
 Unlimited detail: A fractal object with unlimited complexity, repeating periodically. (source: Mikael Hvidtfeldt Christensen on Flickr)
Unlimited detail: A fractal object with unlimited complexity, repeating periodically. (source: Mikael Hvidtfeldt Christensen on Flickr) In February of this year, I published the article, Is my developer team ready for big data?, with a figure representing the subjective complexity of mobile, cloud, big data, and NoSQL technologies:
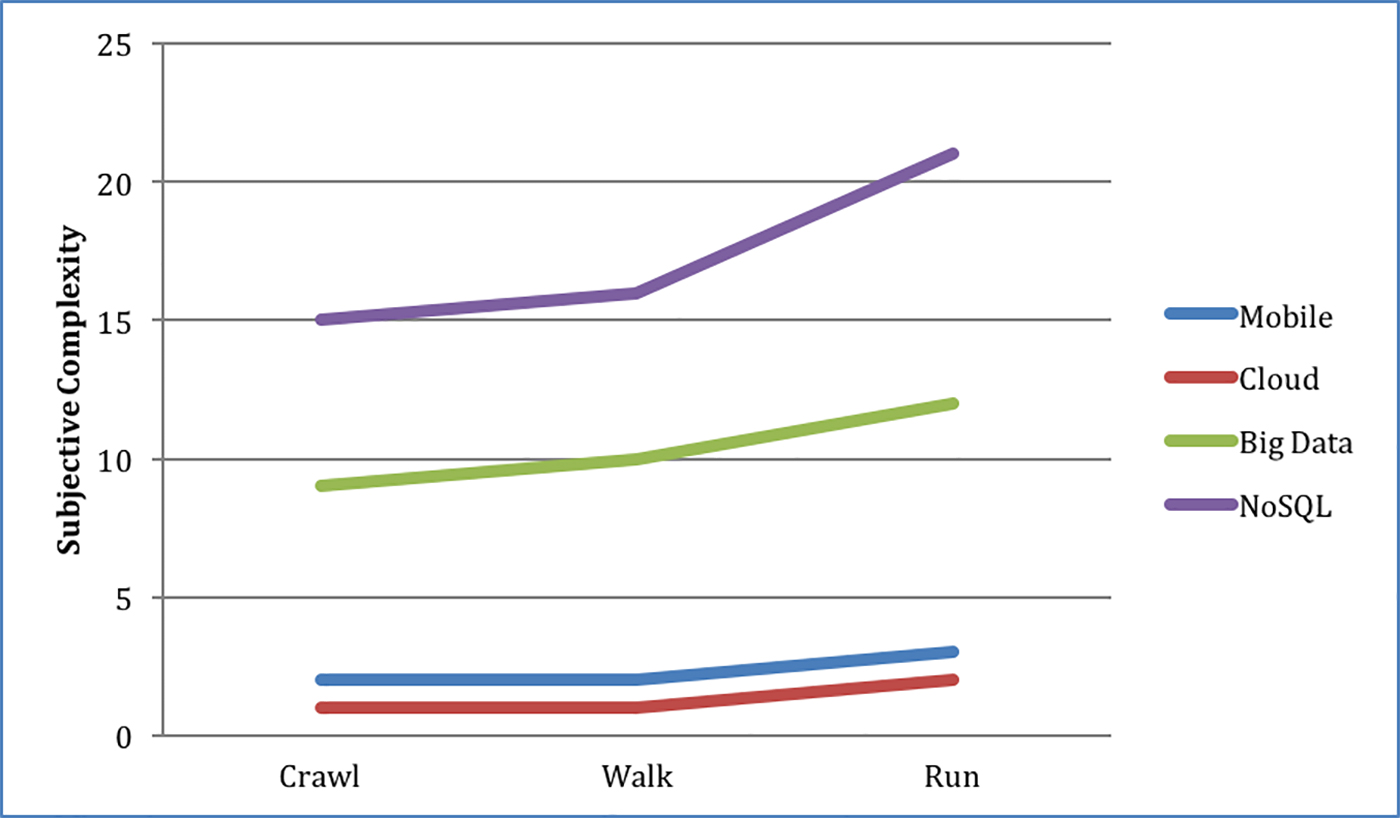
My editor for that article, Marie Beaugureau, pushed back on the figure—and rightly so. What’s the scale we’re using here? What makes big data and NoSQL more complex than cloud or mobile?
