There’s nothing magical about learning data science
The top 5 habits of a professional data scientist.
 Fish Magic, 1925. (source: Google Art Project on Wikimedia Commons)
Fish Magic, 1925. (source: Google Art Project on Wikimedia Commons)
There are people who can imagine ways of using data to improve an enterprise. These people can explain the vision, make it real, and affect change in their organizations. They are—or at least strive to be—as comfortable talking to an executive as they are typing and tinkering with code. We sometimes call them “unicorns” because the combination of skills they have are supposedly mystical, magical…and imaginary.
But I don’t think it’s unusual to meet someone who wants their work to have a real impact on real people. Nor do I think there is anything magical about learning data science skills. You can pick up the basics of machine learning in about 15 hours of lectures and videos. You can become reasonably good at most things with about 20 hours (45 minutes a day for a month) of focused, deliberate practice.

Learn faster. Dig deeper. See farther.
So, basically, being a unicorn, or rather a professional data scientist is something that can be taught. Learning all of the related skills is difficult, but straight-forward. With help from the folks at O’Reilly, we’ve designed a tutorial at Strata + Hadoop World New York, 2016, Data Science that Works: Best practices for designing data-driven improvements, making them real, and driving change in your enterprise, for those who aspire to the skills of a unicorn. The premise of the tutorial is that you can follow a direct path toward professional data science, by taking on the following, most distinguishing habits:
5. Put aside the technology stack
The tools and technologies used in data science are often presented as a technology stack. The stack is a problem because it encourages you to to be motivated by technology, rather than business problems. When you focus on a technology stack, you ask questions like “can this tool connect with that tool” or “what hardware do I need to install this product?” These are important concerns, but they aren’t the kinds of things that motivate a professional data scientist.
Professionals in data science tend to think of tools and technologies as part of an insight utility, rather than a technology stack. Focusing on building a utility forces you to select components based on the insights that the utility is meant to generate. With utility thinking, you ask questions like “What do I need to discover an insight?” and “Will this technology get me closer to my business goals?”
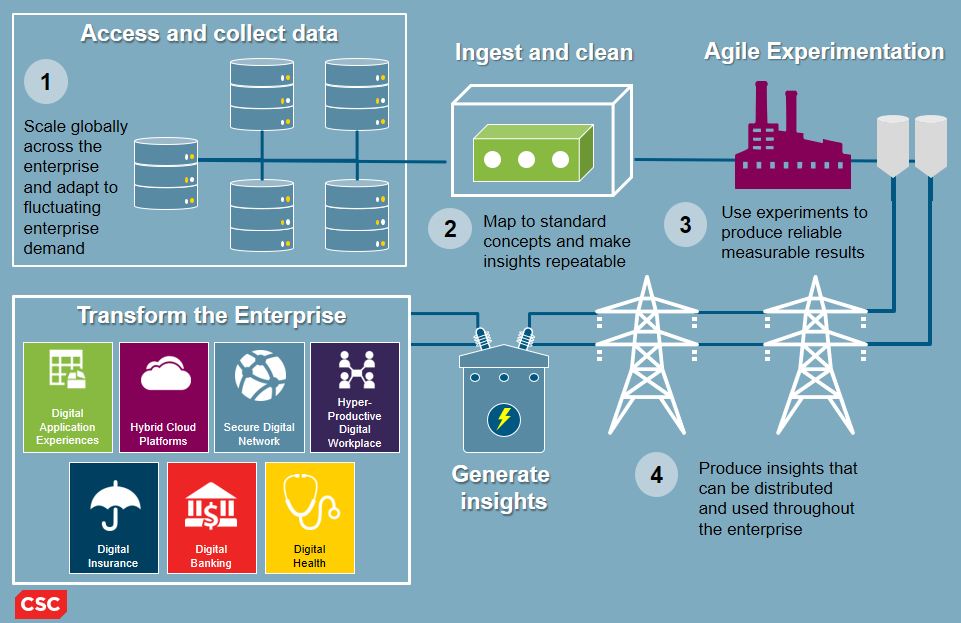
In the Strata + Hadoop World tutorial in New York, I’ll teach simple strategies for shifting from technology-stack thinking to insight-utility thinking.
4. Keep data lying around
Data science stories are often told in the reverse order from which they happen. In a well-written story, the author starts with an important question, walks you through the data gathered to answer the question, describes the experiments run, and presents resulting conclusions. In real data science, the process usually starts when someone looks at data they already have and asks: “hey, I wonder if we could be doing something cool with this?” That question leads to tinkering, which leads to building something useful, which leads to the search for someone who might benefit. Most of the work is devoted to bridging the gap between the insight discovered and the stakeholder’s needs. But when the story is told, the reader is taken on a smooth progression from stakeholder to insight.
The questions you ask are usually the ones where you have access to enough data to answer. Real data science usually requires a healthy stockpile of discretionary data. In the tutorial, I’ll teach techniques for building and using data pipelines to make sure you always have enough data to do something useful.
3. Have a strategy
Data strategy gets confused with data governance. When I think of strategy, I think of chess. To play a game of chess, you have to know the rules. To win a game of chess, you have to have a strategy. Knowing that “the D2 pawn can move to D3 unless there is an obstruction at D3 or the move exposes the king to direct attack” is necessary to play the game, but it doesn’t help me pick a winning move. What I really need are patterns that put me in a better position to win—“If I can get my knight and queen connected in the center of the board, I can force my opponent’s king into a trap in the corner.”
