The big data market
A data-driven analysis of companies using Hadoop, Spark, data science, and machine learning.
 "Market Scene," by Pieter Aertsen, 1550. (source: Wikimedia Commons)
"Market Scene," by Pieter Aertsen, 1550. (source: Wikimedia Commons)
Hadoop is the flagship of the much-hyped “big data” revolution, comprising of a host of different technologies. While there are many alternatives and variants, including Cloudera, Hortonworks, Amazon EMR, Storm, and Apache Spark, Hadoop as a whole remains the most-deployed and most-discussed big data technology.
But as revolutionary as big data is, our analysis of more than 500,000 of the largest companies in the world reveals that a very small percentage have embraced it in reality. One could argue that it’s still very much in the early adoption phase of the technology adoption model. Using Hadoop as a proxy for big data deployment, we discovered some very interesting statistics about its penetration in the market.

Learn faster. Dig deeper. See farther.
The numbers, perhaps studied for the first time looking at actual data, suggest that there is a lot of room for growth left in the big data market. But given that there are so few actual customers at the moment, it also means that there is likely to be a lot of consolidation among big data vendors. In short, the market needs to mature.
Big data in the real world
Our results are based on Spiderbook’s automated analysis of billions of publicly available documents, including all press releases, forums, job postings, blogs, Tweets, patents, and proprietary databases that we have licensed. We use these documents to train our artificial intelligence engine (a graph-based machine learning model), which reads the entire business Internet to find these signals. The result is a remarkably accurate, near-real-time snapshot of the technologies in use at over half a million companies.
