The XPath View of an XML Document
Before we leave the subject of XPath, we’ll look at a stylesheet that generates a pictorial view of a document. The stylesheet has to distinguish between all of the different XPath node types, including any rarely used namespace nodes.
Output View
Figure 3-1 shows the output of our stylesheet. In this graphical view of the document, the nested HTML tables illustrate which nodes are contained inside of others, as well as the sequence in which these nodes occur in the original document. In the section of the document visible in Figure 3-1, the root of the document contains, in order, two processing instructions and two comments, followed by the <sonnet> element. The <sonnet> element, in turn, contains two attributes and an <auth:author> element. The <auth:author> element contains a namespace node and an element. Be aware that this stylesheet has its limitations; if you throw a very large XML document at it, it will generate an HTML file with many levels of nested tables—probably more levels than your browser can handle.
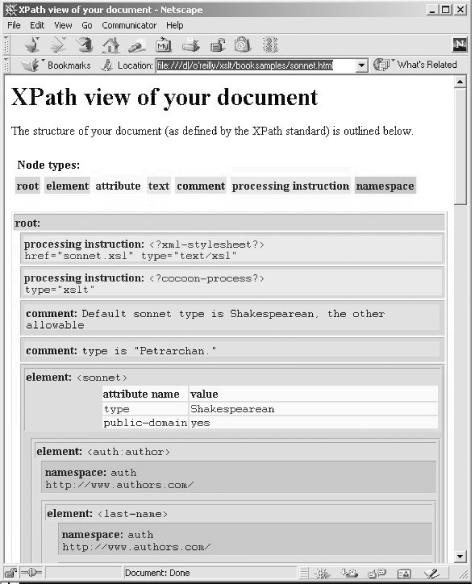
Figure 3-1. XPath tree view of an XML document
The Stylesheet
Now we’ll take a look at the stylesheet and how it works. The stylesheet creates a number of nested tables to illustrate the XPath view of the document. We begin by writing the basic HTML elements to the output stream and creating a legend for our nested tree view:
<xsl:template ...
Get XSLT now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