To give you some background, I’ve written and taught courses on all four of these subjects. By writing and teaching these courses, I’ve created a good baseline of complexity across all four subjects, and for how hard it is to teach each one to a beginner in the field. These baselines span hundreds of companies, thousands of use cases, thousands of students, and several countries (but primarily based in the U.S.).
For the past two years, I’ve tried to show—in a simple way—how big data is different.
I attribute the complexity of big data to two primary reasons. The first being that you need to know 10 to 30 different technologies, just to create a big data solution. The second reason is that distributed systems are just plain hard.
So many technologies
Let’s start off with a diagram that shows a sample architecture for a mobile product, with a database back end. Figure 2 illustrates a run-of-the-mill mobile application that uses a web service to store data in a database:
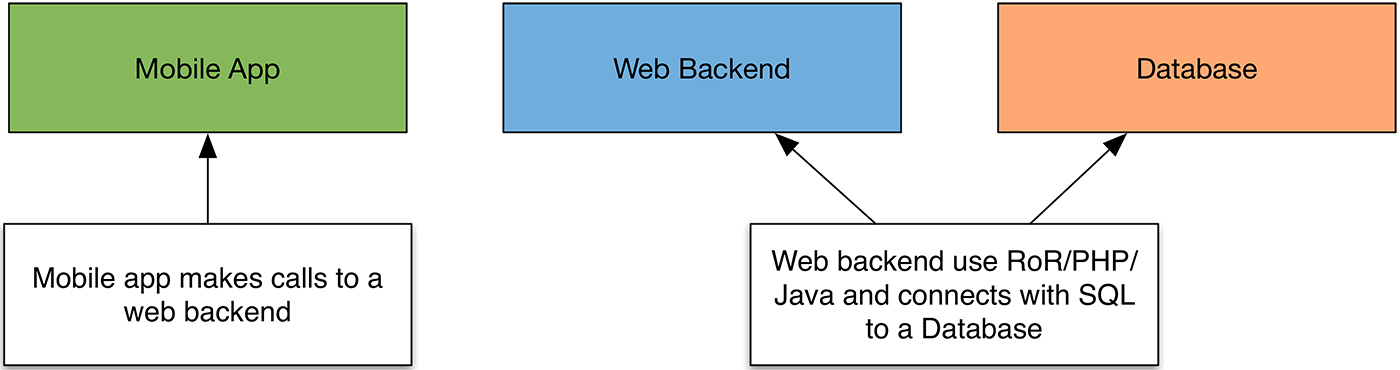
Let’s contrast the simple architecture for a mobile app with Figure 3, which shows a starter Hadoop solution:
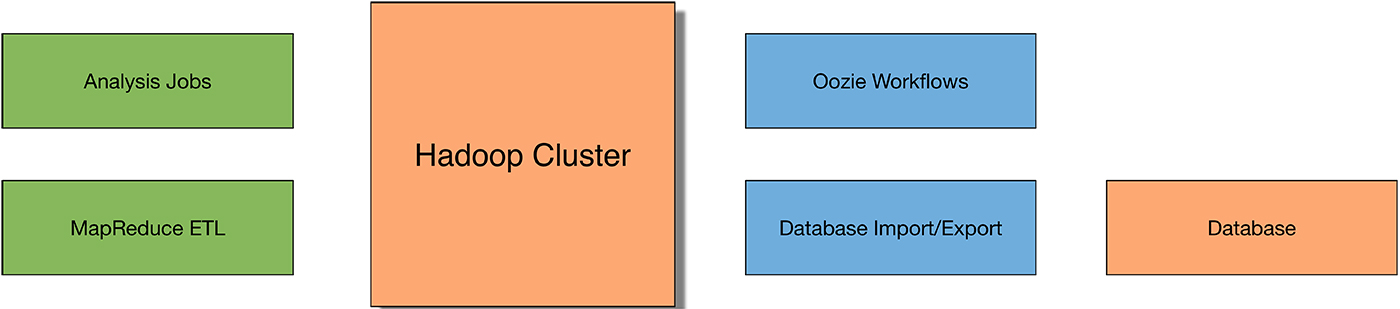
As you can see, Hadoop weighs-in at double the number of boxes in our diagram—why? What’s the big deal? A “simple” Hadoop solution actually isn’t very simple at all. You might think of this more as a starting point or, to put it another way, as “crawling” with Hadoop. The “Hello World” of a Hadoop solution is more complicated than other domain’s intermediate to advanced setups. See my source code for a Hello World in big data that’s not so simple.
