Before you get started analyzing, determine where the data will be coming from.
In the early days of web site measurement, there was only a single source of data, web server logfiles [Hack #22] . Generated automatically by web servers like Apache and Microsoft Internet Information Server, these flat text files were simply a report of which IP addresses were requesting which objects. At one point, a smart and enterprising soul realized that these files could be parsed and that the results could tell you roughly what people were doing on your web site. Some say, “In the beginning there were logfiles and they were good.…” Unfortunately, web server logfiles weren’t good enough.
People began to see problems creeping into their log-based analysis—missing information and requests that could in no way be coming from a human being—and gradually programmers realized that something better would be needed. Problems arose from the emergence of forward caching devices, the addition of page caching in the browsers, and the explosion of nonhuman user agents attempting to catalog the rapidly expanding Internet. As more and more people came online, the caching devices were needed to improve the overall browsing experience, and while they helped the average surfer connecting with a 28k modem, they dramatically impacted the accuracy of log-parsing applications.
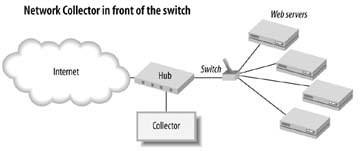
Packet sniffing, also referred to as the network data collection model [Hack #8] , basically puts a listening device on a major node in the web delivery architecture, as shown in Figure 1-6. The listening device would then passively log requests for resources, essentially sitting in front of your web server farm. While sniffing provided some advantages—centralized data collection, more details about failed or cancelled requests, and improved accuracy in server overload conditions—few applications ever supported the model and it never really took off.
About the same time the packet sniffers were starting to struggle, a handful of companies realized that by embedding a small JavaScript file into web pages, you could collect a great deal of useful information about the page being viewed and the visitor doing the viewing. The JavaScript would then dynamically generate an image request to an external server, appending all the collected information into the query string, and the client-side page tag was born [Hack #28] .
Once initial security and privacy concerns were worked out, JavaScript page tags quickly took off. Companies eagerly bought into the use of tags to render traffic data in real time, and others were delighted by the relative simplicity of the hosted application model.
Eventually, though, companies began to discover the limits in their utility as well. A major limitation of page tags is that if they’re not on a page, no data is collected for that page, making deployment mistakes quite costly from a data collection perspective. Also, some companies balk at the seemingly ever-expanding size of the tags, occasionally exceeding 20 KB!
Given that each data source has its benefits and limitations, you might be asking yourself “How should I decide which source is best for my business?” For the most part, there are a handful of needs and limitations. In general, a “yes” answer to any of the criteria presented in Table 1-2 will yield a “best” data source to use.
Table 1-2. Criteria to help you determine which data source to use
Need or limitation | Logfile | Packet sniffer | Page tag |
|---|---|---|---|
Need to access to historical data, generated prior to application implementation | BEST | NO | NO |
Do not have the ability to modify each page on the web site, such as by adding a JavaScript page tag | BEST | OK | NO |
Concerned about accuracy being affected by caching devices and software agents | OK | OK | BEST |
Have no desire to maintain additional hardware inside the network | OK | NO | BEST |
Need access to information in real time | OK | OK | BEST |
Need information about which software agents (robots and spiders) are indexing the site | BEST | BEST | NO |
Concerned about measurement in server overload conditions | OK | BEST | NO |
Concerned about ownership of information | BEST | BEST | NO[1] |
Need to be able to process and track a variety of different types of data (commerce servers, content servers, proxy servers, and media servers) or determine successful delivery of downloadable files (PDF, EXE, DOC, XLS, etc.) | BEST | OK | NO |
Concerned about implementation times and ease of implementation | BEST | OK | NO |
Need ability to log data directly to a database | BEST | OK | NO |
Concerned about high up-front costs | OK | OK | BEST |
[1] While most hosted application vendors will insist that you “own” the data, this is nearly never true since the data physically resides in a different location. Exceptions to this are applications like Visual Sciences and WebTrends SmartSource, which allow page tags to be run from your own infrastructure (and thus the data is wholly owned by you). | |||
While there are no absolutes, it is important decide which source you prefer to use before you start contacting software or service providers. Also, there are often differences in pricing models associated with each data source, with page tags most commonly associated with hosted applications, which are typically paid for on an ongoing basis, and web server logfiles and packet sniffers with software-based solutions, which are typically paid for up front at the beginning of the relationship.
Further complicating your decision making process is the recent emergence of vendors offering hybrid solutions—usually combining page tags and logfiles to create a more holistic view of your data. Vendors like Visual Sciences, Urchin, and Sane Solutions are now offering the ability to blend data sources in new and interesting ways. While hybrid vendors may not be the best solution for you, if you have experience with both logs and page tags and are looking for an alternative, these vendors are worth a look.
Get Web Site Measurement Hacks now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

