Chapter 4. Building Blocks of Reactive Systems
We build too many walls and not enough bridges.1
Joseph Fort Newton
Systems never live in a vacuum, nor are they composed of identical parts. The real world is much more diverse, and attempting to ignore this fact inevitably leads to disappointment—and in the worst cases, failure.
Instead, we regognize this diversity and turn it into a strength, where various parts of the system can be specialized in the areas they are built for. As explained in Chapter 3, these components can be added one by one to gradually move the architecture of your system toward reactive principles. The journey to a Reactive System may be a long one, but it’s one worth taking since it’ll improve your architecture in ways we discussed throughout this report. It also is important to not become discouraged and to carefully judge where in your system it’s worth making the move and where it’s not. For example, if tasked to build a new functionality, think about whether it would be possible to build it as a reactive microservice and integrate it with the existing system, instead of extending the legacy codebase. For cases where you’re not able to build a greenfield system, apply the Strangler pattern as discussed previously, and pick the building blocks you need for that specific part of the system.
So, what are the other building blocks one can use to build Reactive Systems? We discussed a few of them implicitly already, but we did not have the chance to touch upon all of the various techniques.
For example, as with the case of streaming, we did discuss building and consuming streaming APIs with Akka Streams and Akka HTTP or RxJava. But we did not talk about moving away from nightly batch jobs toward more reactive pipelines of streaming data analysis. These techniques, such as Apache Spark, Flink, or Gear Pump, allow you to improve the responsiveness of your applications.2 Instead of waiting for the nightly batch to complete to send out reports to customers, their data can be processed ad hoc or in a streaming fashion, giving quicker feedback to customers.
Other topics that we barely had the space to mention are cluster schedulers and platforms such as Mesos and Mesosphere DC/OS. Once we build Reactive Services, it’s now time to deploy them somewhere. In order to take advantage of the possibilities given to us by Reactive Services, we need a fabric that supports these capabilities. A good example here is Mesos, which allows us to deploy either on-premise or in the cloud and standardize the way we allocate instances of our applications to resources in our cloud. Thanks to our reactive applications being built with scalability and resilience in mind, schedulers such as Mesos can kill and start instances of our apps as the pressure on the system changes.
Introducing Reactive in Real-World Systems
Fully async architecture has [measurable] benefits. However I don’t expect to see a software system like that. Instead, we deal with mixed-codebases.3
Ben Christensen
The reality of our daily work is that we rarely have the opportunity to start completely fresh. Even if we do have greenfield projects, to be relevant, they have to integrate with existing systems, and those may not have been built with the level of resilience and semantics we would have hoped for in this day and age. We don’t believe that looking down on legacy systems is a healthy approach. Legacy systems are in place because they succeeded at delivering something in their time—something important enough that kept them alive and running up until this day. Once we come to accept this simple truth, one can look for a productive way to move forward and adopt new techniques, such as reactive architecture. In this section, we aim to highlight a successful and proven approach for introducing new techniques into an existing ecosystem.
One of the ways to introduce change into existing code bases, especially when moving to different paradigms or languages, is to use the “Ivy Pattern” (sometimes referred to as the “Strangler Pattern”4), which has been used in multiple projects in the field, however not often knowingly. The concept is rather simple, and is illustrated in Figure 4-1.