Now, let’s look at a complicated mobile project’s architecture diagram in Figure 4:
Note: that’s the same diagram as the simple mobile architecture. Usually, a more complex mobile solution requires more code or more web service calls, but no additional technologies are added to the mix.
Let’s contrast a simple big data/Hadoop solution with a complex big data/Hadoop solution in Figure 5:
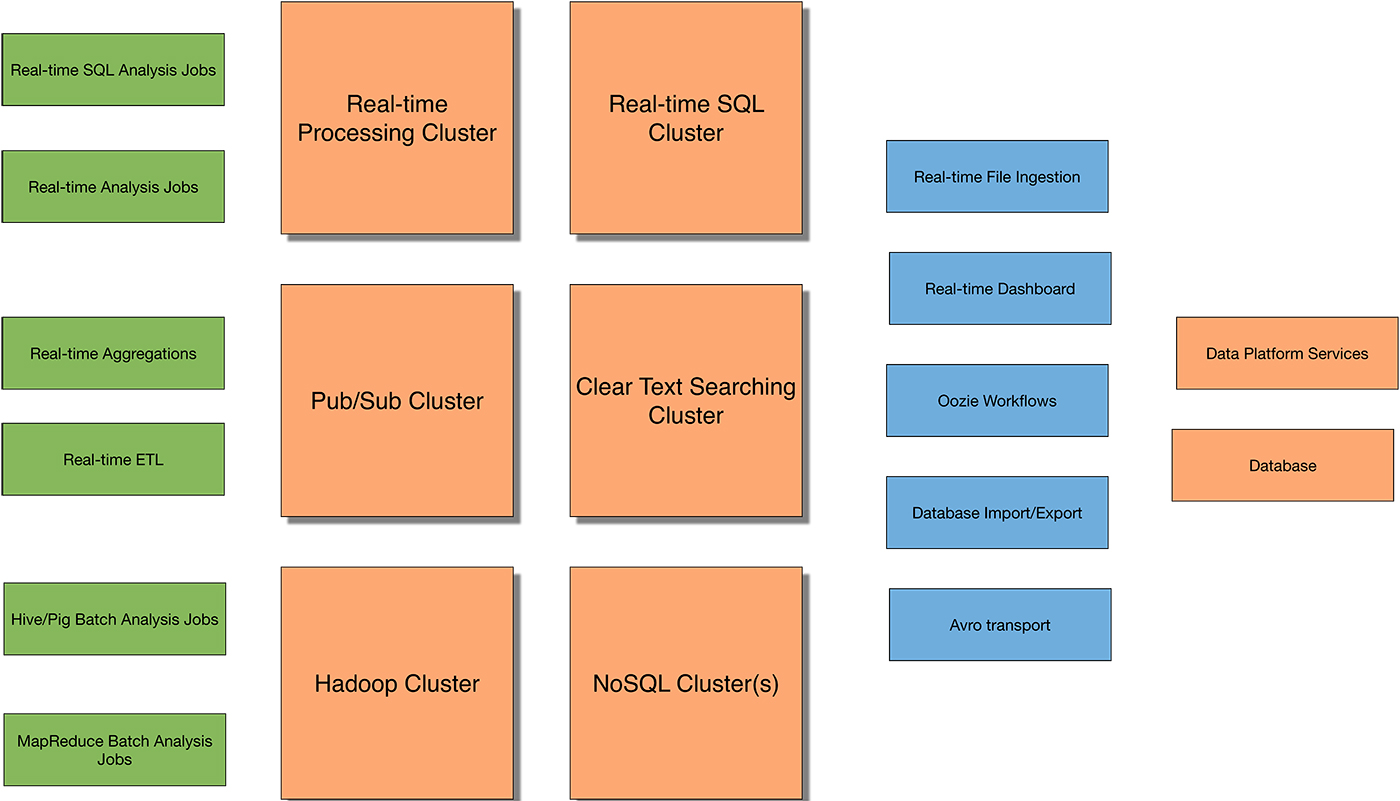
Yes, that’s a lot of boxes, representing various types of components you may need when dealing with a complex big data solution. This is what I call the “running” phase of a big data project.
