September 2020
Intermediate to advanced
46 pages
46m
English
The previous chapter ended with the point that Ray Serve is not limited to serving ML models. It can serve any kind of function, as is. We saw in Chapter 1 that the Ray API is very general and flexible, not at all focused exclusively on ML use cases.
So what if you use Ray for other applications? How does Ray change the way we design and run microservices? What about serverless computing?
These days, applications are often decomposed into microservices, meaning lots of small services, each of which has limited scope and purpose. There are many reasons for using this approach, but let’s focus on the operational aspects.
Figure 4-1 shows a schematic application architecture using microservices. Interactions come through an API gateway and are routed to an appropriate microservice instance. While each microservice is a logical component of the application, there may be many instances of it running in the cluster. It’s rare to run just one instance of a microservice, because that instance is a potential single point of failure, should it crash or the server on which it is running fail. Multiple instances across several servers improves resiliency.
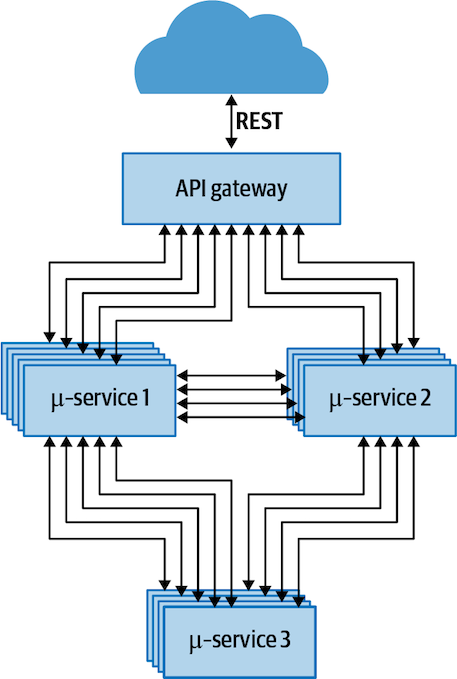
Microservices with heavy service loads may need far more instances than the minimum necessary for resiliency. Machines have finite resources, so many ...
Read now
Unlock full access