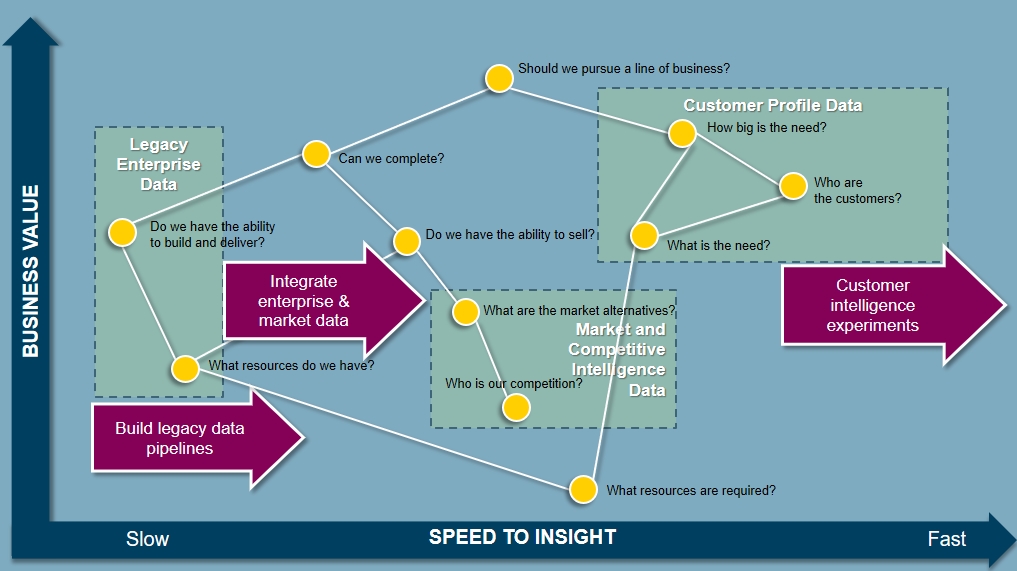
This lesson from chess applies to winning with data. Professional data scientists understand that to win with data, you need a strategy; and to build a strategy, you need a map. In the tutorial, we’ll review ways to build maps from the most important business questions, build data strategies, and execute the strategy using utility thinking.
2. Hack
By hacking, of course, I don’t mean subversive or illicit activities. I mean cobbling together useful solutions. Professional data scientists constantly need to build things quickly. Tools can make you more productive, but tools alone won’t bring your productivity to anywhere near what you’ll need.
To operate on the level of a professional data scientist, you have to master the art of the hack. You need to get good at producing new, minimum-viable, data products based on adaptations of assets you already have. In New York, we’ll walk-through techniques for hacking together data products and building solutions that you understand, and are fit for purpose.
1. Experiment
I don’t mean experimenting as simply trying out different things and seeing what happens. I mean the more formal experimentation prescribed by the scientific method. Remember those experiments you performed, wrote reports about, and presented in grammar-school science class? It’s like that.
Running experiments and evaluating the results is one of the most effective ways of making an impact as data scientist. I’ve found that great stories and great graphics are not enough to convince others to adopt new approaches in the enterprise. The only thing I’ve found to be consistently powerful enough to affect change is a successful example. Few are willing to try new approaches until it has been proven successful. You can’t prove an approach successful unless you get people to try it. The way out of this vicious cycle is to run a series of small experiments.
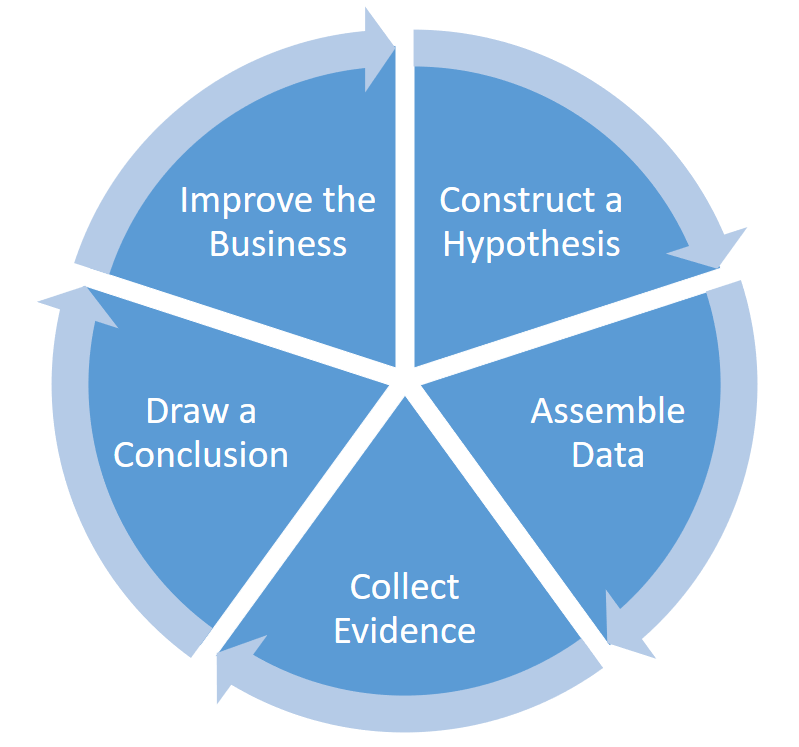
In the tutorial at Strata + Hadoop World New York, we’ll also study techniques for running experiments in very short sprints, which forces us to focus on discovering insights and making improvements to the enterprise in small, meaningful chunks.
We’re at the beginning of a new phase of big data—a phase that has less to do with the technical details of massive data capture and storage, and much more to do with producing impactful scalable insights. Organizations that adapt, and learn to put data to good use, will consistently outperform their peers. There is a great need for people who can imagine data-driven improvements, make them real, and drive change. I have no idea how many people are actually interested in taking on the challenge, but I’m really looking forward to finding out.