What types of trends are we looking for? For instance, we look at the skills held by employees at every company in our analysis to find out who is using various tools and platforms; who is hiring folks with skills in Apache Spark; and which companies employ data scientists, and how many. Focusing on Hadoop, we looked for signs of who in organizations is talking about Hadoop, which organizations are using Hadoop deployments, who is hiring people with Hadoop skills, who is going to local Hadoop meetups, and who is asking technical questions about Hadoop. We even read every presentation, blog, and Tweet made about Hadoop.
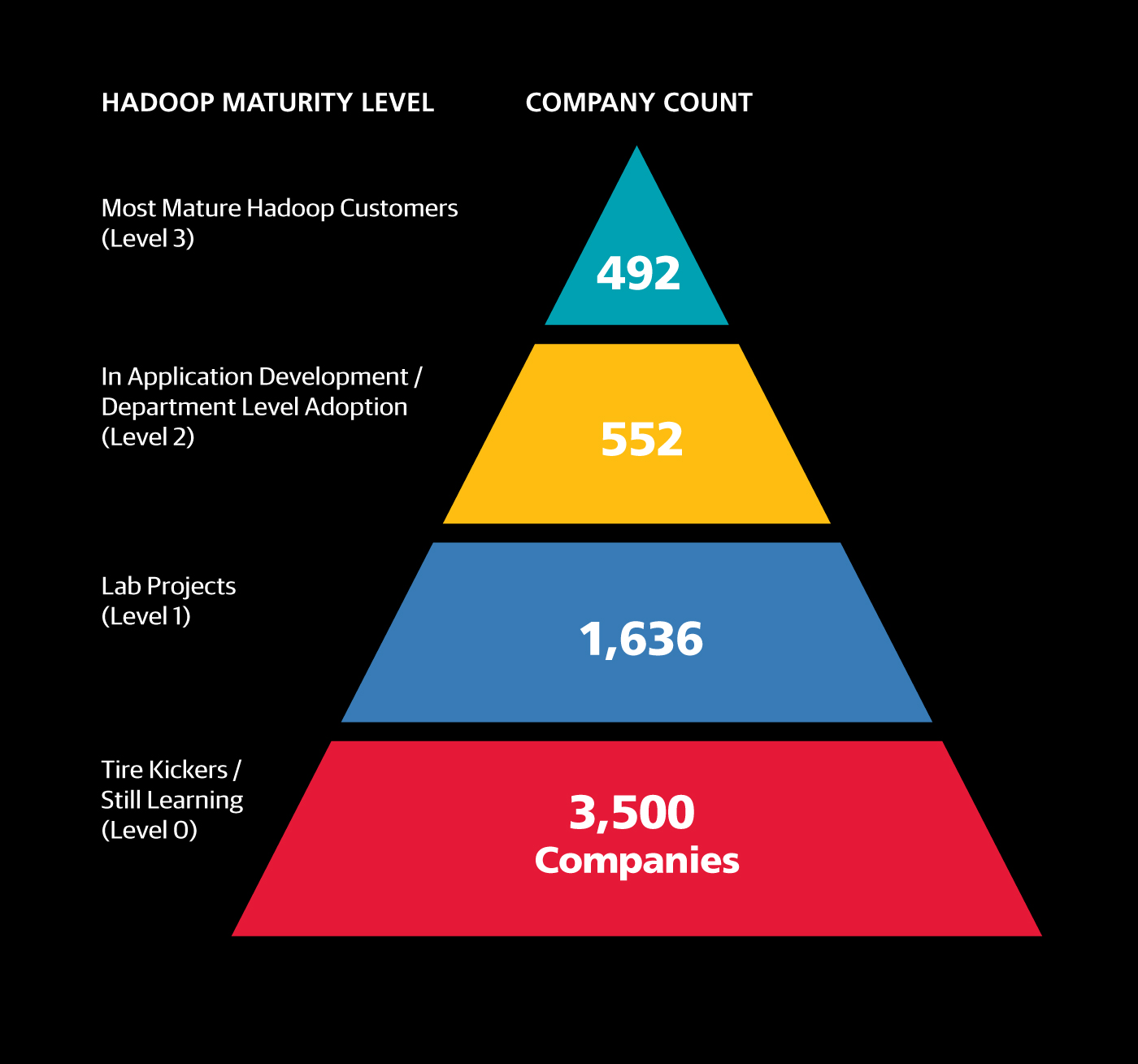
Overall, we found only 2,680 companies that are using Hadoop at any level of maturity. Of those, 1,636 are at the lowest level of big data maturity: they’re just getting started or working on a “lab” project. Another 552 are at the second level, where they’ve been using Hadoop and have a big data project within their company at a small scale (at a department level or within a small startup). And just 492 are at the most advanced level, with evidence of major deployments, production ready pipelines, and experienced Hadoop developers. Level 0 companies are still trying to learn about these technologies, visiting meetups, conferences, and listening to webinars, but not actively working on any big data projects.
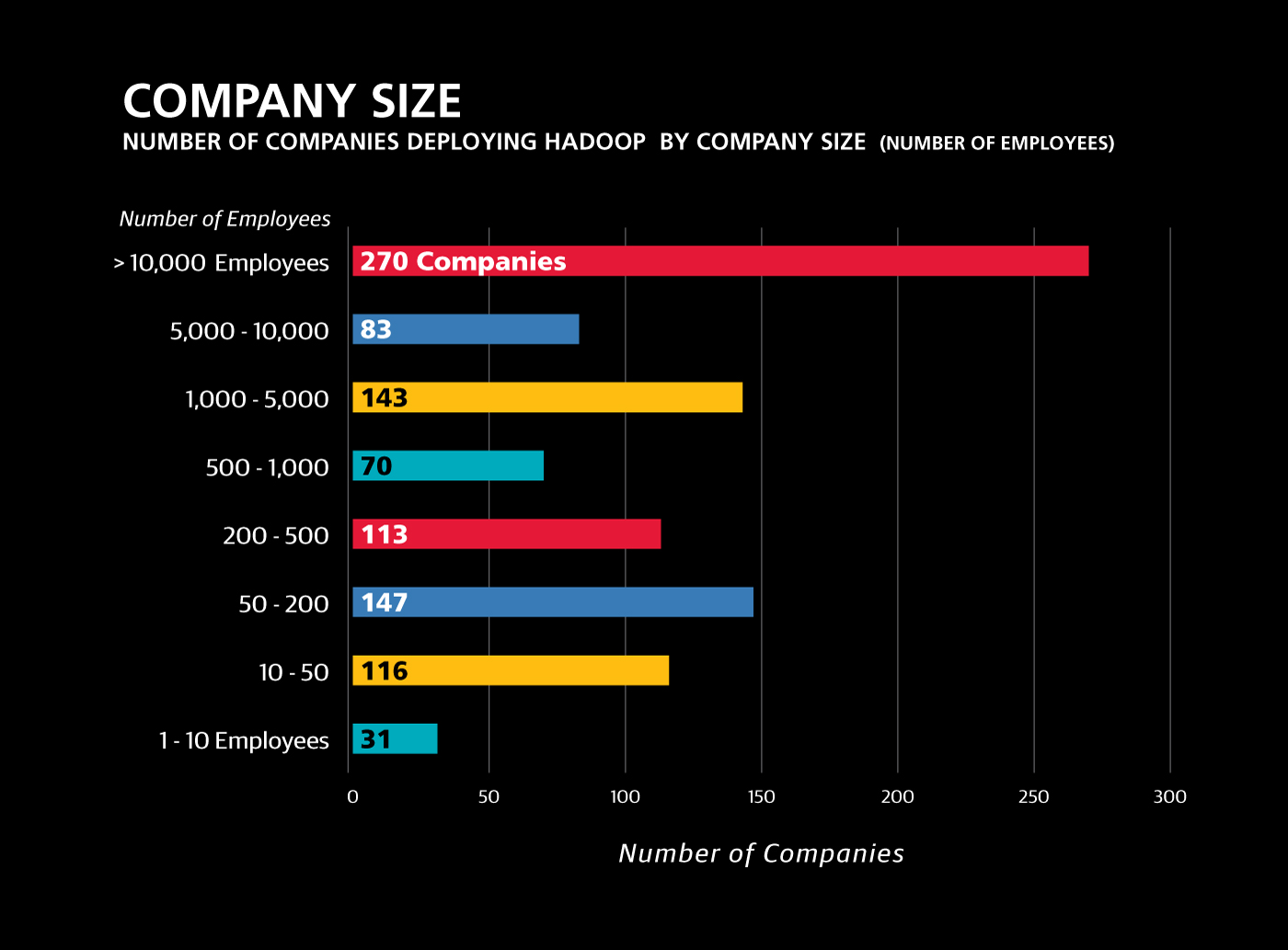
Bigger companies are more into big data
Surprisingly, larger enterprises (those with more than 5,000 employees) are adopting big data technologies much faster than smaller companies. You’d think the smaller, younger companies would be nimbler in embracing new tech, but when it comes to big data, the opposite is the case. We found more than 300 large companies that have made serious investments in Hadoop. By contrast, there are only another 300 companies with less than 5,000 employees who are mature Hadoop users. Since there are 10 times more companies in this group, this means that in smaller companies, Hadoop has less than 1/10 the penetration that it has in the large company set.
Most of the smaller companies adopting Hadoop are high-tech, data-oriented companies themselves. But we don’t know why smaller enterprises are lagging: is it because they can’t afford Hadoop and related technologies, or is it because they cannot pay the high salaries commanded by data scientists and data engineers? Or perhaps they just don’t have as much data?
