
 The Flying Wallendas 7-Man Pyramid, 2005 (source: Porterlu on Wikimedia Commons)
The Flying Wallendas 7-Man Pyramid, 2005 (source: Porterlu on Wikimedia Commons) In this post, I share slides and notes from a keynote I gave at the Strata Data Conference in New York last September. As the data community begins to deploy more machine learning (ML) models, I wanted to review some important considerations.
Let’s begin by looking at the state of adoption. We recently conducted a survey which garnered more than 11,000 respondents—our main goal was to ascertain how enterprises were using machine learning. One of the things we learned was that many companies are still in the early stages of deploying machine learning (ML):
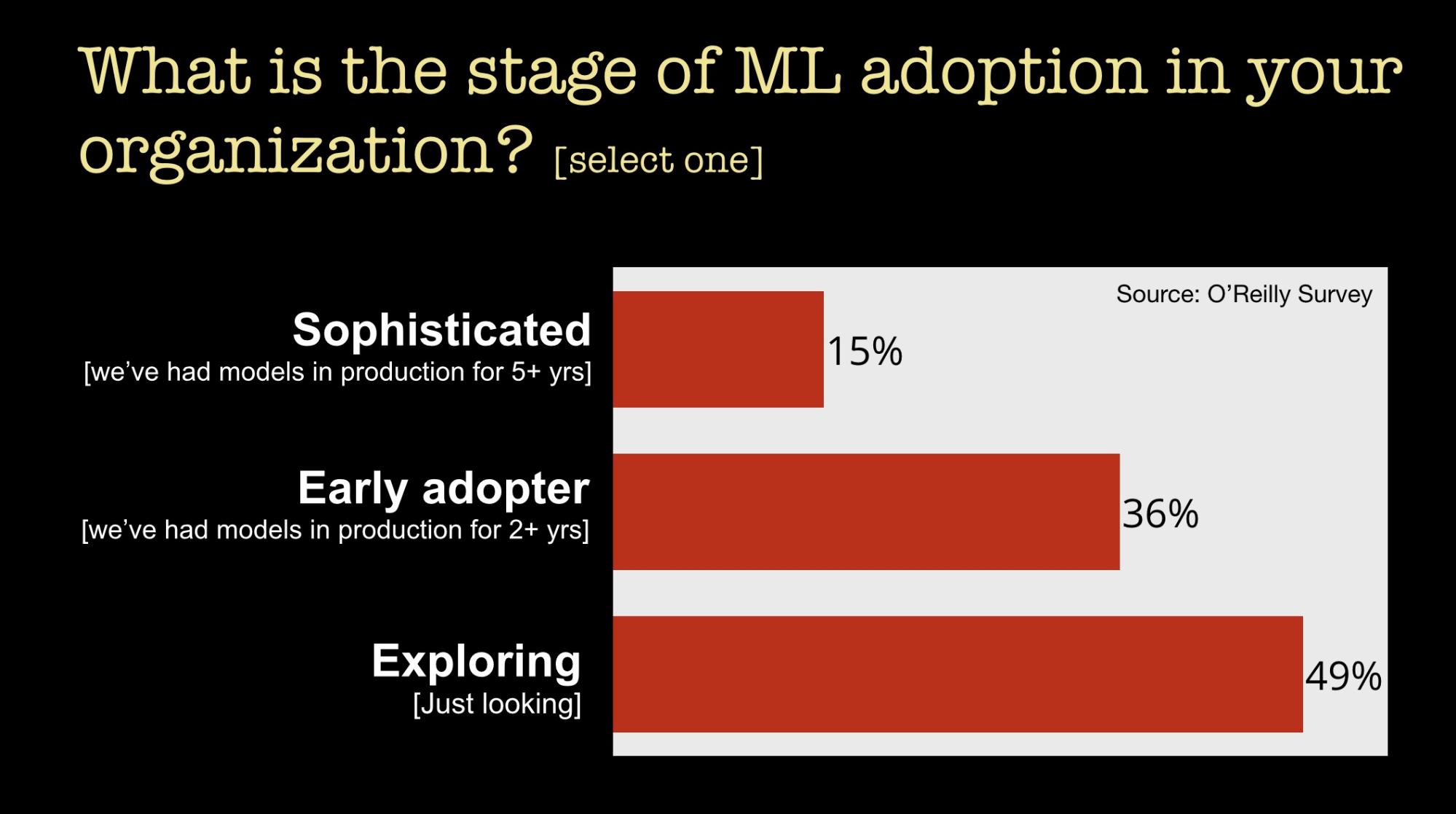
As far as reasons for companies holding back, we found from a survey we conducted earlier this year that companies cited lack of skilled people, a “skills gap,” as the main challenge holding back adoption.
Interest on the part of companies means the demand side for “machine learning talent” is healthy. Developers have taken notice and are beginning to learn about ML. In our own online training platform (which has more than 2.1 million users), we’re finding strong interest in machine learning topics. Below are the top search topics on our training platform:

