
 Nellis Solar Power Plant. (source: U.S. Air Force on Wikimedia Commons)
Nellis Solar Power Plant. (source: U.S. Air Force on Wikimedia Commons) The more I think about the concept of insight as a service, the more I believe that we don’t have a good understanding of what constitutes “insight.” In today’s environment where corporate marketing over-hypes everything associated with big data and analytics, the word “insight” is being used very loosely, most of the time in order to indicate the result of any type of data analysis or any form of prediction. For this reason, I feel it is important to define the concept of insight. Once we define the concept, we can determine under what conditions we can deliver insight as a service.
Insight defined
An insight is a novel, interesting, plausible, and understandable relation, or set of associated relations, that is selected from a larger set of relations derived from a data set.
An insight must have the following key properties:
- Actionable. The relation, or relations, must lead to the formation of an action plan.
- Measurable. When applied, the action plan results in a change that can be measurable through a set of Key Performance Indicators (KPIs).
- Stable. An insight must not vary depending on the relation-identification/model-creation algorithm being used. For example, if you use two different samples from the same data set to create a predictive model that employs the same model-creation method, then the resulting models have to provide the identical result under the same new data input.
- Reproducible. Regardless of how many times you feed a particular data set through an insight-generation system, the same insight will be produced.
- Robust. A certain amount of noise in the input data will not diminish the quality of the insight. This is a particularly important requirement in big data environments. Insight-generation systems must be able to organize noisy data and focus on the data that makes “sense,” based on a particular context.
- Enduring. The insight is valid for an amount of time that is related to the underlying data’s “half life.”
Insights are discovered by reasoning over the output of knowledge extractors, such as systems that create analytic models, and the data that was used to create the output. The function of insightful systems is twofold: to identify interesting relations (insights) from the output of the knowledge extractors, and to create one or more action plans that can be associated with a relation, or collection of relations. This process is not completely mechanical. Rather, it necessitates the use of domain knowledge (or domain ontology) and the guidance of domain experts.
An example of insight generation in action
Corporations that use subscription business models (e.g., wireless carriers, cable companies, SaaS application providers) use a variety of analytic models to predict which of their customers will churn so that they may take action to reduce potential attrition. Creating such models is relatively straightforward and is routinely done using the available analytic tools. Marketers in such corporations allocate part of their budgets to achieving this goal. But not all customers that are likely to churn are worth saving.
Let’s assume for example that a cable company can use one predictive model to score all of its subscribers in terms of their probability to abandon the service, a second model to identify its subscribers’ probability to upgrade to a higher level of service, and a third model to organize the scored customers in segments based on their propensity to churn and their probability to upgrade to a higher level of service. A challenge with this approach is identifying the characteristics of the segments containing at-risk customers that are worth paying attention to and worth allocating a disproportionate amount of the marketing budget to in order to keep them as subscribers.
Let’s further assume that the marketer chooses to focus on one of the identified customer segments — that which includes heavy Internet users who spend only 10% of their time watching the packaged programming offered by the cable company (i.e., less than the average subscriber) and, moreover, tend to watch only standard TV channels rather than premium channels (compared to customers who have a high probability of upgrading to a higher level of service). The insight this marketer wants to gather is the characteristics of the members of this particular segment, in relation to a particular population.
From a collection of appropriate action plans, the marketer associates this insight with a plan that offers this segment of subscribers a collection of premium TV channels for free for a period of six months. A consequence of this action plan is a cost to the company (e.g., $100/subscriber). Therefore, a KPI that measures the impact of the plan can be based on each salvaged subscriber’s Lifetime Value (e.g., $1,000). This is an insight because, along with the relations identified through the analysis, we can associate a plan of action with these relations.