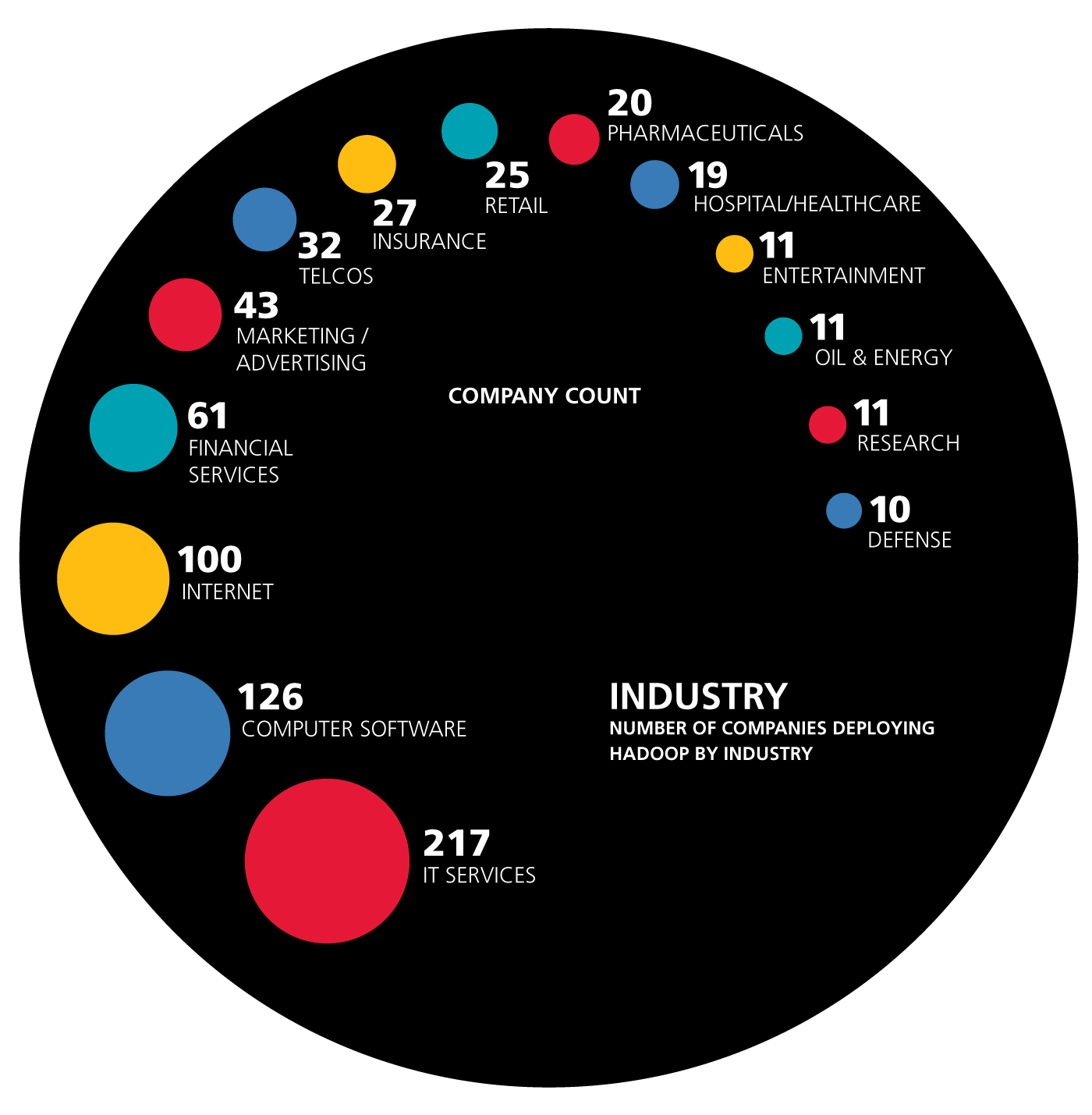
Oil and pharma lag; financial services lead
Oil and gas companies as well as pharmaceutical manufacturers typically have enormous data sets, yet our analysis finds that they are not adopting Hadoop in great numbers. However, financial services companies are—even though this sector is not typically regarded as a fast adopter of new technology. (Many financial companies are still running IBM mainframes.)
Perhaps the financial sector has been influenced by the early lead of companies like American Express. Or, perhaps these companies are migrating directly from mainframes to Hadoop, skipping generations of technologies in between. Startups like Paxata and Syncsort have emerged to help companies do just this.
Real-time needs don’t impede Hadoop
Unexpectedly, industries that benefit from real-time analytics are adopting Hadoop faster than others. These industries include retail, IT security, telecommunications, and advertising. That’s a bit counterintuitive because the original MapReduce paradigm, on which Hadoop is based, is batch-centric and not effective for real-time analytics or transactions. Perhaps to support this need, more real-time Hadoop companies are coming to market, like Datatorrent, VoltDB, and Splice Machine, providing real-time support on top of Hadoop.
Implications for the big data market
Even for companies that are ready to make the plunge into Hadoop, adoption may be thwarted by the lack of available talent. Just today on Indeed.com there are more than 16,000 open jobs that require Hadoop skills in the U.S. alone. Ultimately, for the Hadoop market to mature, the industry needs to be able to utilize talent that hasn’t mastered MapReduce, Impala, Pig, and other technologies built on Hadoop. The talent base that knows standard SQL is 100 times larger than the talent base that knows Hadoop. Solutions like Splice Machine, Presto, IBM Big Data, and Oracle Big Data SQL will prove attractive to enterprises since they have pools of people who have those skills.
