May 2025
Intermediate to advanced
380 pages
4h 56m
Chinese
本作品已使用人工智能进行翻译。欢迎您提供反馈和意见:translation-feedback@oreilly.com
深度学习(Deep Learning,DL)是机器学习的一个子领域,其灵感来源于人脑的结构和功能。在深度学习中,由相互连接的人工神经元层组成的神经网络分层处理数据,可以捕捉数据中的复杂模式。每一层都对输入数据进行学习和转换,逐步捕捉更高层次的特征和抽象。
DL 训练过程包括向神经网络输入标注数据,并反复调整神经元的权重和偏置。它可以减少对人工特征工程的依赖 ,并在计算机视觉、自然语言处理、语音识别和强化学习等多个领域取得令人瞩目的成果。
通过变压器、生成式人工智能、ChatGPT 等创新技术,DL 技术正在改变世界。此外,更大、更智能的基础模型可以执行类似人类的任务,生成并理解内容等。
工作和开发 Deep Learning 模型会带来额外的操作复杂性和扩展挑战。这正是 MLOps 的用武之地,它可以帮助简化和抽象复杂性,并将开发和使用复杂模型的过程操作化。
深度学习框架有多种。主要有
TensorFlow 由谷歌开发,是使用最广泛的深度学习框架之一。TensorFlow 是开源的 ,并为构建和部署深度学习模型提供了全面的工具、库和高级 API(如 Keras)生态系统。
PyTorch 由 Meta 的人工智能研究实验室开发,是一个开源的 深度学习库,由于它提供了一个灵活、动态的计算图,可以轻松构建和训练深度学习模型,因此大受欢迎。
Keras 最初是一个独立的库,现在已成为 TensorFlow 官方 API 的一部分。Keras 是开源的 ,为构建和训练深度学习模型提供了更简单的高级 API。
Caffe 是伯克利人工智能研究所(BAIR)开发的开源 深度学习框架,可以构建、训练和部署深度神经网络。Caffe 专注于计算机视觉任务,以速度和效率著称。
这些解决方案提供了各种特性和功能,包括 GPU 加速、分布式训练以及预建模型和架构,使开发和训练复杂的深度学习模型变得更加容易。
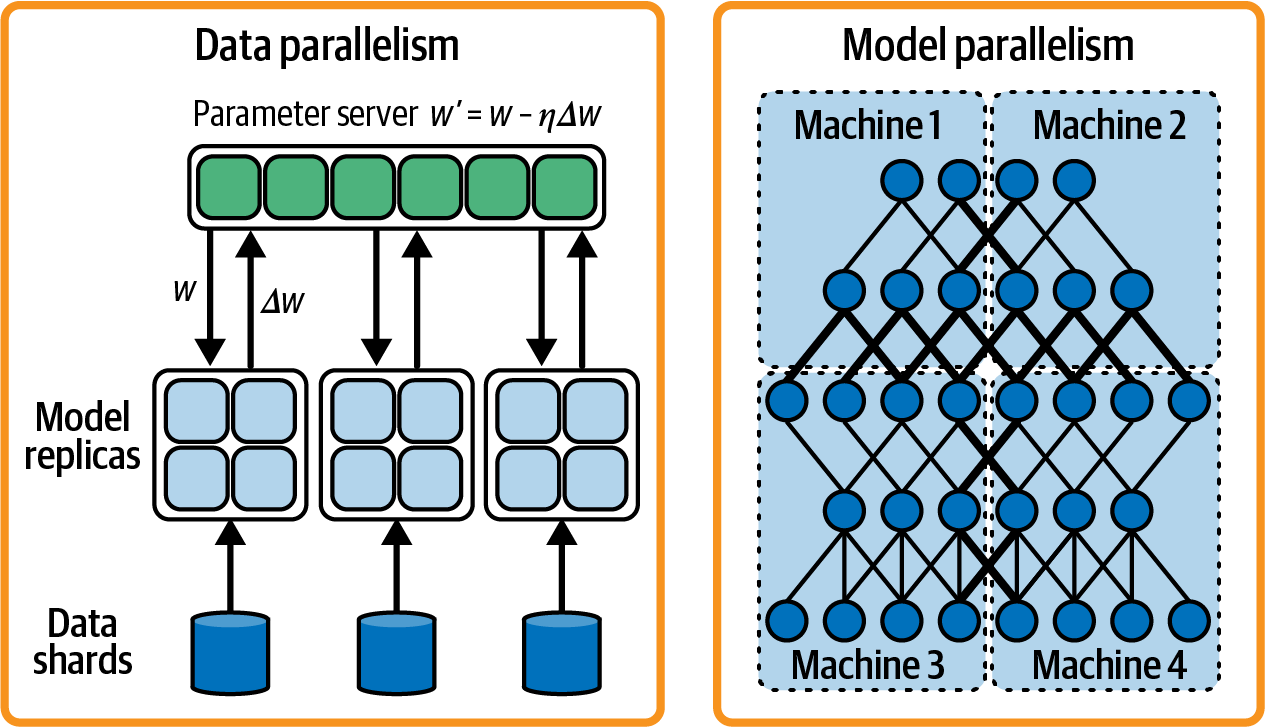
随着模型规模的扩大和训练数据量的增加,越来越需要在多台计算机上加速和分配训练过程。分布式训练过程将任务分解成更小的任务或数据元素,并将结果组合成一个更大的模型。两种广泛使用的分布式(并行)训练方法是
将模型复制到多个系统,每个副本都在一个数据子集上进行训练。然后对每个副本上计算出的梯度进行平均,以更新共享模型参数。当模型参数比数据大小更重要时,数据并行就很有效。
将模型的不同部分分配给多个系统或 GPU 设备。每个系统或设备负责计算其分配的模型部分的前向和后向传递。这种方法适用于模型过大,无法容纳在一个系统或 GPU 内存中的情况。
图 8-1展示了数据并行和模型并行的区别。
在分布式训练中,大量数据在系统间交换,需要快速网络和高性能消息传递协议(如消息传递接口,或 MPI)。
TensorFlow 和 PyTorch 提供了用于分发训练的内置库和解决方案。这些库可以部署在 Kubernetes ...
Read now
Unlock full access