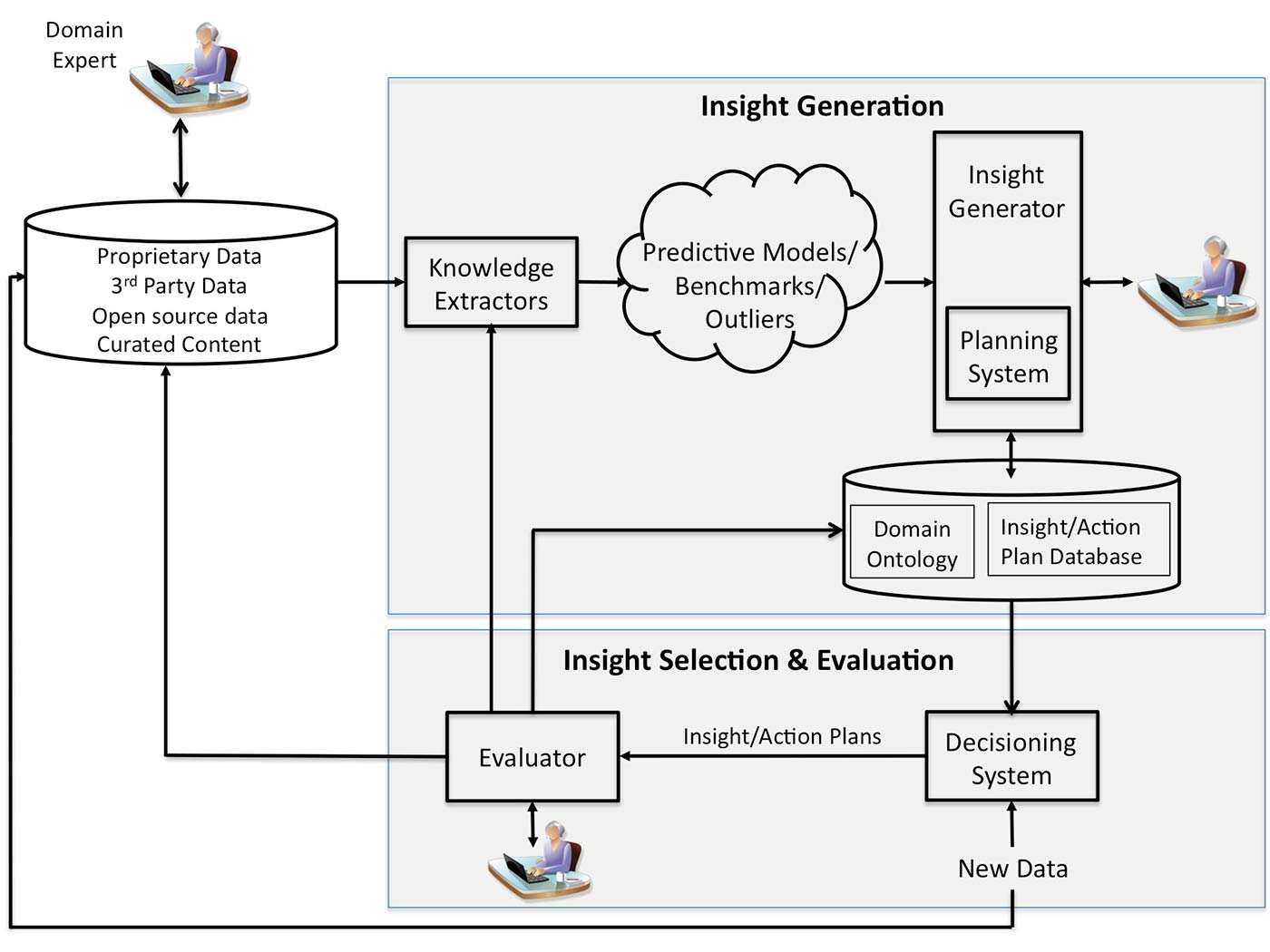
The insight generation process: an overview
As shown in Figure 1 below, insight generation is an iterative, highly interconnected process. The steps, from data ingestion to insight generation and application, generally proceed as follows:
- Collect, organize, and curate data.
- Use knowledge extractors to generate various relations (predictions, correlations, benchmarks, outlier identifications, and optimizations).
- Use available domain ontology and human domain expert to reason over the extracted knowledge and generate candidate insights.
- Use available domain ontology and human domain expert to hypothesize one or more action plans for each generated insight. Retain insights for which action plans cannot be hypothesized, in case plans can be generated in the future based on new domain knowledge.
- Given new data that describes a problem/situation, select and apply the appropriate insight/action plan pairs, and measure their impact against KPIs.
Collect, organize, and curate data
Insight generation depends on our ability to a) collect, organize, and curate data; b) extract knowledge from that data using a variety of knowledge extraction models; and c) analyze the extracted knowledge. Therefore, in order to generate insights, we must have the ability to extract knowledge. This means that we need to be thinking not only about the data collection, data management, and data archiving processes, but also about how to post-process and curate the collected data — what attributes to derive, what metadata to define.
Insight generation is highly dependent on how an environment is “instrumented.” For example, consumer marketers have gone from measuring a few attributes per consumer (think of the early consumer panels run by companies such as Nielsen) to measuring thousands of attributes, including consumer Web behavior and consumer interactions in social networks. The “right” instrumentation of an environment is not always immediately obvious (i.e., which data that can be captured needs to be captured?). Often, it may not even be immediately possible to capture particular types of data. For example, it took some time between the advent of the Web and our ability to capture browsing activity through cookies. But obviously, the better the instrumentation, the better the analytic models, and thus, the higher the likelihood that insights can be generated. Knowing how to instrument an environment and how to use the instrumentation to measure and gather data is an experiment-design process and frequently requires domain knowledge.
Insight generation also requires the organization of noisy or dirty data, which is typically the case with big data, and a focus on the data that makes “sense,” given a specific context and state of domain knowledge.
Reason over extracted knowledge to generate candidate insights
Once the data is collected, organized, and curated, insight candidates may be generated by reasoning over the output of analytic models, or knowledge extractors. Knowledge extractors may be created manually or automatically. For example, a predictive model that has been automatically created from a data set is a form of knowledge extractor.