Beyond “search,” note that we’re seeing strong growth in consumption of content related to ML across all formats—books, posts, video, and training.
Before I continue, it’s important to emphasize that machine learning is much more than building models. You need to have the culture, processes, and infrastructure in place before you can deploy many models into products and services. At the recent Strata Data conference we had a series of talks on relevant cultural, organizational, and engineering topics. Here’s a list of a few clusters of relevant sessions from the recent conference:
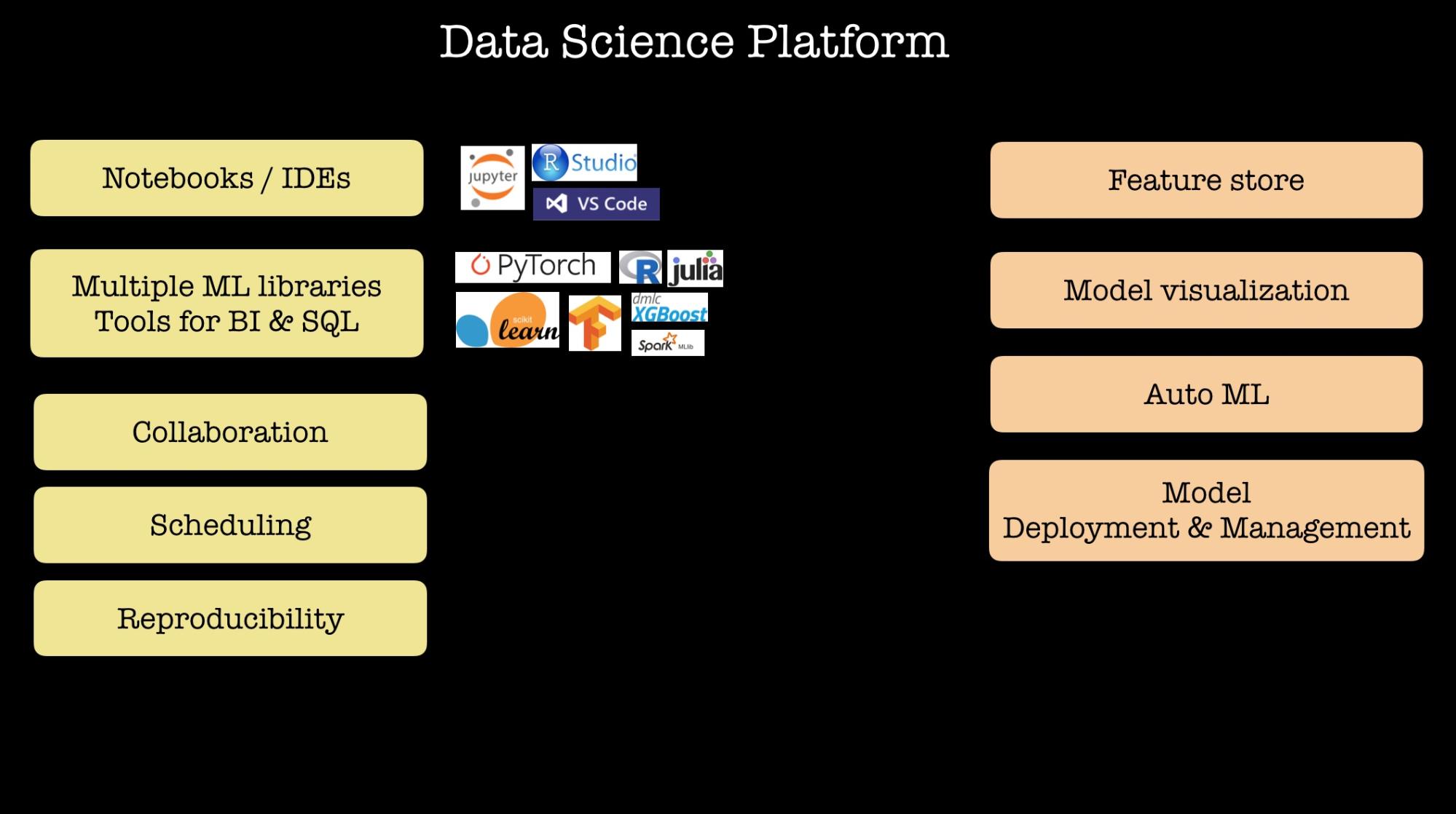
Over the last 12-18 months, companies that use a lot of ML and employ teams of data scientists have been describing their internal data science platforms (see, for example, Uber, Netflix, Twitter, and Facebook). They share some of the features I list below, including support for multiple ML libraries and frameworks, notebooks, scheduling, and collaboration. Some companies include advanced capabilities, including a way for data scientists to share features used in ML models, tools that can automatically search through potential models, and some platforms even have model deployment capabilities:
As you get beyond prototyping and you actually begin to deploy ML models, there are many challenges that will arise as those models begin to interact with real users or devices. David Talby summarized some of these key challenges in a recent post:
- Your models may start degrading in accuracy
- Models will need to be customized (for specific locations, cultural settings, domains, and applications)
- Real modeling begins once in production
There are also many important considerations that go beyond optimizing a statistical or quantitative metric. For instance, there are certain areas—such as credit scoring or health care—that require a model to be explainable. In certain application domains (including autonomous vehicles or medical applications), safety and error estimates are paramount. As we deploy ML in many real-world contexts, optimizing statistical or business metics alone will not suffice. The data science community has been increasingly engaged in two topics I want to cover in the rest of this post: privacy and fairness in machine learning.
Privacy and security
Given the growing interest in data privacy among users and regulators, there is a lot of interest in tools that will enable you to build ML models while protecting data privacy. These tools rely on building blocks, and we are beginning to see working systems that combine many of these building blocks. Some of these tools are open source and are becoming available for use by the broader data community:

