April 2026
Intermediate
292 pages
3h 58m
Chinese
本作品已使用人工智能进行翻译。欢迎您提供反馈和意见:translation-feedback@oreilly.com
在前几章中,我们重点探讨了向量搜索的各个组成部分:创建嵌入向量和执行相似度查询。现在,是时候将这些组件整合成一个可运行的检索增强生成(RAG)系统了。
与依赖分布式 Cloud 集群的生产级 Web 应用不同,我们的目标是构建一个高性能、私有且完全本地化的 RAG 系统,使其能在单台桌面电脑上运行。我们将使用 SQLite VSS 作为搜索引擎,并采用 Ollama 作为本地 LLM“大脑”。
RAG系统解决了LLMs的一个根本性局限:其知识在训练时便已固化,无法获取私有或最新信息。通过为LLMs增强检索机制,我们构建了一个能够利用最新、领域特定知识来回答问题的系统。
我们的目标是构建一个能够智能响应关于Reddit内容查询的问答系统。当用户提出问题时,系统将:(1) 搜索存储的Reddit帖子以查找最相关信息;(2) 检索最匹配的内容片段;(3) 将此上下文提供给LLM;(4) 仅基于检索到的信息生成自然语言答案。
这种方法通过将LLM的回答锚定在实际数据上,确保了事实准确性,显著减少了(尽管未能完全消除)幻觉现象,并使系统能够处理LLM训练数据中未包含的私有或专业内容。
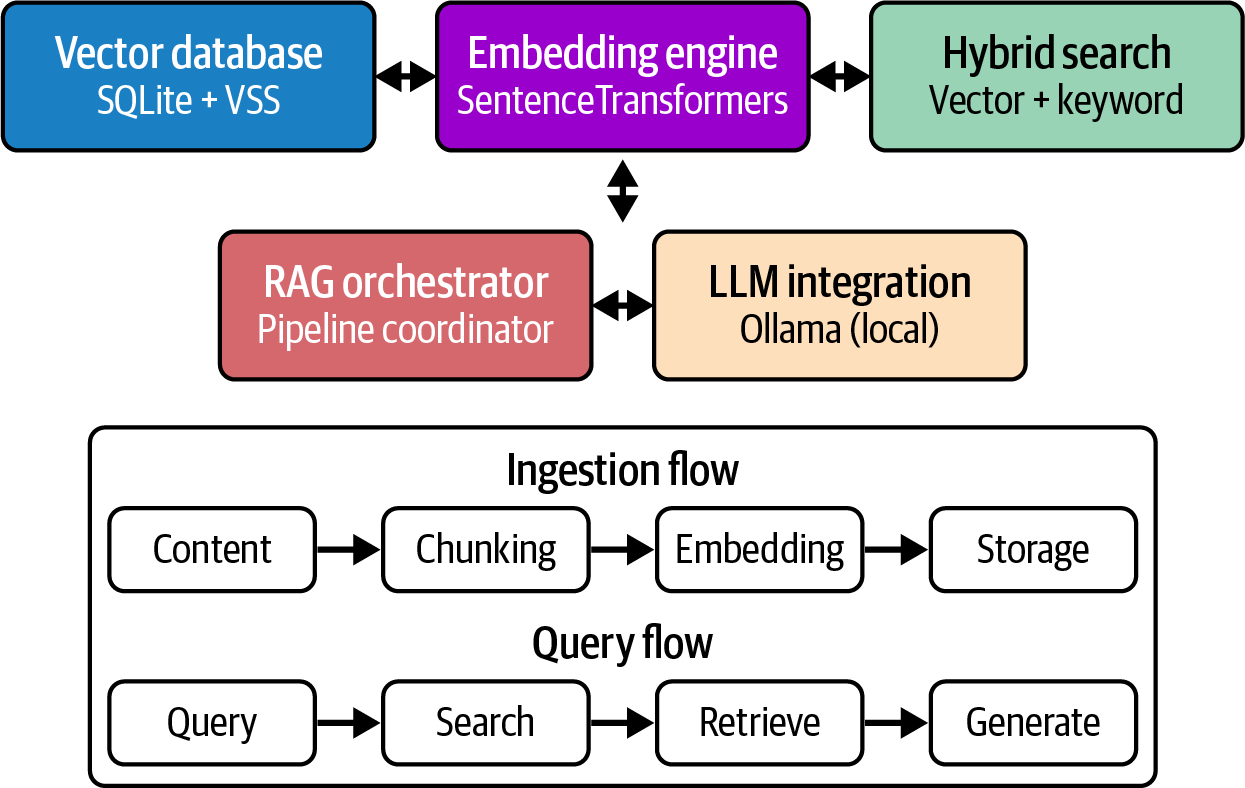
我们的 RAG 系统由五个协同工作的主要组件构成:
将内容片段与其嵌入向量一同存储,从而实现快速相似度搜索
SentenceTransformers)将文本转换为能够捕捉语义含义的密集向量表示
将语义向量搜索与传统关键词搜索相结合,实现最优检索
提供本地 LLM 推理以生成自然语言响应
协调检索与生成流程
数据流遵循以下路径:内容摄取 → 文本分块 → 嵌入向量生成 → 向量存储 → 查询处理 → 混合搜索 → 上下文检索 → prompt构建 → LLM生成。参见图6-1。
让我们逐步构建每个组件。
首先,我们需要搭建数据库基础设施。我们使用带 VSS 扩展的 SQLite,该扩展为 SQLite 增添了向量搜索功能。这为我们提供了一个轻量级的嵌入式解决方案,非常适合 RAG 应用:
# Chapter 6: Minimal RAG System with SQLite VSS and Ollama # Simplified version demonstrating core retrieval-augmented generation import sqlite3 import ollama import requests import json import time import hashlib from sentence_transformers import SentenceTransformer from typing import List, Dict, Optional
导入语句揭示了我们的技术栈:SQLite 用于存储,requests 用于调用 Ollama ...
Read now
Unlock full access