Reasoning involves using available domain ontology to evaluate the extracted relations. During this step, key details emerge such as outliers or associations among sets of relations, as we saw in the cable subscription example above. Reasoning may be done automatically, or it can be assisted by a human domain expert. For this reason, we maintain that the reasoning process, and therefore insight generation, is facilitated when the extracted knowledge can be expressed declaratively. As a result, in the case of predictive models, prediction accuracy and speed may need to be sacrificed for model expressiveness. A good example of this approach is IBM’s Watson system. This system uses ensemble learning to create different analytic models from a body of data. Each model comprises a set of relations and provides a different perspective on specific data sets — for example, data related to cancer patients and data related to oncology.
Hypothesize action plan(s) for each insight
Once a relation, or set of relations, is designated as an insight, the insight generator first determines whether it exhibits the other key properties of an insight (e.g., stable, reproducible, robust, and enduring), and then employs the planner. Here, the planner accesses a library of action plans and associates one or more plans with the insight. Several action plans may be hypothesized and associated with one insight. A human domain expert may decide to eliminate some of these hypothesized action plans as inappropriate. Each insight/action plan pair that is accepted by the domain expert is then stored in the insight/action plan database.
Apply insight/action plan pairs to new data and measure impact against KPIs
Insight/action plan pairs can be applied to a new set of data, or problem, which provides the context for the application of an insight. Insightful systems include a decisioning system, which accesses the insight/action plan database, domain ontology, and any established KPIs. The decisioning system then selects and applies the appropriate insight/action plan pair(s) to address the new problem. The results of this application are in turn evaluated by the evaluator, which may be a human domain expert or a human-assisted system.
The results of each insight/action plan application provide opportunities to improve the entire system, by potentially enhancing the capabilities of knowledge extractors, updating domain ontology, and recording the success metrics of each insight/action plan selected by the decisioning system.
KPIs are measured by the evaluator and take into consideration the cost, including the time required to take action, and ROI of applying an action (as we saw in the cable subscription example above) or some other metric. The performance of IBM’s Watson on Jeopardy! provides a great example of how KPIs work in a decisioning system — Watson had a limited amount of time to come up with the correct response to beat its opponents. IBM’s Watson oncology assistant is another relevant example of KPIs used during the decisioning phase — in this instance, the KPIs may be related to the amount of time a doctor has to complete a medical procedure, or the cost of such a procedure.
The case for offering insight as a cloud-based, semi-automated service
While we are largely able to automate data collection and the creation of certain types of knowledge extractors, creating insightful systems that completely automate insight generation is proving a very difficult task. Today, insight has to be generated manually by the analysis of models derived from a body of data — a task typically provided by expensive expert consultants. This approach is neither scalable nor cost effective. Therefore, few organizations can afford it. Offering insight generation as a cloud-based service, as we are starting to see from companies like Google and IBM, provides a compelling case for broadening the use of insightful systems.
Here are some reasons why cloud-based, semi-automated insight-generation systems make sense:
- The data curation process is greatly improved with the help of human expertise, which can be provided at scale through cloud-based implementations. An early example of the advantages of this process is Amazon’s Mechanical Turk. Similarly, imagine the medical institutions participating in the development of the Watson oncology assistant, such as MD Anderson Cancer Center and the Memorial Sloan Kettering Cancer Center, sharing not only curated data, but also insights and treatment plans.
- Certain types of insights (e.g., benchmarking) can only be offered as a service because the provider needs to compare data from a variety of organizations. For example, see what companies like Lumosity and Fitbit are doing with benchmarking at the consumer level.
- New or specialized knowledge extractors can be accessed, used, and updated more easily through cloud-based implementation of insightful systems.
- Insight as a service could save organizations money. Even organizations that are capable of generating their own insights may ultimately decide to outsource the insight-generation-and-analysis processes if they find specialized groups can execute more efficiently and cost effectively.
- Insight as a service allows organizations a periscope to other insights that have been generated across the industry. For example, FICO has now developed tremendous credit insight expertise, which no single financial services organization has replicated.
- Cloud-based implementation of insightful systems can allow organizations to access insight-effectiveness evaluators. Often, a collaboration of evaluators is required to reach consensus on evaluator effectiveness. The Watson oncology assistant demonstrates this point.
Where do we go from here?
We are gaining a better understanding of the difference between patterns and correlations derived from data sets and insights. It is particularly important that we comprehend these two relations as we interact more frequently with big data and use insights to gain competitive advantages. Offering manual insight-generation services provides us with some short-term reprieve, but ultimately, we need to develop cloud-based semi-automated and fully automated insight-generation systems — the data is getting bigger, and our ability to act on it is not keeping pace.
Two earlier related versions of this post — Insight Generation and Defining Insight — appeared on corporate-innovation.co.
Related: