

 Gulf Stream Sea Surface Currents and Temperatures (source: NASA / Greg Shirah on Wikimedia Commons)
Gulf Stream Sea Surface Currents and Temperatures (source: NASA / Greg Shirah on Wikimedia Commons) With companies producing data from an increasing number of systems and devices, messaging and event streaming solutions—particularly Apache Kafka—have gained widespread adoption. Over the past year, we’ve been tracking the progress of Apache Pulsar (Pulsar), a less well-known but highly capable open source solution originated by Yahoo. Pulsar is designed to intelligently process, analyze, and deliver data from an expanding array of services and applications, and thus it fits nicely into modern data platforms. Pulsar is also designed to ease the operational burdens normally associated with complex, distributed systems.
Who else is interested in Pulsar? Karthik Ramasamy, CEO of Streamlio, was kind enough to share geo-demographic data of recent visitors to the project’s homepage:
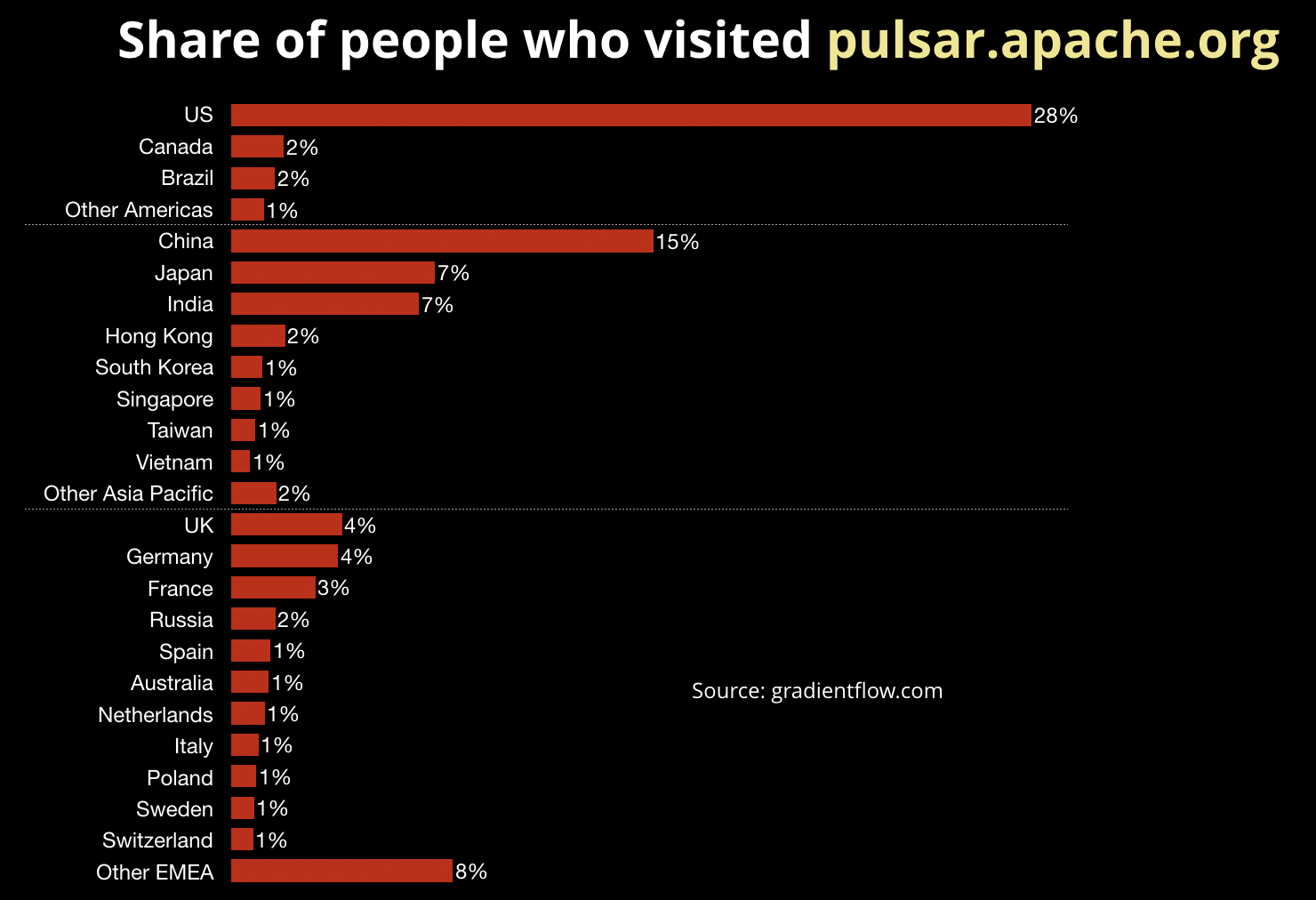
Of the thousands of recent visitors to the site: 33% are from the Americas, 36% from Asia-Pacific, and 27% were based in the EMEA region.
While Apache Kafka is by far the most popular pub/sub solution, over the last year, we’ve started to come across numerous companies that use Pulsar. It turns out that Pulsar has a few features these companies value, including:
- Multi-layer architecture comprised of a serving layer (brokers that coordinate how messages are received, stored, processed, and delivered), a storage layer (Apache BookKeeper nodes are used to persist messages), and a processing layer (via Pulsar functions or Pulsar SQL).
- High performance and scalability: Pulsar has been used at Yahoo for several years to handle 100 billion messages per day on over two million topics. It is able to support millions of topics while delivering high-throughput and low-latency performance.
- Easily add storage or serving without having to rebalance the entire cluster: the multi-layer architecture allows for storage to be added independently of serving. One is also able to make serving and storage layer expansions without any down time.
- Support for popular messaging models including pub/sub messaging and message queuing.
- Multitenancy allows a single Pulsar cluster to support an entire enterprise and lets each team have a separate namespace with its own quotas.
- Durability (no data loss): data is replicated and synced to disk.
- Geo-replication: out-of-box support for geographically distributed applications. Pulsar supports several different modes for replicating the data between clusters.
While previous generation messaging systems focused primarily on moving data, newer frameworks like Pulsar add data processing capabilities essential for feeding data into analytics and AI applications. The rise of connected devices, the introduction of 5G, and the growing importance of machine learning and AI will require that companies build infrastructure for capturing, processing, and moving many data streams. And they will increasingly need to perform these tasks in (near) real time. The good news is that critical components for data management, processing, transport, and orchestration continue to improve and automation technologies should ease operational burdens moving forward.
Related:
- Jesse Anderson: “Reducing Operational Overhead with Pulsar Functions”
- “One simple chart: Who is interested in Spark NLP?”
- “One simple graphic: Researchers love PyTorch and TensorFlow”
- Tyler Akidau: Streaming 101 and Streaming 102
- “Apache Kafka and the four challenges of production machine learning systems”
- Jay Kreps: “Building Apache Kafka from scratch”
- Karthik Ramasamy: “Architecting and building end-to-end streaming applications”
- “What machine learning means for software development”