But even if the talent gap is addressed, the technology itself is also expensive to deploy and maintain in production. Even using free distribution requires Hadoop administrators who are rare and expensive. While there is a growing ecosystem for backup, recovery, and high-availability technologies for Hadoop, administration of Hadoop is much more sophisticated than administration of SQL databases.
The market today is small(ish) and there is little room for multiple vendors. Our analysis shows that most of the actual spend around big data currently comes from a small set of large customers, thus concentrating money with the vendors who have established positions. Perhaps that is reflected in the recent stock market performance of companies like Hortonworks ($HDP), or MapR’s desire to be more like Splunk than Hortonworks.
As a result, we can expect to see a consolidation of Hadoop vendors. A consolidated vendor who supports not only basic MapReduce but also public cloud deployment pricing models, transactions, in-memory, real-time, and SQL would be more useful to customers than a variety of one-off solutions. Eventually, just as the old relational database model evolved from technology vendors to application vendors, we expect that big data technology vendors will largely be replaced by application vendors who provide big-data-powered solutions for IoT, CRM, supply chain, ERP, and even vertical apps from fraud detection to logistics.
The path forward
So, as you can see, there is still a lot of growth and change to come in the Hadoop market. In order for that growth to take place, our analysis suggests advances in several areas will help: Hadoop penetration into more and more verticals and mid-size companies, growth in talent trained in Hadoop, and increased access to Hadoop for analysts or other SQL users who aren’t familiar with traditional Hadoop tools. Consolidated vendors who provide big data powered applications are likely to come out on top.