas extracciones de datos sencillas para aislar el contenido que buscas.
El código de este curso puede encontrarse en https://github.com/REMitchell/python-scraping. En la mayoría de los casos, las muestras de código están en forma de archivos de Jupyter Notebook, con extensión .ipynb.
Si aún no los has utilizado, los Cuadernos Jupyter son una forma excelente de organizar y trabajar con muchas piezas pequeñas pero relacionadas de código Python, como se muestra en la Figura 4-1.
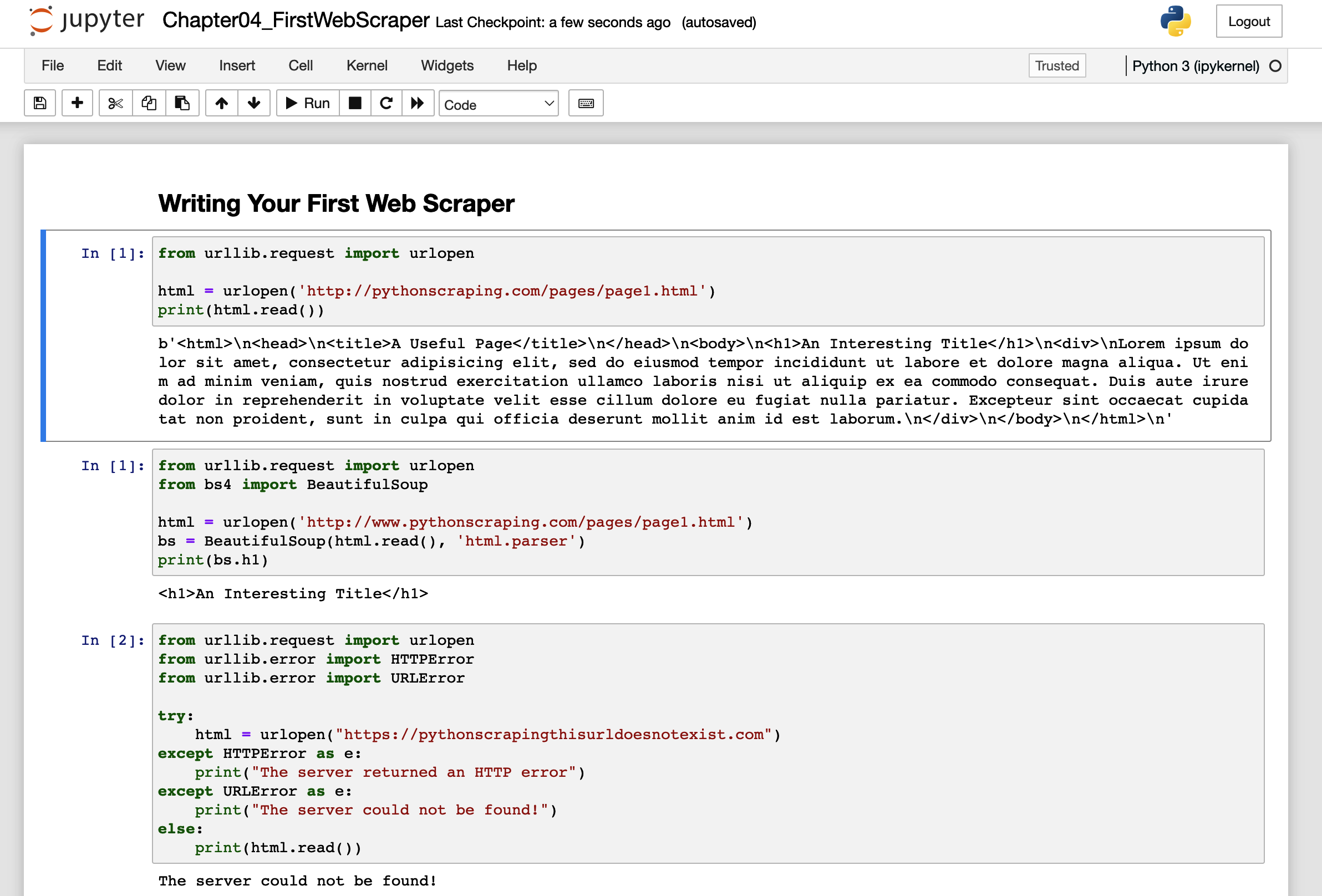
Cada fragmento ...
Read now
Unlock full access