- Federated learning is useful when you want to collaborate and build a centralized model without sharing private data. It’s used in production at Google, but we still are in need of tools to make federated learning broadly accessible.
- We’re starting to see tools that allow you to build models while guaranteeing differential privacy, one of the most popular and powerful definitions of privacy. At a high-level these methods inject random noise at different stages of the model building process. These emerging sets of tools aim to be accessible to data scientists who are already using libraries such as scikit-learn and TensorFlow. The hope is that data scientists will soon be able to routinely build differentially private models.
- There’s a small and growing number of researchers and entrepreneurs who are investigating whether we can build or use machine learning models on encrypted data. This past year, we’ve seen open source libraries (HElib and Palisade) for fast homomorphic encryption, and we have startups that are building machine learning tools and services on top of those libraries. The main bottleneck here is speed: many researchers are actively investigating hardware and software tools that can speed up model inference (and perhaps even model building) on encrypted data.
- Secure multi-party computation is another promising class of techniques used in this area.
Fairness
Now let’s consider fairness. Over the last couple of years, many ML researchers and practitioners have started investigating and developing tools that can help ensure ML models are fair and just. Just the other day, I searched Google for recent news stories about AI, and I was surprised by the number of articles that touch on fairness.
For the rest of this section, let’s assume one is building a classifier and that certain variables are considered “protected attributes” (this can include things like age, ethnicity, gender, …). It turns out that the ML research community has used numerous mathematical criteria to define what it means for a classifier to be fair. Fortunately, a recent survey paper from Stanford—A Critical Review of Fair Machine Learning—simplifies these criteria and groups them into the following types of measures:

- Anti-classification means the omission of protected attributes and their proxies from the model or classifier.
- Classification parity means that one or more of the standard performance measures (e.g., false positive and false negative rates, precision, recall) are the same across groups defined by the protected attributes.
- Calibration: If an algorithm produces a “score,” that “score” should mean the same thing for different groups.
However, as the authors from Stanford point out in their paper, each of the mathematical formulations described above suffers from limitations. With respect to fairness, there is no black box or series of procedures that you can stick your algorithm into that can give it a clean bill of health. There is no such thing as a “one size, fits all” procedure.
Because there’s no ironclad procedure, you will need a team of humans-in-the-loop. Notions of fairness are not only domain and context sensitive, but as researchers from UC Berkeley recently pointed out, there is a temporal dimension as well (“We advocate for a view toward long-term outcomes in the discussion of ‘fair’ machine learning”). What is needed are data scientists who can interrogate the data and understand the underlying distributions, working alongside domain experts who can evaluate models holistically.
Culture and organization
As we deploy more models, it’s becoming clear that we will need to think beyond optimizing statistical and business metrics. While I haven’t touched on them during this short post, it’s clear that reliability and safety are going to be extremely important moving forward. How do you build and organize your team in a world where ML models have to take many other important things under consideration?

Fortunately there are members of our data community who have been thinking about these problems. The Future of Privacy Forum and Immuta recently released a report with some great suggestions on how one might approach machine learning projects with risk management in mind:
- When you’re working on a machine learning project, you need to employ a mix of data engineers, data scientists, and domain experts.
- One important change outlined in the report is the need for a set of data scientists who are independent from this model-building team. This team of “validators” can then be tasked with evaluating the ML model on things like explainability, privacy, and fairness.
Closing remarks
So, what skills will be needed in a world where ML models are becoming mission critical? As noted above, fairness audits will require a mix of data and domain experts. In fact, a recent analysis of job postings from NBER found that compared with other data analysis skills, machine learning skills tend to be bundled with domain knowledge.
But you’ll also need to supplement your data and domain experts with with legal and security experts. Moving forward, we’ll need to have legal, compliance, and security people working more closely with data scientists and data engineers.

This shouldn’t come as a shock: we already invest in desktop security, web security, and mobile security. If machine learning is going to eat software, we will need to grapple with AI and ML security, too.
Related content:
- Sharad Goel and Sam Corbett-Davies on “Why it’s hard to design fair machine learning models”
- Alon Kaufman on “Machine learning on encrypted data”
- Chang Liu on “How privacy-preserving techniques can lead to more robust machine learning models”
- “How to build analytic products in an age when data privacy has become critical”
- “Data collection and data markets in the age of privacy and machine learning”
- “What machine learning means for software development”
- “Lessons learned turning machine learning models into real products and services”