You might think I’m exaggerating the number of technologies to make a point; I’m not. I’ve taught at companies where this is their basic architectural stack. I’ve also taught at companies with twice as much complexity in their architectural stack.
Training: What it takes to understand big data solutions
Instead of just looking at boxes, let’s consider how many days of training it would take between a complex mobile and big data solution, assuming you already know Java and SQL. Based on my experience, a complex mobile course would take four to five days, compared to a complex big data course, which would take 18 to 20 days, and this estimate assumes you can grok the distributed systems side of all of this training. In my experience teaching courses, a data engineer can learn mobile, but a mobile engineer has a very difficult time learning data engineering.
You also saw me say you need to know 10 to 30 different technologies in order to choose the right tool for the job. Data engineering is hard because we’re taking 10 complex systems, for example, and making them work together at a large scale. There are about 10 shown in Figure 5. To have made the right decision in choosing, for example, a NoSQL cluster, you’ll need to first have learned the pros and cons of five to 10 different NoSQL technologies. From that list, you will have narrowed it down to two to three for a more in-depth look.
During this period, you might compare, for example, HBase and Cassandra. Is HBase the right one or is Cassandra? That comes down to you knowing what you’re doing. Do you need ACID-ity? There are a plethora of questions you’d need to ask to choose one. Don’t get me started on choosing a real-time processing system, which requires knowledge of and comparison between Kafka, Spark, Flink, Storm, Heron, Flume, and the list goes on.
Distributed systems are hard
Distributed systems frameworks like Hadoop and Spark make it easy, right? Well, yes and no.
Yes, distributed systems frameworks make it easy to focus on the task at hand. You’re not thinking about how and where to spin up a task or threading. You’re not worried about how to make a network connection, serialize some data, and then deserialize it again. Distributed systems frameworks allow you to focus on what you want to do rather than coordinating all of the pieces to do it.
No, distributed systems frameworks don’t make everything easy. These frameworks make it even more important to know the weaknesses and strengths of the underlying system. They assume that you know and understand the unwritten rules and design decisions they made. One of those assumptions is that you already know distributed systems or can learn the fundamentals quickly.
I think Kafka is a great example of how, in making a system distributed, you add 10x the complexity. Think of your favorite messaging system, such as RabbitMQ. Now, imagine you added 10x the complexity to it. This complexity isn’t added through some kind of over-engineering, or my Ph.D. thesis would fit nicely here. It’s simply the result of making it distributed across several different machines. Making a system distributed, fault tolerant, and scalable adds the 10x complexity.
What does it all mean, Basil?
We can make our APIs as simple as we want, but they’re only masking the greater complexity of creating the system. As newer distributed systems frameworks come out, they’re changing how data is processed; they’re not fundamentally altering the complexity of these big data systems.
Distributed systems are hard, and 10x more complex. They’ll be largely similar to each other, but have subtle differences that bite you hard enough to lose five months of development time if one of those subtle differences makes a use case impossible. And I love teaching software developers how to become data engineers.