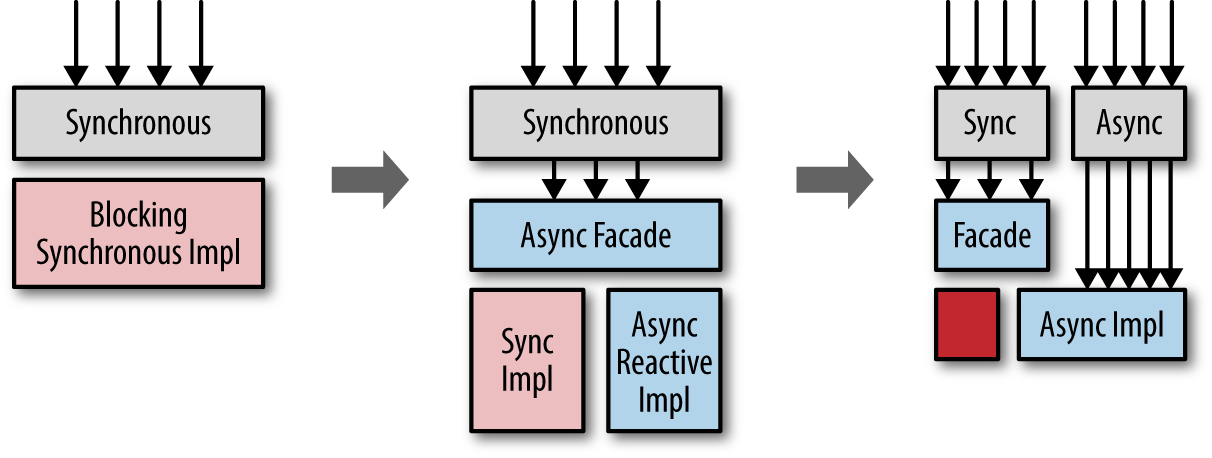
Figure 4-1. Applying the strangler pattern to hide old implementations behind a new Reactive API, and introducing new features in the Reactive part of the system, migrating old functionality to the new core only on an as-needed basis
The idea here is to avoid rewriting the legacy code that works until you hit an actual problem with it, at which point you can consider rewriting it in the new style (but you’re not forced to.) This pattern received its name from how ivy plants strangle trees on which they grow. The idea here is the same, the new system grows around the old one, and without the need to rewrite anything in the old system; meanwhile, the rest of the system can move on to the more reactive style of development, rewriting the internal if (and when) needed, and not sooner. This helps to avoid high-risk “big bang” rewrites, which often end up in disastrous failures—mostly due to underestimating or not understanding the previous codebase.
Reactive, an Architectural Style for Present and Future
I know; you did send me back to the future.
But I’m back. I’m back from the future.Marty McFly, Back to the Future
It is important to realize early on that reactive is not about a single specific technology or library. Instead of spending this book on explaining a specific library, we spent the space and time to dive into the core concepts behind many of them. With this knowledge you should be able to continue your journey and decide on your own which tools suit you best and will help you move toward this new programming paradigm. It is also very interesting to see that we’ve learned from past mistakes5 when developers tried to hide distributed systems, as if they’re just a special case of local execution. A mistake made with synchronous RPC systems such as CORBA and heavyweight SOA processes. We think that we’ve learned some good lessons from these experiments and now with embracing the network more than ever before. And instead of avoiding failure at all costs, we embrace it in our systems, letting them scale and accommodate it.
Of course, there are some great tools available; but used incorrectly, even the best tool or library won’t solve the problem by itself. You may recall the same situation when Agile was taking over the IT industry, and for good reason. But many teams back then applied “the daily standup” without thinking too much about how it should help their team. Instead, they applied it rigidly “by the book,” and when it didn’t solve the rest of the broken process they had in place, they blamed Agile as a whole. Nowadays it is hard to imagine software development without some of the Agile and Lean practices; however, as with any methodology, it still remains open to misinterpretation.
Thus, it is important when adopting reactive to give it some thought and to understand the principles before moving forward. I hope this report will prove to be useful in doing exactly that and in guiding you and your teams toward making the best decisions for the systems you build.
1 While often misattributed to Isaac Newton, the origin of this quote goes back to Joseph Fort Newton’s “The One Great Church: Adventures of Faith” (1948), according to Wikipedia.
2 Apache Gearpump, mostly backed and driven by Intel, the Google MillWheel inspired large scale real-time stream processing engine.
3 Ben Christensen, “Applying reactive Programming with Rx” (Presented at GOTO Chicago 2015, Jul 15, 2015), https://www.youtube.com/watch?v=8OcCSQS0tug.
4 Martin Fowler, “StranglerApplication,” Martinfowler.com, June 29, 2004, http://martinfowler.com/bliki/StranglerApplication.html
5 Steve Vinoski, “Convenience Over Correctness”, IEEE Internet Computing IEEE Internet Comput. 12, no. 4 (2008), doi:10.1109/mic.2008.75; Waldo et al.; “A Note on Distributed Computing”, IEEE Micro, 1994; and Anne Thomas Manes, “SOA Is Dead; Long Live Services”, Application Platform Strategies Blog, January 5, 2009.
Get Why Reactive? now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

